Chapter: Embedded Systems Design : Memory systems
Cache coherency
Cache coherency
The biggest challenge with cache design is how to solve the problem of
data coherency, while remaining hardware and soft-ware compatible. The issue
arises when data is cached which can then be modified by more than one source.
An everyday analogy is that of a businessman with two diaries — one kept by his
secretary in the office and the other kept by him. If he is out of the office
and makes an appointment, the diary in the office is no longer valid and his
secretary can double book him assuming, incorrectly, that the office diary is correct.
This problem is normally only associated with data but can occur with
instructions within an embedded application. The stale data arises when a copy
is held both in cache and in main memory. If either copy is modified, the other
becomes stale and system coherency is destroyed. Any changes made by the
processor can be forced through to the main memory by a ‘write-through’ policy,
where all writes automatically update cache and main memory. This is simple to
implement but does couple the processor unnec-essarily to the slow memory. More
sophisticated techniques, like ‘copy-back’ and ‘modified write-back’ can give
more performance (typically 15%, although this is system and software
dependent) but require bus snooping support to detect accesses to the main
memory when the valid data is in the cache.
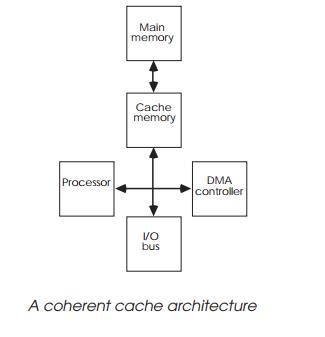
The ‘write-through’ mechanism solves the problem from the processor
perspective but does not solve it from the other direction. DMA (Direct Memory
Access) can modify memory directly without any processor intervention. Consider
a task swap-ping system. Task A is in physical memory and is cached. A swap
occurs and task A is swapped out to disk and replaced by task B at the same
location. The cached data is now stale. A software solution to this involves
flushing the cache when the page fault happens so the previous contents are
removed. This can destroy useful cached data and needs operating system
support, which can make it non–compatible. The only hardware solution is to
force any access to the main memory via the cache, so that the cache can update
any modifications.
This provides a transparent solution — but it does force the processor
to compete with the DMA channels and restricts cach-ing to the main memory
only, with a resultant impact on perform-ance.
While many system designs use cache memory to buffer the fast processor
from the slower system memory, it should be remembered that access to system
memory is needed on the first execution of an instruction or software loop and
whenever a cache miss occurs. If this access is too slow, these overheads
greatly diminish the efficiency of the cache and, ultimately, the proces-sor’s
performance. In addition, switching on caches can cause software that works
perfectly to crash and, in many configura-tions, the caches remain switched off
to allow older software to execute correctly.
Other problems can occur when data that is not intended to be cached is
cached by the system. Shared memory or I/O ports are two areas that come
immediately to mind. Shared memory relies on the single memory structure to
contain the recent data. If this is cached then any updates may not be made to
the shared memory. Any other CPU or DMA that accesses the shared memory will
not get the latest data and the stale data may cause the system to crash. The
same problem can happen with I/O ports. If accesses are cached then reading an
I/O port to get status information will return with the cached data which may
not be consistent with the data at the I/O port. It is important to be able to
control which memory regions are cached and which are not. It should be no
surprise that MMUs and memory protection units are used to perform this
function and allow the control of the caches to be performed automatically
based on memory addresses and associ-ated access bits.
A lot is made of cache implementations — but unless the main system
memory is fast and software reliable, system and software performance will
degrade. Caches help to regain per-formance lost through system memory wait states
but they are never 100% efficient. A system with no wait states always
pro-vides the best performance. Add to that the need for control and the
selection of the right cache coherency policy for the system and designing for
any system that has caches requires a detailed understanding of what is going
on to get the best out of the system.
