Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Virtual Machines and Virtualization of Clusters and Data Centers
Virtualization for Data-Center Automation
VIRTUALIZATION FOR DATA-CENTER AUTOMATION
Data centers have grown
rapidly in recent years, and all major IT companies are pouring their resources
into building new data centers. In addition, Google, Yahoo!, Amazon, Microsoft,
HP, Apple, and IBM are all in the game. All these companies have invested
billions of dollars in data-center construction and automation. Data-center
automation means that huge volumes of hardware, software, and database
resources in these data centers can be allocated dynamically to millions of
Internet users simultaneously, with guaranteed QoS and cost-effectiveness.
This
automation process is triggered by the growth of virtualization products and
cloud com-puting services. From 2006 to 2011, according to an IDC 2007 report
on the growth of virtuali-zation and its market distribution in major IT
sectors. In 2006, virtualization has a market share of $1,044 million in
business and enterprise opportunities. The majority was dominated by
pro-duction consolidation and software development. Virtualization is moving
towards enhancing mobility, reducing planned downtime (for maintenance), and
increasing the number of virtual clients.
The
latest virtualization development highlights high availability (HA), backup services, workload balancing, and
further increases in client bases. IDC projected that automation, service
orientation, policy-based, and variable costs in the virtualization market. The
total business opportunities may increase to $3.2 billion by 2011. The major
market share moves to the areas of HA, utility computing, production consolidation,
and client bases. In what follows, we will discuss server consolidation,
virtual storage, OS support, and trust management in automated data-center
designs.
1. Server Consolidation in Data
Centers
In data centers, a large
number of heterogeneous workloads can run on servers at various times. These
heterogeneous workloads can be roughly divided into two categories: chatty
workloads and noninter-active workloads. Chatty workloads may burst at some
point and return to a silent state at some other point. A web video service is
an example of this, whereby a lot of people use it at night and few peo-ple use
it during the day. Noninteractive workloads do not require people’s efforts to make progress after they are
submitted. High-performance computing is a typical example of this. At various
stages, the requirements for resources of these workloads are dramatically
different. However, to guarantee that a workload will always be able to cope
with all demand levels, the workload is statically allo-cated enough resources
so that peak demand is satisfied.
Therefore,
it is common that most servers in data centers are underutilized. A large
amount of hardware, space, power, and management cost of these servers is
wasted. Server consolidation is an approach to improve the low utility ratio of
hardware resources by reducing the number of physical servers. Among several
server consolidation techniques such as centralized and physical
consolida-tion, virtualization-based server consolidation is the most powerful.
Data centers need to optimize their resource management. Yet these techniques
are performed with the granularity of a full server machine, which makes
resource management far from well optimized. Server virtualization enables
smaller resource allocation than a physical machine.
In
general, the use of VMs increases resource management complexity. This causes a
challenge in terms of how to improve resource utilization as well as guarantee
QoS in data centers. In detail, server virtualization has the following side
effects:
• Consolidation enhances
hardware utilization. Many underutilized servers are consolidated into fewer
servers to enhance resource utilization. Consolidation also facilitates backup
services and disaster recovery.
• This approach enables more agile
provisioning and deployment of resources. In a virtual environment, the images
of the guest OSes and their applications are readily cloned and reused.
• The total cost of ownership
is reduced. In this sense, server virtualization causes deferred purchases of
new servers, a smaller data-center footprint, lower maintenance costs, and
lower power, cooling, and cabling requirements.
• This approach improves
availability and business continuity. The crash of a guest OS has no effect on
the host OS or any other guest OS. It becomes easier to transfer a VM from one
server to another, because virtual servers are unaware of the underlying
hardware.
To
automate data-center operations, one must consider resource scheduling,
architectural support, power management, automatic or autonomic resource
management, performance of analytical mod-els, and so on. In virtualized data
centers, an efficient, on-demand, fine-grained scheduler is one of the key
factors to improve resource utilization. Scheduling and reallocations can be
done in a wide range of levels in a set of data centers. The levels match at
least at the VM level, server level, and data-center level. Ideally, scheduling
and resource reallocations should be done at all levels. However, due to the
complexity of this, current techniques only focus on a single level or, at
most, two levels.
