Chapter: Embedded Systems Design : Memory systems
Segmentation and paging
Segmentation and paging
There are two methods of splitting the system memory into smaller blocks
for memory management. The size of these blocks is quite critical within the
design. Each block requires a translation descriptor and therefore the size of
the block is important. If the granularity is too small (i.e. the blocks are
1–2 kbytes), the number of descriptors needed for a 4 Gbyte system is extremely
large. If the blocks are too big, the number of descriptors reduces but
granular-ity increases. If a program just needs a few bytes, a complete block
will have to be allocated to it and this wastes the unused memory. Between
these two extremes lies the ideal trade-off.
A segmented memory management scheme has a small number of descriptors
but solves the granularity problem by allowing the segments to be of a variable
size in a block of contiguous memory. Each segment descriptor is fairly complex
and the hardware has to be able to cope with different address translation
widths. The memory usage is greatly improved, al-though the task of assigning
memory segments in the most effi-cient way is difficult.
This problem occurs when a system has been operating for some time and
the segment distribution is now right across the memory map. The free memory
has been fragmented into small chunks albeit in large numbers. In such cases,
the total system memory may be more than sufficient to allocate another
segment, but the memory is non-contiguous and therefore not available. There is
nothing more frustrating, when using such systems, as the combination of ‘2
Mbytes RAM free’ and ‘Insufficient memory to load’ messages when trying to
execute a simple utility. In such cases, the current tasks must be stopped,
saved and restarted to repack them and free up the memory. This problem can
also be found with file storage systems which need contiguous disk sectors and
tracks.
A paged memory system splits memory needs into multi-ple, same sized
blocks called pages. These are usually 1–2 kbytes in size, which allows them to
take easy advantage of fragmented memory. However, each page needs a
descriptor, which greatly increases the size of the look up tables. With a 4
Gbyte logical address space and 1 kbyte page size, the number of descriptors
needed is over 4 million. Each descriptor would be 32 bits (22 bits translation
address, 10 bits for protection and status) in size and the corresponding table
would occupy 16 Mbytes! This is a little impractical, to say the least. To
decrease the amount of storage needed for the page tables, multi-level tree
structures are used. Such mechanisms have been implemented in the MC68851 paged
memory management unit (PMMU), the MC68030 processor, PowerPC and ARM 920
processors, to name but a few.
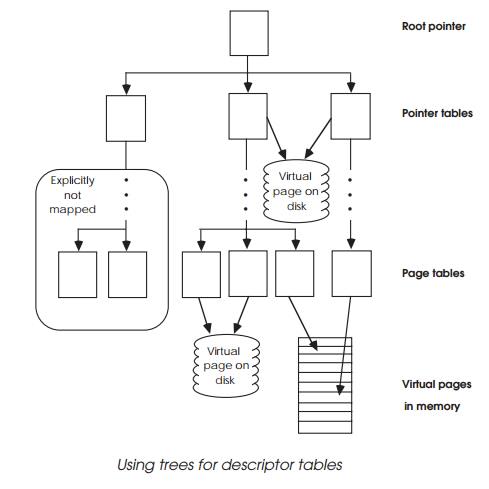
Trees work by dividing the logical address into fields and using each of
the fields to successively reference into tables until the translation address
is located. This is then concatenated with the lower order page address bits to
complete a full physical address. The root pointer forms the start of the tree
and there may be separate pointers for user and supervisor use.
The root pointer points to separate pointer tables, which in turn point
to other tables and so on, until the descriptor is finally reached. Each
pointer table contains the address of the next location. Most systems differ in
the number of levels and the page sizes that can be implemented. Bits can often
be set to terminate the table walk when large memory areas do not need to be
uniquely defined at a lower or page level. The less levels, the more efficient
the table walking.
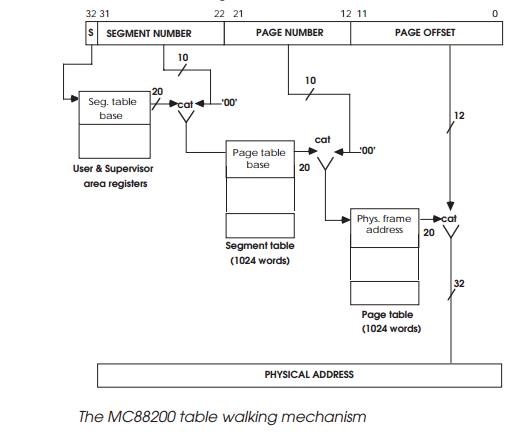
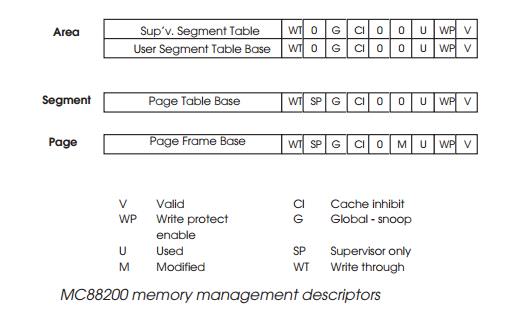
The next diagram shows the three-level tree used by the MC88200 CMMU.