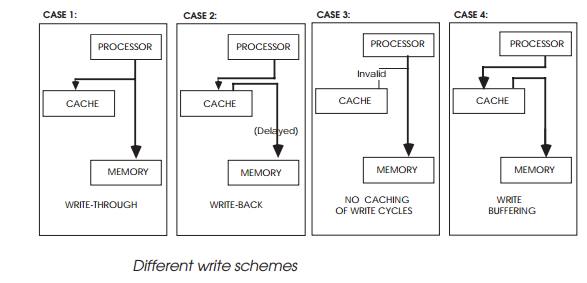
Case 1: write-through
In this case, all data writes go through to main memory and update the
system as well as the cache. This is simple to implement but couples the processor
unnecessarily to slow memory. If data is modified several times before another
master needs it, the write-through policy consumes external bus bandwidth
supplying data that is not needed. This is not terribly efficient. In its
favour, the scheme is very simple to implement, providing there is only a
single cache within the system.
If there are more than two caches, the stale data problem reappears in
another guise. Consider such a system where two processors with caches have a
copy of a global variable. Neither processor accesses main memory when reading
the variable, as the data is supplied by the respective caches. Processor A now
modifies the variable — its cache is updated, along with the system memory.
Unfortunately, processor B´s cache is left with the old stale data, creating a
coherency problem. A similar prob-lem can occur within paging systems.
It also does not address the problem with I/O devices either although
the problem will occur when the I/O port is read for a second and subsequent
times as the cache will supply the data on these accesses instead of the I/O
port itself.
DMA (direct memory access) can modify memory directly without any
processor intervention. Consider a UNIX paging system. Page A is in physical
memory and is cached. A page fault occurs and page A is swapped out to disk and
replaced by page B at the same location. The cached data is now stale. A
software solution to this involves flushing the cache when the page fault
happens so the previous contents are removed. This can destroy useful cached
data and needs operating system support, which can make it non-compatible. The
only hardware solution is to force any access to the main memory via the cache,
so that the cache can update any modifications. This provides a transparent
solution, but it does force the processor to compete with the DMA channels, and
restricts caching to the main memory only, with the subsequent reduced
performance.
Case 2: write-back
In this case, the cache is updated first but the main memory is not
updated until later. This is probably the most efficient method of caching,
giving 15–20% improvement over a straight write-through cache. This scheme
needs a bus snooping mecha-nism for coherency and this will be described later.
The usual cache implementation involves adding dirty bits to the tag to
indicate which cache lines or partial lines hold modified data that has not
been written out to the main memory. This dirty data must be written out if
there is any possibility that the information will be lost. If a cache line is
to be replaced as a result of a cache miss and the line contains dirty data,
the dirty data must be written out before the new cache line can be accepted.
This increases the impact of a cache miss on the system. There can be further
complications if memory management page faults occur. However, these aspects
must be put into perspective — yes, there will be some system impact if lines
must be written out, but this will have less impact on a wider scale. It can
double the time to access a cache line, but it has probably saved more
performance by removing multiple accesses through to the main memory. The trick
is to get the balance in your favour.
Case 3: no caching of write
cycles
In this method, the data is written through but the cache is not
updated. If the previous data had been cached, that entry is marked invalid and
is not used. This forces the processor to access the data from the main memory.
In isolation, this scheme does seem to be extremely wasteful, however, it often
forms the back-bone of a bus snooping mechanism.
Case 4: write buffer
This is a variation on the write-through policy. Writes are written out
via a buffer to the main memory. This enables the processor to update the ‘main
memory’ very quickly, allowing it to carry on processing data supplied by the
cache. While this is going on, the buffer transfers the data to the main
memory. The main advantage is the removal of memory delays during the writes.
The system still suffers from coherency problems caused through multiple
caches.
Another term associated with these techniques is write allocation. A
write-allocate cache allocates entries in the cache for any data that is
written out. The idea behind this is simple — if data is being transferred to external
memory, why not cache it, so that when it is accessed again, it is already
waiting in the cache. This is a good idea if the cache is large but it does run
the risk of overwriting other entries that may be more useful. This problem is
particularly relevant if the processor performs block transfers or memory
initialisation. Its main use is within bus snooping mecha-nisms where a first
write-allocate policy can be used to tell other caches that their data is now
invalid. The most important need with these methods and ideas is bus snooping.
Related Topics