Dynamic
CPU allocation is based on VM utilization and application-level QoS metrics.
One method considers both CPU and memory flowing as well as automatically
adjusting resource over-head based on varying workloads in hosted services.
Another scheme uses a two-level resource management system to handle the
complexity involved. A local controller at the VM level and a global controller
at the server level are designed. They implement autonomic resource allocation
via the interaction of the local and global controllers. Multicore and
virtualization are two cutting tech-niques that can enhance each other.
However, the use of CMP is
far from well optimized. The memory system of CMP is a typical example. One can
design a virtual hierarchy on a CMP in data centers. One can consider protocols
that minimize the memory access time, inter-VM interferences, facilitating VM
reassignment, and supporting inter-VM sharing. One can also consider a VM-aware
power budgeting scheme using multiple managers integrated to achieve better
power management. The power budgeting policies cannot ignore the heterogeneity
problems. Consequently, one must address the trade-off of power saving and
data-center performance.
2. Virtual Storage Management
The term “storage virtualization” was widely used before the renaissance of system virtualization.
Yet the term has a different meaning in a system virtualization environment.
Previously, storage virtualiza-tion was largely used to describe the
aggregation and repartitioning of disks at very coarse time scales for use by
physical machines. In system virtualization, virtual storage includes the
storage managed by VMMs and guest OSes. Generally, the data stored in this
environment can be classified into two categories: VM images and application
data. The VM images are special to the virtual environment, while application
data includes all other data which is the same as the data in traditional OS
environments.
The most important aspects of system
virtualization are encapsulation and isolation. Traditional operating systems
and applications running on them can be encapsulated in VMs. Only one operating
system runs in a virtualization while many applications run in the operating
system. System virtualization allows multiple VMs to run on a physical machine
and the VMs are completely isolated. To achieve encapsulation and isolation,
both the system software and the hardware platform, such as CPUs and chipsets,
are rapidly updated. However, storage is lagging. The storage systems become
the main bottleneck of VM deployment.
In
virtualization environments, a virtualization layer is inserted between the
hardware and traditional operating systems or a traditional operating system is
modified to support virtualization. This procedure complicates storage
operations. On the one hand, storage management of the guest OS per-forms as
though it is operating in a real hard disk while the guest OSes cannot access
the hard disk directly. On the other hand, many guest OSes contest the hard
disk when many VMs are running on a single physical machine. Therefore, storage
management of the underlying VMM is much more complex than that of guest OSes
(traditional OSes).
In addition, the storage primitives used by VMs
are not nimble. Hence, operations such as remap-ping volumes across hosts and
checkpointing disks are frequently clumsy and esoteric, and sometimes simply
unavailable. In data centers, there are often thousands of VMs, which cause the
VM images to become flooded. Many researchers tried to solve these problems in
virtual storage management. The main purposes of their research are to make
management easy while enhancing performance and reducing the amount of storage
occupied by the VM images. Parallax is a distributed storage system customized
for virtualization environments. Content Addressable Storage (CAS) is a
solution to reduce the total size of VM images, and therefore supports a large
set of VM-based systems in data centers.
Since traditional storage management techniques
do not consider the features of storage in virtualization environments,
Parallax designs a novel architecture in which storage features that have
traditionally been implemented directly on high-end storage arrays and
switchers are relocated into a federation of storage VMs. These storage VMs
share the same physical hosts as the VMs that they serve. Figure 3.26 provides
an overview of the Parallax system architecture. It supports all popular system
virtualization techniques, such as paravirtualization and full virtualization.
For each physical machine, Parallax customizes a special storage appliance VM.
The storage appliance VM acts as a block virtualization layer between
individual VMs and the physical storage device. It provides a virtual disk for
each VM on the same physical machine.
