Chapter: Embedded Systems Design : Memory systems
Cache size and organization
Cache size and organization
There are several criteria associated with cache design which affect its
performance. The most obvious is cache size — the larger the cache, the more
entries that are stored and the higher the hit rate. However, as the cache size
increases, the return gets smaller and smaller. In practice, the cache costs
and complexity place an economic limit on most designs. As the size of programs
increase, larger caches are needed to maintain the same hit rate and hence the
‘ideal cache size is always twice that available’ comment. In reality, it is
the combination of size, organization and cost that really determines the size
and its efficiency.
Consider a basic cache operation. The processor generates an address
which is fed into the cache memory system. The cache stores its data in an
array with an address tag. Each tag is com-pared in turn with the incoming
address. If they do not match, the next tag is compared. If they do match, a
cache hit occurs, the corresponding data within the array is passed on the data
bus to the processor and no further comparisons are made. If no match is found
(a cache miss), the data is fetched from external memory and a new entry is
created in the array. This is simple to imple-ment, needing only a memory array
and a single comparator and counter. Unfortunately, the efficiency is not very
good due to the serial interrogation of the tags.
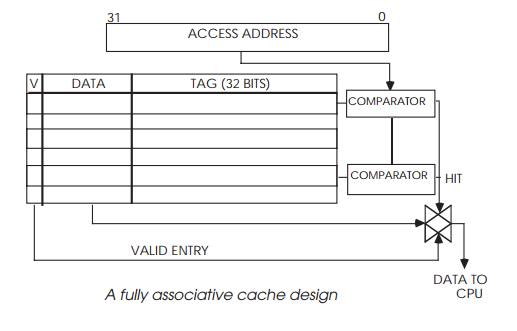
A better solution is to have a comparator for each entry, so all entries
can be tested simultaneously. This is the organization used in a fully
associative cache. In the example, a valid bit is added to each entry in the
cache array, so that invalid or unused entries can be easily identified. The
system is very efficient from a software perspective — any entry can be used to
store data from any address. A software loop using only 20 bytes (10 off 16 bit
instructions) but scattered over a 1,024 byte range would run as efficiently as
another loop of the same size but occupying consecu-tive locations.
The disadvantage of this approach is the amount of hard-ware needed to
perform the comparisons. This increases in pro-portion to the cache size and
therefore limits these fully associative caches to about 10 entries. The fully
associative cache locates its data by effectively asking nquestions
where n is the number of entries within it. An alternative organization is to
assume certain facts derived from the data address so that only one location
can possibly have the data and only one comparator is needed, irre-spective of
the cache size. This is the idea behind the direct map cache.
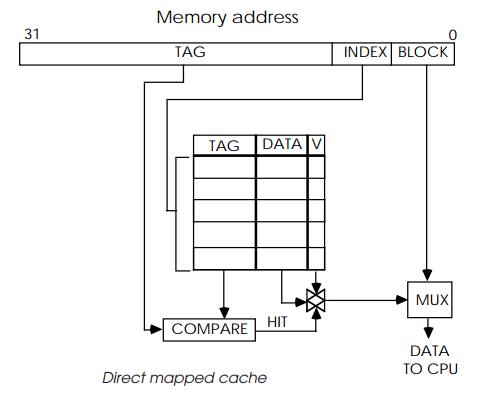
The address is presented as normal but part of it is used to index into
the tag array. The corresponding tag is compared and, if there is a match, the
data is supplied. If there is a cache miss, the data is fetched from external
memory as normal and the cache updated as necessary. The example shows how the
lower address bits can be used to locate a byte, word or long word within the
memory block stored within the array. This organization is simple from the
hardware design perspective but can be inefficient from a software viewpoint.
The index mechanism effectively splits external memory space into a
series of consecutive memory pages, with each page the same size as the cache.
Each page is mapped to resemble the cache and therefore each location in the
external memory page can only correspond with its own location in the cache.
Data that is offset by the cache size thus occupies the same location within
the cache, albeit with different tag values. This can cause bus thrash-ing.
