Chapter: Embedded Systems
Interrupts in Embedded Systems
INTERRUPTS
Basics
Busy-wait
I/O is extremely inefficient—the CPU does nothing but test the device status
while the I/O transaction is in progress. In many cases, the CPU could do
useful work in parallel with the I/O transaction, such as:
■ computation,
as in determining the next output to send to the device or processing the last
input received, and
■
control of other I/O devices.
To allow
parallelism, we need to introduce new mechanisms into the CPU.
The interrupt
mechanism allows devices to signal the CPU and to force execution of a
particular piece of code. When an interrupt occurs, the program counter’value
is changed to point to an interrupt handler routine (also
commonly known as a device driver ) that takes care of the device: writing the next
data, reading data that have just become ready, and so on. The interrupt
mechanism of course saves the value of the PC at the interruption so that the
CPU can return to the program that was interrupted. Interrupts therefore allow
the flow of control in the CPU to change easily between different contexts,
such as a foreground computation and multiple I/O devices.
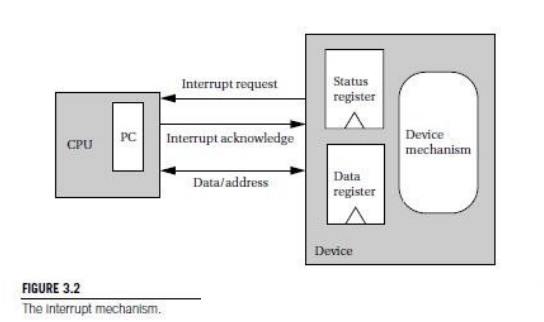
As shown in Figure, the interface between the CPU
and I/O device includes the following signals for interrupting:
■ the I/O
device asserts the interrupt request signal when it wants service from the CPU;
and
■ the CPU
asserts the interrupt acknowledge signal when it is ready to handle the I/O
device’s request.
The I/O
device’s logic decides when to interrupt; for example, it may generate an
interrupt when its status register goes into the ready state. The CPU may not
be able to immediately service an interrupt request because it may be doing
something else that must be finished first—for example, a program that talks to
both a high-speed disk drive and a low-speed keyboard should be designed to
finish a disk transaction before handling a keyboard interrupt. Only when the
CPU decides to acknowledge the interrupt does the CPU change the program
counter to point to the device’s handler. The interrupt handler operates much
like a subroutine, except that it is not called by the executing program. The
program that runs when no interrupt is being handled is often called the foreground
program; when the interrupt handler finishes, it returns to the
foreground program, wherever processing was interrupted.
Before
considering the details of how interrupts are implemented, let’s look at the
interrupt style of processing and compare it to busy-wait I/O. Example 3.4 uses
interrupts as a basic replacement for busy-wait I/O; Example 3.5 takes a more
sophisticated approach that allows more processing to happen concurrently.
Example
Copying
characters from input to output with basic interrupts
As with
Example 3.3, we repeatedly read a character from an input device and write it
to an output device. We assume that we can write C functions that act as
interrupt handlers. Those handlers will work with the devices in much the same
way as in busy-wait I/O by reading and writing status and data registers. The
main difference is in handling the output— the interrupt signals that the character
is done, so the handler does not have to do anything.
We will
use a global variable achar for the input handler to pass the character to the
foreground program. Because the foreground program doesn’t know when an
interrupt occurs, we also use a global Boolean variable, gotchar, to signal
when a new character has been received. The code for the input and output
handlers follows:
void
input_handler() { /* get a character and put in global */ achar =
peek(IN_DATA); /* get character */ gotchar = TRUE; /*
signal to
main program */
poke(IN_STATUS,0);
/* reset status to initiate next
transfer
*/
}
void
output_handler() { /* react to character being sent */
/* don't
have to do anything */
}
The main program is reminiscent of the busy-wait
program. It looks at gotchar to check when a new character has been read and
then immediately sends it out to the output device.
main() {
while
(TRUE) { /* read then write forever */
if
(gotchar) { /* write a character */ poke(OUT_DATA,achar); /* put character
in device
*/
poke(OUT_STATUS,1);
/* set status to
initiate
write */
gotchar =
FALSE; /* reset flag */
}
}
}
The use
of interrupts has made the main program somewhat simpler. But this program
design still does not let the foreground program do useful work. Example uses a
more sophisticated program design to let the foreground program work completely
independently of input and output.