Example 3.11 Parallax Providing Virtual Disks
to Client VMs from a Large Common Shared Physical Disk
The architecture of Parallax is scalable and
especially suitable for use in cluster-based environments. Figure 3.26 shows a
high-level view of the structure of a Parallax-based cluster. A cluster-wide
administrative domain manages all storage appliance VMs, which makes storage
management easy. The storage appliance
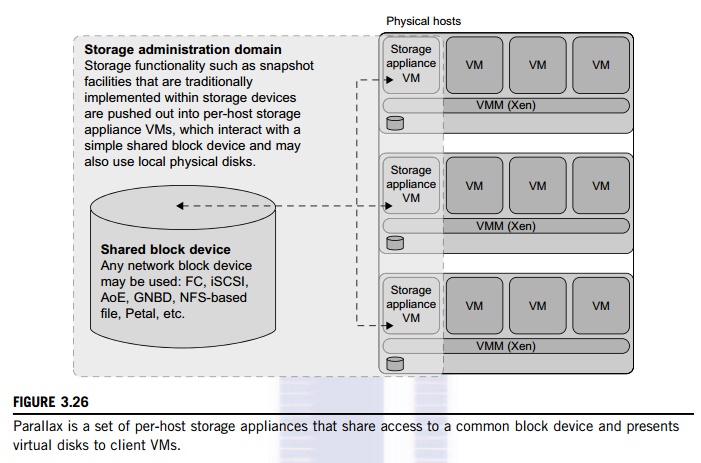
VM also allows functionality that is currently
implemented within data-center hardware to be pushed out and implemented on
individual hosts. This mechanism enables advanced storage features such as
snapshot facilities to be implemented in software and delivered above commodity
network storage targets.
Parallax itself runs as a user-level
application in the storage appliance VM. It provides virtual disk images (VDIs)
to VMs. A VDI is a single-writer virtual disk which may be accessed in a
location-transparent manner from any of the physical hosts in the Parallax
cluster. The VDIs are the core abstraction provided by Parallax. Parallax uses
Xen’s block tap driver to handle block requests and it is implemented as a
tapdisk library. This library acts as a single block virtualization service for
all client VMs on the same physical host. In the Parallax system, it is the
storage appliance VM that connects the physical hardware device for block and
network access. As shown in Figure 3.30, physical device drivers are included
in the storage appliance VM. This imple-mentation enables a storage
administrator to live-upgrade the block device drivers in an active cluster.
3. Cloud OS for Virtualized Data
Centers
Data centers must be
virtualized to serve as cloud providers. Table 3.6 summarizes four virtual infrastructure (VI) managers and OSes. These VI
managers and OSes are specially tailored for virtualizing data centers which often own a
large number of servers in clusters. Nimbus, Eucalyptus,

and OpenNebula are all open
source software available to the general public. Only vSphere 4 is a
proprietary OS for cloud resource virtualization and management over data
centers.
These VI managers are used to
create VMs and aggregate them into virtual clusters as elastic resources.
Nimbus and Eucalyptus support essentially virtual networks. OpenNebula has
additional features to provision dynamic resources and make advance
reservations. All three public VI managers apply Xen and KVM for virtualization.
vSphere 4 uses the hypervisors ESX and ESXi from VMware. Only vSphere 4
supports virtual storage in addition to virtual networking and data protection.
We will study Eucalyptus and vSphere 4 in the next two examples.
