Chapter: Embedded Systems
Programming Embedded Systems in Assembly And C
EMBEDDED SOFTWARE
PROGRAMMING EMBEDDED SYSTEMS IN
ASSEMBLY AND C
EMBEDDED SOFTWARE
C AND ASSEMBLY
Many
programmers are more comfortable writing in C, and for good reason: C is a
mid-level language (in comparison to Assembly, which is a low-level language),
and spares the programmers some of the details of the actual implementation.
However,
there are some low-level tasks that either can be better implemented in
assembly, or can only be implemented
in assembly language. Also, it is frequently useful for the programmer to look
at the assembly output of the C compiler, and hand-edit, or hand optimize the assembly code in ways
that the compiler cannot. Assembly is also useful for time-critical or
real-time processes, because unlike with high-level languages, there is no
ambiguity about how the code will be compiled. The timing can be strictly
controlled, which is useful for writing simple device drivers. This section
will look at multiple techniques for mixing C and Assembly program development.
INLINE ASSEMBLY
One of
the most common methods for using assembly code fragments in a C programming
project is to use a technique called inline
assembly. Inline assembly is invoked in different compilers in different
ways. Also, the assembly language syntax used in the inline assembly depends
entirely on the assembly engine used by the C compiler. Microsoft C++, for
instance, only accepts inline assembly commands in MASM syntax, while GNU GCC
only accepts inline assembly in GAS syntax (also known as AT&T syntax).
This page will discuss some of the basics of mixed-language programming in some
common compilers.
Microsoft C Compiler
Turbo C Compiler
GNU GCC Compiler
Borland C Compiler
LINKED ASSEMBLY
When an
assembly source file is assembled by an assembler, and a C source file is
compiled by a C compiler, those two object
files can be linked together by a linker
to form the final executable. The beauty of this approach is that the assembly
files can written using any syntax and assembler that the programmer is
comfortable with. Also, if a change needs to be made in the assembly code, all
of that code exists in a separate file, that the programmer can easily access.
The only disadvanges of mixing assembly and C in this way are that a)both the assembler
and the compiler need to be run, and b) those files need to be manually linked
together by the programmer. These extra steps are comparatively easy, although
it does mean that the programmer needs to learn the command-line syntax of the
compiler, the assembler, and the linker.
INLINE ASSEMBLY VS. LINKED ASSEMBLY
ADVANTAGES OF INLINE ASSEMBLY:
Short
assembly routines can be embedded directly in C function in a C code file. The
mixed-language file then can be completely compiled with a single command to
the C compiler (as opposed to compiling the assembly code with an assembler,
compiling the C code with the C Compiler, and then linking them together). This
method is fast and easy. If the in-line assembly is embedded in a function,
then the programmer doesn't need to worry about #Calling_Conventions, even when
changing compiler switches to a different calling convention.
ADVANTAGES OF LINKED ASSEMBLY:
If a new
microprocessor is selected, all the assembly commands are isolated in a
".asm" file. The programmer can update just that one file -- there is
no need to change any of the ".c" files (if they are portably
written).
CALLING CONVENTIONS
When
writing separate C and Assembly modules, and linking them with your linker, it
is important to remember that a number of high-level C constructs are very
precisely defined, and need to be handled correctly by the assembly portions of
your program. Perhaps the biggest obstacle to mixed-language programming is the
issue of function calling conventions. C functions are all implemented
according to a particular convention that is selected by the programmer (if you
have never "selected" a particular calling convention, it's because
your compiler has a default setting). This page will go through some of the
common calling conventions that the programmer might run into, and will
describe how to implement these in assembly language.
Code
compiled with one compiler won't work right when linked to code compiled with a
different calling convention. If the code is in C or another high-level
language (or assembly language embedded in-line to a C function), it's a minor
hassle -- the programmer needs to pick which compiler / optimization switches
she wants to use today, and recompile
every part of the program that way. Converting assembly language code to use a
different calling convention takes more manual effort and is more bug-prone.
Unfortunately,
calling conventions are often different from one compiler to the next -- even
on the same CPU. Occasionally the calling convention changes from one version
of a compiler to the next, or even from the same compiler when given different
"optimization" switches.
Unfortunately,
many times the calling convention used by a particular version of a particular
compiler is inadequately documented. So assembly-language programmers are
forced to use reverse engineering techniques to figure out the exact details
they need to know in order to call functions written in C, and in order to
accept calls from functions written in C.
The
typical process is:
write a
".c" file with stubs ...
details??? ... ... exactly the same number and type of inputs and outputs
that you want the assembly-language function to have.