Example
Copying
characters from input to output with interrupts and buffers
Because
we do not need to wait for each character, we can make this I/O program more
sophisticated than the one in Example 3.4. Rather than reading a single
character and then writing it, the program performs reads and writes
independently. The read and write routines communicate through the following
global variables:
■
A character string io_buf will hold a queue of
characters that have been read but not yet written.
■
A pair of integers buf_start and buf_end will point
to the first and last characters
read.
■ An integer
error will be set to 0 whenever io_buf overflows.
The
global variables allow the input and output devices to run at different rates.
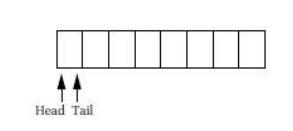
The queue io_buf acts as a wraparound buffer—we add characters to the tail when
an input is received and take characters from the tail when we are ready for
output. The head and tail wrap around the end of the buffer array to make most
efficient use of the array. Here is the situation at the start of the program’s
execution, where the tail points to the first available character and the head
points to the ready character. As seen below, because the head and tail are
equal, we know that the queue is empty.
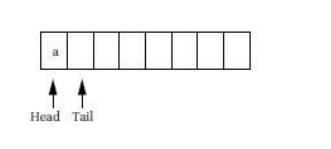
When the
first character is read, the tail is incremented after the character is added
to the queue, leaving the buffer and pointers looking like the following:
When the
buffer is full, we leave one character in the buffer unused. As the next figure
shows, if we added another character and updated the tail buffer (wrapping it
around to the head of the buffer), we would be unable to distinguish a full
buffer from an empty one.

Here is
what happens when the output goes past the end of io_buf:
The
following code provides the declarations for the above global variables and
some service routines for adding and removing characters from the queue.
Because interrupt handlers are regular code, we can use subroutines to
structure code just as with any program.
#define
BUF_SIZE 8
char
io_buf[BUF_SIZE]; /* character buffer */
int
buf_head = 0, buf_tail = 0; /* current position in buffer */
int error
= 0; /* set to 1 if buffer ever overflows */
void
empty_buffer() { /* returns TRUE if buffer is empty */ buf_head == buf_tail;
}
void full_buffer() { /* returns TRUE if buffer is
full */
(buf_tail+1)
% BUF_SIZE == buf_head ;
}
int nchars() { /* returns the number of characters in the buffer */
if (buf_head >= buf_tail) return buf_tail – buf_head;
else
return BUF_SIZE + buf_tail – buf_head;
}
Void add_char(char achar) { /* add a Character to the buffer
head */
io_buf[buf_tail++]
= achar; /* check
pointer
*/
if
(buf_tail == BUF_SIZE)
buf_tail
= 0;
}
char
remove_char() { /* take a character from the buffer head*/
char
achar;
achar =
io_buf[buf_head++];
/* check
pointer */
if
(buf_head == BUF_SIZE)
buf_head
= 0;
}
Assume
that we have two interrupt handling routines defined in C, input_handler for
the input device and output_handler for the output device. These routines work
with the device in much the same way as did the busy-wait routines. The only
complication is in starting the output device: If io_buf has characters
waiting, the output driver can start a new output transaction by itself. But if
there are no characters waiting, an outside agent must start a new output
action whenever the new character arrives. Rather than force the foreground
program
to look at the character buffer, we will have the input handler check to see
whether there is only one character in the buffer and start a new transaction.
