Chapter: Embedded Systems Design : Embedded processors
Data processors: Complex instructions, microcode and nanocode
Data processors
Processors like the 8080 and the MC6800 provided the computing power for
many early desktop computers and their successors have continued to power the
desktop PC. As a result, it should not be surprising that they have also
provided the processing power for more powerful systems where a microcontroller
cannot provide either the processing power or the correct number or type of
peripherals. They have also provided the processor cores for more integrated
chips which form the next category of embedded systems.
Complex instructions, microcode and nanocode
With the initial development of the microprocessor concen-trated on the
8 bit model, it was becoming clear that larger data sizes, address space and
more complex instructions were needed. The larger data size was needed to help
support higher precision arithmetic. The increased address space was needed to
support bigger blocks of memory for larger programs. The complex in-struction
was needed to help reduce the amount of memory required to store the program by
increasing the instruction effi-ciency: the more complex the instruction, the
less needed for a particular function and therefore the less memory that the
system needed. It should be remembered that it was not until recently that
memory has become so cheap.
The instruction format consists of an op code followed by a source
effective address and a destination effective address. To provide sufficient
coding bits, the op code is 16 bits in size with further 16 bit operand
extensions for offsets and absolute ad-dresses. Internally, the instruction
does not operate directly on the internal resources, but is decoded to a
sequence of microcode instructions, which in turn calls a sequence of nanocode
com-mands which controls the sequencers and arithmetic logic units (ALU). This
is analogous to the many macro subroutines used by assembler programmers to
provide higher level ‘pseudo’ instruc-tions. On the MC68000, microcoding and
nanocoding allow in-structions to share common lower level routines, thus
reducing the hardware needed and allowing full testing and emulation prior to
fabrication. Neither the microcode nor the nanocode sequences are available to
the programmer.
These sequences, together with the sophisticated address calculations
necessary for some modes, often take more clock cycles than are consumed in
fetching instructions and their asso-ciated operands from external memory. This
multi-level decoding automatically lends itself to a pipelined approach which
also allows a prefetch mechanism to be employed.
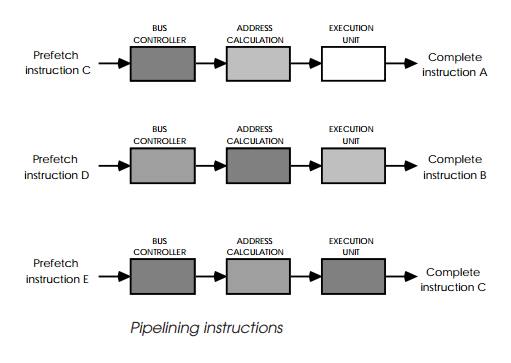
Pipelining works by splitting the instruction fetch, decode and
execution into independent stages: as an instruction goes through each stage,
the next instruction follows it without waiting for it to completely finish. If
the instruction fetch is included within the pipeline, the next instruction can
be read from memory, while the preceding instruction is still being executed as
shown.
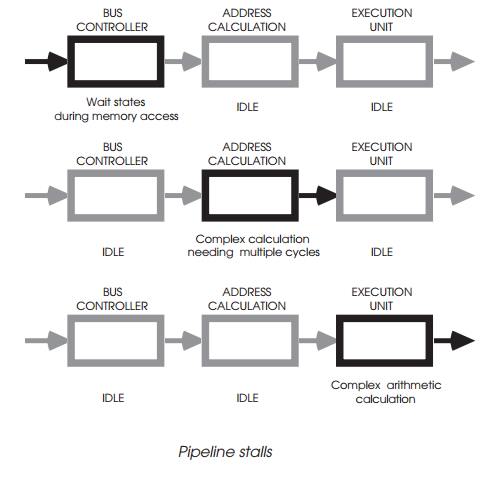
The only disadvantage with pipelining concerns pipeline stalls. These
are caused when any stage within the pipeline cannot complete its allotted task
at the same time as its peers. This can occur when wait states are inserted
into external memory accesses, instructions use iterative techniques or there
is a change in pro-gram flow.
With iterative delays, commonly used in multiply and divide instructions
and complex address calculations, the only possible solutions are to provide
additional hardware support, add more stages to the pipeline, or simply suffer
the delays on the grounds that the performance is still better than anything else!
Additional hardware support may or may not be within a design-er‘s real estate
budget (real estate refers to the silicon die area, and directly to the number
of transistors available). Adding stages also consumes real estate and
increases pipeline stall delays when branching. This concern becomes less of an
issue with the current very small gate sizes that are available but the problem
of pipeline stalls and delays is still a major issue. It is true to say that
pipeline lengths have increased to gain higher speeds by reducing the amount of
work done in each stage. However, this has been coupled with an expansion in
the hardware needed to overcome some of the disadvantages. These trade-offs are
as relevant today as they were five or ten years ago.
The main culprits are program branching and similar op-erations. The
problem is caused by the decision whether to take the branch or not being
reached late in the pipeline, i.e. after the next instruction has been
prefetched. If the branch is not taken, this instruction is valid and execution
can carry on. If the branch is taken, the instruction is not valid and the
whole pipeline must be flushed and reloaded. This causes additional memory
cycles before the processor can continue. The delay is dependent on the number
of stages, hence the potential difficulty in increasing the number of stages to
reduce iterative delays. This interrelation of engineering trade-offs is a
common theme within microprocessor architectures. Similar problems can occur for
any change of flow: they are not limited to just branch instructions and can
occur with interrupts, jumps, software interrupts etc. With the large usage of
these types of instructions, it is essential to minimise these delays. The
longer the pipeline, the greater the potential delay.
The next question was over how to migrate from the exist-ing 8 bit
architectures. Two approaches were used: Intel chose the compatibility route
and simply extended the 8080 programming model, while Motorola chose to develop
a different architecture altogether which would carry it into the 32 bit
processor world.
Related Topics