Compile
that file with the appropriate switches to give a mixed assembly-language-with-c-in-comments
file (typically a ".cod" file). (If your compiler can't produce an
assembly language file, there is the tedious option of disassembling the binary
".obj" machine-code file).
Copy that
".cod" file to a ".asm" file. (Sometimes you need to strip
out the compiled hex numbers and comment out other lines to turn it into
something the assembler can handle).
Test the
calling convention -- compile the ".asm" file to an ".obj"
file, and link it (instead of the stub ".c" file) to the rest of the
program. Test to see that "calls" work properly.
Fill in
your ".asm" file -- the ".asm" file should now include the
appropriate header and footer on each function to properly implement the
calling convention. Comment out the stub code in the middle of the function and
fill out the function with your assembly language implementation.
Test.
Typically a programmer single-steps through each instruction in the new code,
making sure it does what they wanted it to do.
PARAMETER PASSING
Normally,
parameters are passed between functions (either written in C or in Assembly)
via the stack. For example, if a function foo1() calls a function foo2() with 2
parameters (say characters x and y), then before the control jumps to the
starting of foo2(), two bytes (normal size of a character in most of the
systems) are filled with the values that need to be passed. Once control jumps
to the new function foo2(), and you use the values (passed as parameters) in
the function, they are retrieved from the stack and used.
There are
two parameter passing techniques in use,
1. Pass by
Value
2. Pass by
Reference
Parameter
passing techniques can also use
right-to-left
(C-style) left-to-right (Pascal style)
On
processors with lots of registers (such as the ARM and the Sparc), the standard
calling convention puts *all* the parameters (and even the return address) in
registers.
On
processors with inadequate numbers of registers (such as the 80x86 and the
M8C), all calling conventions are forced to put at least some parameters on the
stack or elsewhere in RAM.
Some
calling conventions allow "re-entrant code".
PASS BY VALUE
With
pass-by-value, a copy of the actual value (the literal content) is passed. For
example, if you have a function that accepts two characters like
void
foo(char x, char y){ x = x
+ 1;
y = y +
2; putchar(x); putchar(y);
}
and you
invoke this function as follows
char a,b;
a='A'; b='B';
foo(a,b);
then the
program pushes a copy of the ASCII values of 'A' and 'B' (65 and 66
respectively) onto the stack before the function foo is called. You can see
that there is no mention of variables 'a' or 'b' in the function foo(). So, any
changes that you make to those two values in foo will not affect the values of
a and b in the calling function.
PASS BY REFERENCE
Imagine a
situation where you have to pass a large amount of data to a function and apply
the modifications, done in that function, to the original variables. An example
of such a situation might be a function that converts a string with lower case
alphabets to upper case. It would be an unwise decision to pass the entire
string (particularly if it is a big one) to the function, and when the
conversion is complete, pass the entire result back to the calling function.
Here we pass the address of the variable to the function. This has two
advantages, one, you don't have to pass huge data, therby saving execution time
and two, you can work on the data right away so that by the end of the
function, the data in the calling function is already modified.
But
remember, any change you make to the variable passed by reference will result
in the original variable getting modified. If that's not what you wanted, then
you must manually copy the variable before calling the function.
CDECL
In the
CDECL calling convention the following holds:
Arguments
are passed on the stack in Right-to-Left order, and return values are passed in
eax.
The calling function cleans the stack. This
allows CDECL functions to have variable-length
argument lists (aka variadic functions). For this reason the number of
arguments is not appended to the name
of the function by the compiler, and the assembler and the linker are therefore
unable to determine if an incorrect number of arguments is used.
Variadic
functions usually have special entry code, generated by the va_start(),
va_arg() C pseudo-functions.
Consider
the following C instructions:
_cdecl
int MyFunction1(int a, int b)
{
return a
+ b;
}
and the
following function call:
x =
MyFunction1(2, 3);
These
would produce the following assembly listings, respectively:
:_MyFunction1
push ebp
mov ebp,
esp mov eax, [ebp + 8]
mov edx,
[ebp + 12] add eax, edx
pop ebp
ret
and
push 3
push 2
call
_MyFunction1 add esp, 8
When
translated to assembly code, CDECL functions are almost always prepended with
an underscore (that's why all previous examples have used "_" in the
assembly code).
STDCALL
STDCALL,
also known as "WINAPI" (and a few other names, depending on where you
are reading it) is used almost exclusively by Microsoft as the standard calling
convention for the Win32 API. Since STDCALL is strictly defined by Microsoft,
all compilers that implement it do it the same way.
STDCALL
passes arguments right-to-left, and returns the value in eax. (The Microsoft
documentation erroneously claims that arguments are passed left-to-right, but
this is not the case.)