Consider a case where words A and B are offset by the cache size. Here, every
time word A is accessed, word B is discarded from the cache. Every time word B
is accessed, word A is lost. The cache starts thrashing and the overall
performance is degraded. The MC68020 is a typical direct mapped cache.
A way to solve this is to split the cache so there are two or four
possible entries available for use. This increases the compara-tor count but
provides alternative locations and prevents bus thrashing. Such designs are
described as ‘n way set associative’,
where n is the number of possible
locations. Values of 2, 4, 8 are quite typical of such designs.
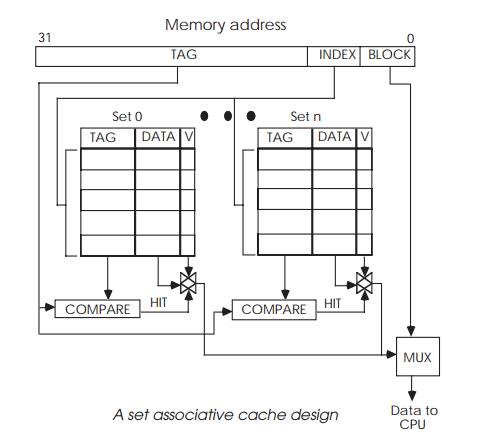
Many RISC-based caches are organized as a four way set associative cache
where a particular address will have four possi-ble locations in the cache
memory. This has advantages for the software environment in that context
switching code with the same address will not necessarily overwrite each other
and keep destroying the contents of the cache memories.
The advantage of a set associative cache is its ability to prevent
thrashing at the expense of extra hardware. However, all the caches so far
described can be improved by further reorganiz-ing so that each tag is
associated with a line of long words which can be burst filled using a page
memory interface.
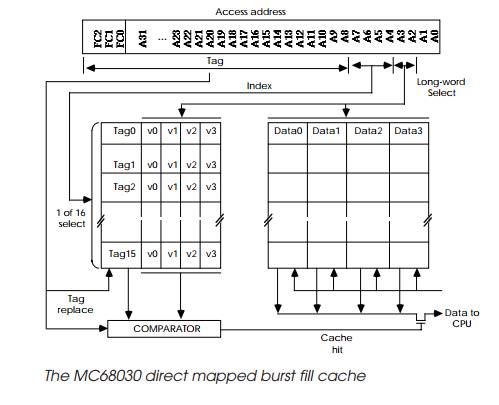
The logic behind this idea is based on the sequential nature of
instruction execution and data access. Instruction fetches and execution simply
involve accesses to sequential memory locations until a program flow change
happens due to the execution of a branch or jump instruction. Data accesses
often follow this pattern during stack and data structure manipulation.
It follows that if a cache is organized with, say, four long words
within each tag line, a hit in the first long word would usually result in hits
in the rest of the line, unless a flow change took place. If a cache miss was
experienced, it would be beneficial to bring in the whole line, providing this
could be achieved in less time than to bring in the four long words
individually. This is exactly what happens in a page mode interface. By
combining these, a more efficient cache can be designed which even benefits in
line code. This is exactly how the MC68030 cache works.
Address bits 2 and 3 select which long word is required from the four
stored in the 16 byte wide line. The remaining higher address bits and function
codes are the tag which can differentiate between supervisor or user accesses
etc. If there is a cache miss, the processor uses its synchronous bus with
burst fill to load up the complete line.

With a complete line updated in the cache, the next three instructions
result in a hit, providing there is no preceding flow change. These benefit
from being cached, even though it is their first execution. This is a great
improvement over previous designs, where the software had to loop before any
benefit could be gained. The table above shows the estimated improvements that
can be obtained.
The effect is similar to increasing the cache size. The largest effect
being with instruction fetches which show the greatest degree of locality. Data
reads are second, but with less impact due to isolated byte and word accesses.
Data read and write operations are further reduced, caused by the cache’s
write-through policy. This forces all read-modify-write and write operations to
main memory. In some designs, data accesses are not sequential, in which case,
system performance actually degrades when the data cache is enabled — burst
filling the next three long words is simply a waste of time, bus bandwidth and
performance. The solution is simple — switch off the cache! This design is used
in most high performance cache designs.
Related Topics