Example 3.12 Eucalyptus for Virtual Networking
of Private Cloud
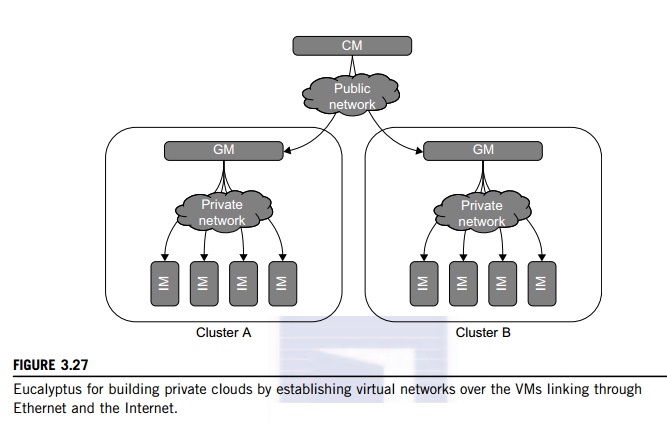
Eucalyptus
is an open source software system (Figure 3.27) intended mainly for supporting
Infrastructure as a Service (IaaS) clouds. The system primarily supports
virtual networking and the management of VMs; virtual storage is not supported.
Its purpose is to build private clouds that can interact with end users through
Ethernet or the Internet. The system also supports interaction with other
private clouds or public clouds over the Internet. The system is short on
security and other desired features for general-purpose grid or cloud
applications.
The designers of Eucalyptus [45] implemented
each high-level system component as a stand-alone web service. Each web service
exposes a well-defined language-agnostic API in the form of a WSDL document
containing both operations that the service can perform and input/output data
structures.
Furthermore,
the designers leverage existing web-service features such as WS-Security
policies for secure communication between components. The three resource
managers in Figure 3.27 are specified below:
• Instance
Manager controls the execution, inspection, and terminating of VM instances on
the host where it runs.
• Group
Manager gathers information about and schedules VM execution on specific
instance managers, as well as manages virtual instance network.
• Cloud
Manager is the entry-point into the cloud for users and administrators. It
queries node managers for information about resources, makes scheduling
decisions, and implements them by making requests to group managers.
In terms
of functionality, Eucalyptus works like AWS APIs. Therefore, it can interact
with EC2. It does provide a storage API to emulate the Amazon S3 API for
storing user data and VM images. It is installed on Linux-based platforms, is
compatible with EC2 with SOAP and Query, and is S3-compatible with SOAP and
REST. CLI and web portal services can be applied with Eucalyptus.
Example 3.13 VMware vSphere 4 as a Commercial
Cloud OS [66]
The vSphere 4 offers a hardware and software
ecosystem developed by VMware and released in April 2009. vSphere extends
earlier virtualization software products by VMware, namely the VMware
Workstation, ESX for server virtualization, and Virtual Infrastructure for
server clusters. Figure 3.28 shows vSphere’s
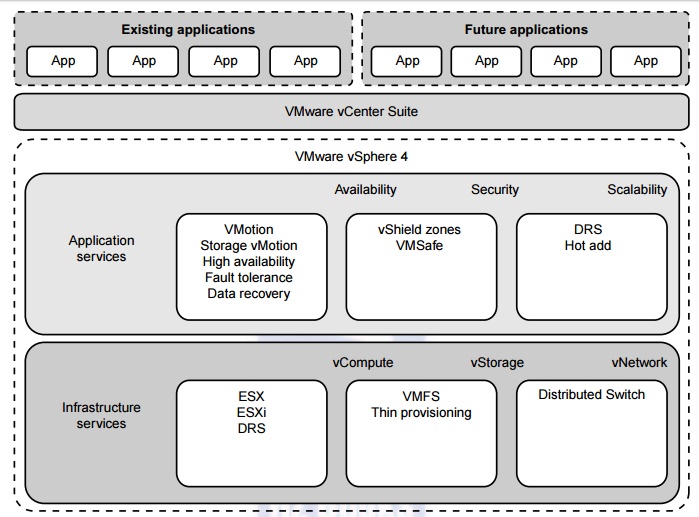
overall
architecture. The system interacts with user applications via an interface
layer, called vCenter. vSphere is primarily intended to offer virtualization
support and resource management of data-center resources in building private
clouds. VMware claims the system is the first cloud OS that supports
availability, security, and scalability in providing cloud computing services.