The logical 32 bit address is extended by a user/ supervisor bit which is used
to select one of two possible segment table bases from the user and supervisor
area registers. The segment number is derived from bits 31 to 22 and is
concatenated with a 20 bit value from the segment table base and a binary ‘00’
to create a 32 bit address for the page number table. The page table base is
derived similarly until the complete translation is obtained. The remaining 12
bits of the descriptors are used to define the page, segment or area status in
terms of access and more recently, cache coherency mechanisms. If the attempted
access does not match with these bits (e.g. write to a write protected page),
an error will be sent back to the processor.
The next two diagrams show a practical implementation using a two-level
tree from an MC68851 PMMU. This is probably the most sophisticated of any of
the MMU schemes to have appeared in the last 20 years. It could be argued that
it was over-engineered as subsequent MMUs have effectively all been subsets of
its features. One being the number of table levels it supported. However as an
example, it is a good one to use as its basic principles are used even today.
The table walking mechanism compresses the amount of information needed
to store the translation information. Consider a task that occupies a 1 Mbyte
logical address map consisting of a code, data and stack memory blocks. Not all
the memory is used or allocated and so the page tables need to identify which
of the 2 kbyte pages are not valid and the address translation values for the
others. With a single-level table, this would need 512 descriptors, assuming a
2 kbyte page size. Each descriptor would need to be available in practice. Each
2 kbyte block has its own descriptor in the table and this explains why a
single level table will have 512 entries. Even if a page is not used, it has to
have an entry to indicate this. The problem with a single level table is the
number of descriptors that are needed. They can be reduced by increasing the
page size — a 4 kbyte page will have the number of required descriptors — but
this makes memory allocation extravagant. If a data structure needs 5 bytes
then a whole page has to be allocated to it. If it is just a few bytes bigger
than a page, a second page is needed. If a system has a lot of small data
structures and limited memory then small pages are probably the best choice to
get the best memory use. If the structures are large or memory in not a problem
then larger page sizes are more efficient from the memory management side of
the design.
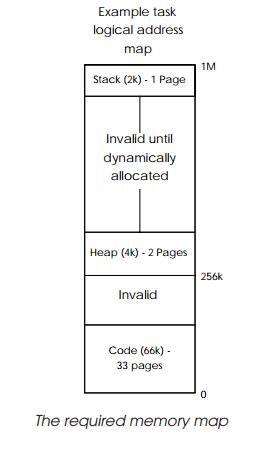
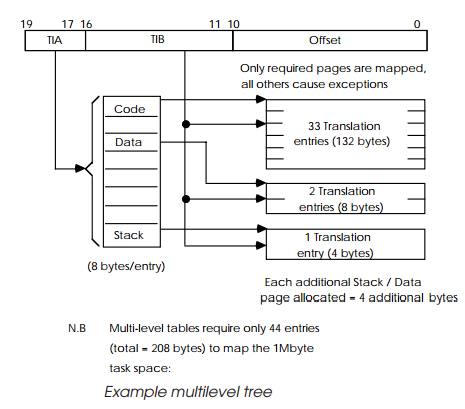
With the two-level scheme shown, only the pages needed are mapped. All
other accesses cause an exception to allocate extra pages as necessary. This
type of scheme is often called demand paged memory management. It has the
advantage of immediately removing the need for descriptors for invalid or
unused pages which reduces the amount of data needed to store the descriptors.
This means that with the two-level table mechanism shown in the diagram,
only 44 entries are needed, occupying only 208 bytes, with additional pages
increasing this by 4 bytes. The exam-ple shows a relatively simple two-level
table but up to five levels are often used. This leads to a fairly complex and
time consuming table walk to perform the address translation.
To improve performance, a cache or buffer is used to contain the most
recently used translations, so that table walks only occur if the entry is not
in the address translation cache (ATC) or translation look-aside buffer (TLB).
This makes a lot of sense — due to the location of code and data, there will be
frequent accesses to the same page and by caching the descriptor, the penalty
of a table walk is only paid on the first access. However, there are still some
further trade-offs to consider.
Related Topics