The
called function cleans the stack, unlike CDECL. This means that STDCALL doesn't
allow variable-length argument lists.
Consider
the following C function:
_stdcall
int MyFunction2(int a, int b)
{
return a
+ b;
}
and the
calling instruction:
x =
MyFunction2(2, 3);
These
will produce the following respective assembly code fragments:
:_MyFunction@8
push ebp
mov ebp,
esp mov eax, [ebp + 8]
mov edx,
[ebp + 12] add eax, edx
pop ebp
ret 8
and
push 3
push 2
call
_MyFunction@8
There are
a few important points to note here:
1. In the
function body, the ret instruction
has an (optional) argument that indicates how many bytes to pop off the stack
when the function returns.
2. STDCALL
functions are name-decorated with a leading underscore, followed by an @, and
then the number (in bytes) of arguments passed on the stack. This number will
always be a multiple of 4, on a 32-bit aligned machine.
FASTCALL
The
FASTCALL calling convention is not completely standard across all compilers, so
it should be used with caution. In FASTCALL, the first 2 or 3 32-bit (or
smaller) arguments are passed in registers, with the most commonly used
registers being edx, eax, and ecx. Additional arguments, or arguments larger than
4-bytes are passed on the stack, often in Right-to-Left order (similar to
CDECL). The calling function most frequently is responsible for cleaning the
stack, if needed.
Because
of the ambiguities, it is recommended that FASTCALL be used only in situations
with 1, 2, or 3 32-bit arguments, where speed is essential.
The
following C function:
_fastcall
int MyFunction3(int a, int b)
{
return a
+ b;
}
and the
following C function call:
x =
MyFunction3(2, 3);
Will
produce the following assembly code fragments for the called, and the calling
functions, respectively:
:@MyFunction3@8
push ebp
mov ebp,
esp ;many compilers create a stack frame even if it isn't used add eax, edx ;a
is in eax, b is in edx
pop ebp
ret
and
;the
calling function mov eax, 2
mov edx,
3
call
@MyFunction3@8
The name
decoration for FASTCALL prepends an @ to the function name, and follows the
function name with @x, where x is the number (in bytes) of arguments passed to
the function.
Many
compilers still produce a stack frame for FASTCALL functions, especially in
situations where the FASTCALL function itself calls another subroutine.
However, if a FASTCALL function doesn't need a stack frame, optimizing
compilers are free to omit it.
MEETING REAL TIME CONSTRAINTS
CPS must
meet real-time constraints
•
A real-time system must react to stimuli from the
controlled object (or the operator) within the time interval dictated by the environment.
•
For real-time systems, right answers arriving too
late are wrong.
•
“A
real-time constraint is called hard, if not meeting that constraint could
result in a catastrophe“ [Kopetz, 1997].
•
All other time-constraints are called soft.
•
A guaranteed system response has to be explained
without statistical arguments
CPS, ES
and Real-Time Systems synonymous?
§ For some
embedded systems, real-time behavior is less important (smart phones)
§ For CPS,
real-time behavior is essential, hence RTS
CPS
§ CPS
models also include a model of the physical system
§ ES
models typically just model IT components CPS model (ES-) IT components model +
physical model
§ Typically, CPS are reactive systems: “A
reactive system is one which is in continual interaction with is environment
and executes at a pace determined by that environment“ [Bergé, 1995] Dedicated
towards a certain application Knowledge about behavior at design time can be
used to minimize resources and to maximize robustness
§ Dedicateduserinterface
(no
mouse, keyboard and screen)
Situation
is slowly changing here: systems become less dedicated
Characteristics a nd Challenges
of RTS
Real-time syste ms are computing
systems in which the m eeting of timing constraints is essential to
correctness.
If the system d elivers the correct answer,
but after a cert ain deadline, it could be regarded as having failed.
Types of Real-Time Systems
Hard real-time system
A system
where “something very bad” happens if the deadline is not met.
Examples:
co ntrol systems for aircraft, nucluear reactors, chemical power plants, jet
engines, etc.
Soft real-time system
A system
where the performance is degraded below what is generally considered acceptable
if the d eadline is missed.