The vSphere 4 is built with two functional
software suites: infrastructure services and application services. It also has
three component packages intended mainly for virtualization purposes: vCompute
is supported by ESX, ESXi, and DRS virtualization libraries from VMware;
vStorage is supported by VMS and thin provisioning libraries; and vNetwork
offers distributed switching and networking functions. These packages interact
with the hardware servers, disks, and networks in the data center. These
infrastructure functions also communicate with other external clouds.
The application services are also divided into
three groups: availability, security, and scalability. Availability support
includes VMotion, Storage VMotion, HA, Fault Tolerance, and Data Recovery from
VMware. The security package supports vShield Zones and VMsafe. The scalability
package was built with DRS and Hot Add. Interested readers should refer to the
vSphere 4 web site for more details regarding these component software
functions. To fully understand the use of vSphere 4, users must also learn how
to use the vCenter interfaces in order to link with existing applications or to
develop new applications.
4. Trust Management in Virtualized
Data Centers
A VMM changes the computer
architecture. It provides a layer of software between the operating systems and
system hardware to create one or more VMs on a single physical platform. A VM
entirely encapsulates the state of the guest operating system running inside
it. Encapsulated machine state can be copied and shared over the network and
removed like a normal file, which proposes a challenge to VM security. In
general, a VMM can provide secure isolation and a VM accesses hard-ware
resources through the control of the VMM, so the VMM is the base of the
security of a virtual system. Normally, one VM is taken as a management VM to
have some privileges such as creating, suspending, resuming, or deleting a VM.
Once a
hacker successfully enters the VMM or management VM, the whole system is in
danger. A subtler problem arises in protocols that rely on the “freshness” of their random number source for generating
session keys. Considering a VM, rolling back to a point after a random number
has been chosen, but before it has been used, resumes execution; the random
number, which must be “fresh” for security purposes, is reused. With a
stream cipher, two different plaintexts could be encrypted under the same key
stream, which could, in turn, expose both plaintexts if the plaintexts have
suffi-cient redundancy. Noncryptographic protocols that rely on freshness are
also at risk. For example, the reuse of TCP initial sequence numbers can raise
TCP hijacking attacks.
4.1
VM-Based Intrusion Detection
Intrusions are unauthorized
access to a certain computer from local or network users and intrusion
detection is used to recognize the unauthorized access. An intrusion detection
system (IDS) is built on operating systems, and is based on the characteristics
of intrusion actions. A typical IDS can be classified as a host-based IDS (HIDS) or a network-based IDS (NIDS), depending on the data
source. A HIDS can be implemented on the monitored system. When the monitored
system is attacked by hackers, the HIDS also faces the risk of being attacked.
A NIDS is based on the flow of network traffic which can’t detect fake actions.
Virtualization-based
intrusion detection can isolate guest VMs on the same hardware platform. Even
some VMs can be invaded successfully; they never influence other VMs, which is
similar to the way in which a NIDS operates. Furthermore, a VMM monitors and
audits access requests for hardware and system software. This can avoid fake
actions and possess the merit of a HIDS. There are two different methods for
implementing a VM-based IDS: Either the IDS is an independent process in each
VM or a high-privileged VM on the VMM; or the IDS is integrated into the VMM
and has the same privilege to
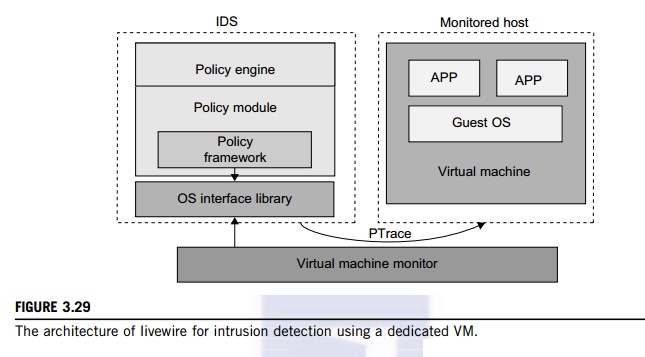
access the hardware as well as the VMM. Garfinkel and Rosenblum [17] have
proposed an IDS to run on a VMM as a high-privileged VM. Figure 3.29
illustrates the concept.