Here is
the code for the input handler:
#define
IN_DATA 0x1000 #define IN_STATUS 0x1001
void
input_handler() {
char
achar;
if
(full_buffer()) /* error */
error =
1;
else { /*
read the character and update pointer */
achar = peek(IN_DATA);
/* read character */
add_char(achar);
/* add to queue */
}
poke(IN_STATUS,0);
/* set status register back to 0 */
/* if
buffer was empty, start a new output
transaction
*/
if
(nchars() == 1) { /* buffer had been empty until
this
interrupt */ poke(OUT_DATA,remove_char()); /* send
character
*/
poke(OUT_STATUS,1);
/* turn device on */
}
}
#define
OUT_DATA 0x1100
void
output_handler() {
if
(!empty_buffer()) { /* start a new character */
poke(OUT_DATA,remove_char());
/* send character */
poke(OUT_STATUS,1);
/* turn device on */
}
}
The
foreground program does not need to do anything—everything is taken care of by
the interrupt handlers. The foreground program is free to do useful work as it
is occasionally interrupted by input and output operations. The following
sample execution of the program in the form of a UML sequence diagram shows how
input and output are interleaved with the foreground program. (We have kept the
last input character in the queue until output is complete to make it clearer
when input occurs.) The simulation shows that the foreground program is not
executing continuously, but it continues to run in its regular state
independent of the number of characters waiting in the queue.
Interrupts
allow a lot of concurrency, which can make very efficient use of the CPU. But
when the interrupt handlers are buggy, the errors can be very hard to find. The
fact that an interrupt can occur at any time means that the same bug can
manifest itself in different ways when the interrupt handler interrupts
different segments of the foreground program. Example 3.6 illustrates the
problems inherent in debugging interrupt handlers.
Example
Debugging
interrupt code
Assume
that the foreground code is performing a matrix multiplication operation y Ax b:
for (i =
0; i < M; i++) { y[i] = b[i];
for (j =
0; j < N; j++)
y[i] =
y[i] + A[i,j]*x[j];
}
We use
the interrupt handlers of Example 3.5 to perform I/O while the matrix compu-
tation is performed, but with one small change: read_handler has a bug that
causes it to change the value of j . While this may seem far-fetched, remember
that when the interrupt handler is written in assembly language such bugs are
easy to introduce. Any CPU register that is written by the interrupt handler
must be saved before it is modified And restored before the handler exits. Any
type of bug—such as forgetting to save the register or to properly restore
it—can cause that register to mysteriously change value in the foreground
program.
What
happens to the foreground program when j changes value during an interrupt
depends on when the interrupt handler executes. Because the value of j is reset
at each iteration of the outer loop, the bug will affect only one entry of the
result y . But clearly the entry that changes will depend on when the interrupt
occurs. Furthermore, the change observed in y depends on not only what new
value is assigned to j (which may depend on the data handled by the interrupt
code), but also when in the inner loop the interrupt occurs. An inter- rupt at
the beginning of the inner loop will give a different result than one that
occurs near the end. The number of possible new values for the result vector is
much too large to consider manually—the bug cannot be found by enumerating the
possible wrong values and correlat- ing them with a given root cause. Even
recognizing the error can be difficult—for example, an interrupt that occurs at
the very end of the inner loop will not cause any change in the foreground
program’s result. Finding such bugs generally requires a great deal of tedious
.
Priorities and vectors
Providing
a practical interrupt system requires having more than a simple interrupt
request line. Most systems have more than one I/O device, so there must be some
mechanism for allowing multiple devices to interrupt. We also want to have
flexibil- ity in the locations of the interrupt handling routines, the
addresses for devices, and so on. There are two ways in which interrupts can be
generalized to handle mul- tiple devices and to provide more flexible
definitions for the associated hardware and software:
■
interrupt priorities allow the
CPU to recognize some interrupts as more important than others, and
■
interrupt vectors allow the
interrupting device to specify its handler. Prioritized interrupts not only
allow multiple devices to be connected to the interrupt line but also allow the
CPU to ignore less important interrupt requests
while it
handles more important requests. As shown in Figure 3.3, the CPU pro-vides
several different interrupt request signals, shown here as L1, L2, up to Ln. Typically, the lower-numbered
interrupt lines are given higher priority, so in this case, if devices 1, 2,
and n all requested interrupts
simultaneously, 1’s request would be acknowledged because it is connected to
the highest-priority interrupt line. Rather than provide a separate interrupt
acknowledge line for each device, most CPUs use a set of signals that provide
the priority number of the winning interrupt in binary form (so that interrupt
level 7 requires 3 bits rather than 7). A device knows that its interrupt
request was accepted by seeing its own priority number on the interrupt
acknowledge lines.
Related Topics