Example:
multimedia system
UTILITY FUNCTION (TASK VALUE FUNCTION)
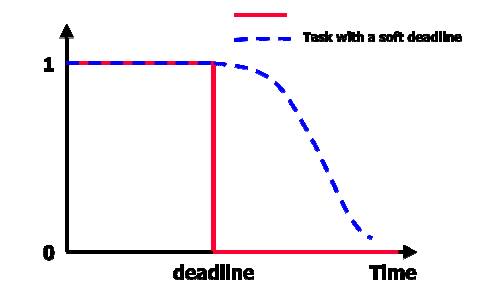
ISSUES IN REAL-TIME COMMPUTING
Real-time compu ting deals with
all problems in computer arc hitecture, fault-tolerant computing and operating
systems are also problems in real-time
computing, wit h the added
complexity of having to meet real-time constraints
Real-time compu ter systems
differ from general-purpose systems
They are
more specific in their applications
The
consequence s of their failure are more drastic Emphasis is placed on meeting task deadlines
Example Problems
Example 1: Task Scheduling
General-purpose
system can use round-robin scheduling
This is
NOT suitable for real-time systems because high-priority tasks may miss their
deadlines with round-robin scheduling
A priority mechanism is necessary
Example 2: Cache Usage Scheduling
A
general-purpose system typically allows the process that is currently executing
the right to use the entire cache area
This
keeps the cache miss rate low
Side
effect: task run times are less predictable
– Thus, not so desirable for real-time systems
Real-time systems can be
constructed [out] of sequential programs, but typically they are built [out] of
concurrent programs, called tasks.
Tasks are usually divided into:
Periodic
tasks: consist of an infinite sequence of identical activities, called instances, which are invoked within
regular time periods.
Non-periodic
[or aperiodic] : are invoked by the occurrence of an event. [Sporadic :
aperiodic tasks with a bounded interarrival time]
SCHEDULING
Offline scheduling:
The
scheduler has complete knowledge of the task set and its constraints.
Online scheduling:
Make
their scheduling decisions during run-time.
Deadline:
Is the
maximum time within which the task must complete its execution with respect to
an event.
Real-time
systems are divided into two classes, hard
and soft real-time systems
SCHEDULABILITY ANALYSIS
At this
point we must check that the temporal requirements of the system can be
satisfied, assuming time budgets assigned in the detailed design stage.
In other
words, we need to make a schedulability analysis of the system based on the
temporal requirements of each component
REAL TIME OPERATING SYSTEMS
Multi-tasking
OS designed to permit tasks (processes) to complete within precisely stated
deadlines
If
deadline constraints cannot be met for a new task, it may be rejected
If a new
task would result in deadline violations for other tasks, it may be rejected
Example commercial operating
systems
Vrtx –
Mentor Graphics Systems VxWorks and pSOS – Wind River Systems
RTLinux –
FSMLabs, later acquired by Wind River Systems
MULTI-STATE SYSTEMS AND FUNCTION SEQUENCES
Definition: A system that can exist in
multiple states (one state at a time) and transition from one state to another
Characteristics
A series
of system states
Each
state requires one or more functions
Rules
exist to determine when to transition from one state to another
Typical Solution
Every
time tick, the system should check if it is time to transition to the next
state
When it
is time to transition, appropriate control variables are updated to reflect the
new state Categories
Timed Multi-state
systems: Transitions depend only on time Input-based multi-state system:
Transitions
depend only on external input
Not
commonly used due to danger of indefinite wait Input-based/Timed Multi-state
systems: Transitions depend both on external input and time
Example Timed System:
Traffic Light
States:
Red
Red-Amber
Green
Amber
Time Constants
#define
RED_DURATION 20
#define
RED_AND_AMBER_DURATION 5 #define GREEN_DURATION 30
§ #define
AMBER_DURATION 5
State
Update Code switch (Light_state_G)
{
case RED:
{
Red_light
= ON; Amber_light = OFF; Green_light = OFF;
if
(++Time_in_state == RED_DURATION)
{
Light_state_G
= RED_AND_AMBER; Time_in_state = 0;
}
break;
§ }
Example
Timed System:
Robotic
Dinosaur
§ States:
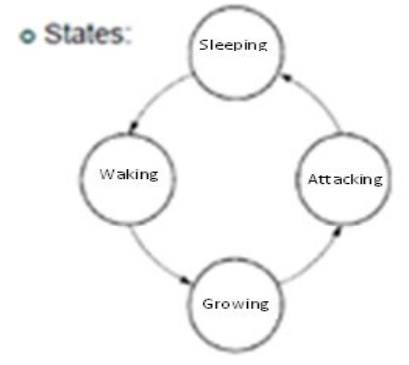
Input/Timed Systems
Two or
more states
Each
state associated with one or more function calls
Transition
between states controlled by a combination of time and user input
Solution Characteristics
System
keeps track of time
If a
certain user input is detected, a state transition occurs
If no
input occurs for a pre-determined period, a state transition occurs
Related Topics