The
VM-based IDS contains a policy engine and a policy module. The policy framework
can monitor events in different guest VMs by operating system interface library
and PTrace indicates trace to secure policy of monitored host. It’s difficult to predict and prevent all
intrusions without delay. Therefore, an analysis of the intrusion action is
extremely important after an intrusion occurs. At the time of this writing,
most computer systems use logs to analyze attack actions, but it is hard to
ensure the credibility and integrity of a log. The IDS log service is based on
the operating system ker-nel. Thus, when an operating system is invaded by
attackers, the log service should be unaffected.
Besides IDS, honeypots and
honeynets are also prevalent in intrusion detection. They attract and provide a
fake system view to attackers in order to protect the real system. In addition,
the attack action can be analyzed, and a secure IDS can be built. A honeypot is
a purposely defective system that simulates an operating system to cheat and
monitor the actions of an attacker. A honeypot can be divided into physical and
virtual forms. A guest operating system and the applications running on it
constitute a VM. The host operating system and VMM must be guaranteed to prevent
attacks from the VM in a virtual honeypot.
Example 3.14 EMC Establishment of Trusted Zones
for Protection of Virtual Clusters Provided to Multiple Tenants
EMC and
VMware have joined forces in building security middleware for trust management
in distribu-ted systems and private clouds. The concept of trusted zones was
established as part of the virtual infrastructure. Figure 3.30 illustrates the
concept of creating trusted zones for virtual clusters (multiple
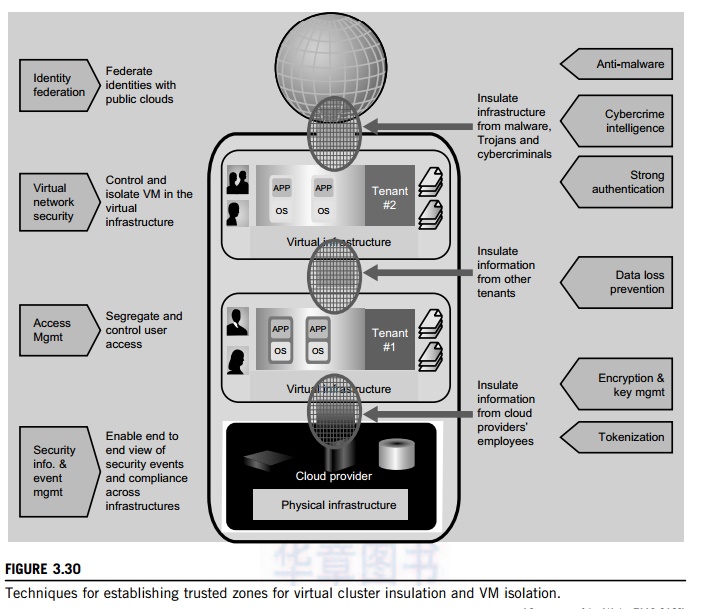
applications
and OSes for each tenant) provisioned in separate virtual environments. The
physical infrastructure is shown at the bottom, and marked as a cloud provider.
The virtual clusters or infrastruc-tures are shown in the upper boxes for two
tenants. The public cloud is associated with the global user communities at the
top.
The
arrowed boxes on the left and the brief description between the arrows and the
zoning boxes are security functions and actions taken at the four levels from
the users to the providers. The small circles between the four boxes refer to
interactions between users and providers and among the users themselves. The
arrowed boxes on the right are those functions and actions applied between the
tenant environments, the provider, and the global communities.
Almost all available countermeasures, such as
anti-virus, worm containment, intrusion detection, encryption and decryption
mechanisms, are applied here to insulate the trusted zones and isolate the VMs
for private tenants. The main innovation here is to establish the trust zones
among the virtual clusters.
The end
result is to enable an end-to-end view of security events and compliance across
the virtual clusters dedicated to different tenants. We will discuss security
and trust issues in Chapter 7 when we study clouds in more detail.
Related Topics