Chapter: Artificial Intelligence
Intelligent Agent
INTELLIGENT AGENT:
Agent =
perceive+act
·
Thinking
·
Reasonig
·
Planning
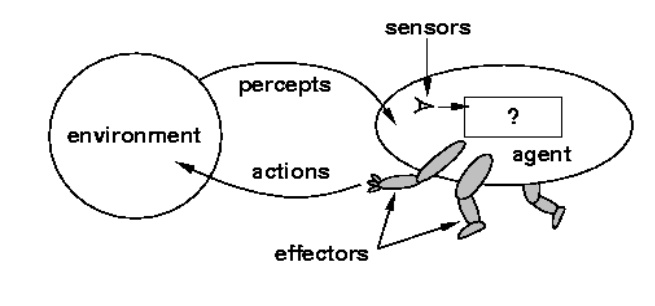
Agent: entity in a progra m or
environment capable of generating action.
An agent
uses perceptio n of the environment
to make decisions about actions to take. The perception capability is usually
called a sensor.
The
actions can depend on the most recent perception or on the entir e history
(percept sequence).
An agent
is anything that can be viewed as perceiving its environment through s ensors
and acting upon the environment through ac tuators.
Ex: Robotic agent
Human
agent
Agents
interact with environment through sensors and actuators.

Percept
sequence action
[A,
clean] right
[A, dirt] suck
[B,
clean] left
[B,
dirty] suck
[A,
clean], [A, clean] right
[A,
clean], [A, dirty] suck
Fig: practical
tabulation of a simple agent function for the vacuum cleaner world
Agent Function
1.The agent function is a mathematical
function that maps a sequence of perceptions into action.
2.
The function is imple mented as the agent program.
3.
The part of the agent t aking an action is called
an actuator.
4.
Environment ®sensors ®agent function ®actuators
®environment
RATIONAL AGENT:
A rational agent is one that can take the
right decision in every situation.
Performance measure: a set
of criteria/test bed for the success of the age nt's behavior.
The
performance measu res should be based on the desired effect of the agent on the
environment.
Rationality:
The
agent's rational beha vior depends on:
1.the
performance me asure that defines success
2. the
agent's knowledge of the environment
3.the
action that it is capable of performing
4 .The
current sequen ce of perceptions.
Definition: for every
po ssible percept sequence, the agent is expected to take an action
that will maximize its performance measure.
Agent Autonomy:
An agent
is omniscient i f it knows the actual
outcome of its actions. Not possible in practice. An environment can sometimes be completely known in advanc e.
Exploration: sometimes an agent must perform
an action to gather information (to increase
perception).
Autonomy: the capacity to compen sate for
partial or incorrect prior knowledge (usually by learning).
NATURE OF ENVIRONMEN TS:
Task environment – the problem that the agent is a
solution to. Includes
Performance
measure
Environment
Actuator
Sensors
Properties of Task Environment:
•
Fully
Observable (vs. P artly Observable)
– Agent sensors give complete state of the
environment at each poi nt in time
– Sensors detect all the aspect that is
relevant to the choice of actio n.
– An
environment might be partially observable because of noisy a nd inaccurate
sensor s or apart of the state are simply missing from the sensor data.
•
Deterministic
(vs. Stochastic)
– Next state of the e nvironment is completely
determined by the current state and the
action executed by the agent
–
Strategic environment (if the environment is deterministic except for the
actions of other agent.)
•
Episodic
(vs. Sequential)
– Agent’s
experience can be divided into episodes, each episode with what an agent
perceive and what is the action
•
Next episode does not depend on the previous
episode
– Current decision will affect all future sates
in sequential environment
•
Static
(vs. Dynamic)
– Environment doesn’t change as the agent is
deliberating
– Semi dynamic
•
Discrete
(vs. Continuous)
– Depends the way time is handled in describing
state, percept, actions
• Chess game : discrete
• Taxi driving : continuous
•
Single
Agent (vs. Multi Agent)
– Competitive, cooperative multi-agent
environments
– Communication is a key issue in multi agent
environments.
Partially Observable:
Ex:
Automated taxi cannot see what other devices are thinking. Stochastic:
Ex: taxi
driving is clearly stochastic in this sense, because one can never predict the
behaviorof the traffic exactly.
Semi dynamic:
If the
environment does not change for some time, then it changes due to agent’s
performance is called semi dynamic environment.
Single Agent Vs multi agent:
An agent
solving a cross word puzzle by itself is clearly in a single agent environment.
An agent
playing chess is in a two agent environment.
Example of Task Environments and Their Classes
Four types of agents:
1.
Simple reflex agent
2.
Model based reflex agent
3.
goal-based agent
4.
utility-
base
agent
Simple reflex agent
Definition:
SRA works
only if the correct decision can be made on the basis of only the current
percept that is only if the environment is fully observable.
Characteristics
– no
plan, no goal
– do not know what they want to achieve
– do not know what they are doing
Condition-action rule
– If condition then action
Ex: medical diagnosis system.
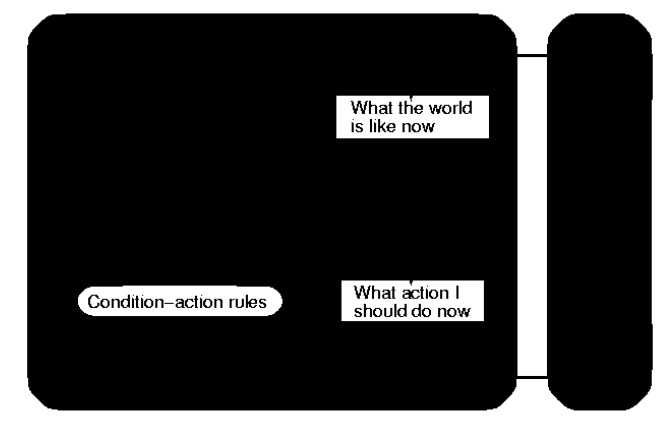

Algorithm Explanation:
Interpret
– Input:
Function
generates an abstracte d description of the current state from the percept.
RULE-
MATCH:
Function
returns the first rule in the set of rules that matches the given state
description.
RULE -
ACTION:
The
selected rule is executed as action of the given percept.
Model-Based Reflex Agents:
Definition:
An agent
which combines the current percept with the old internal state to generate
updated description of the current state.
If the
world is not fully o bservable, the agent must remember observations about the
parts of the environment it cannot currently observe.
This
usually requires an internal representation of the world (or internal state).
Since
this representation is a model of the world, we call this model-bas ed agent.
Ex: Braking problem
characteristics
1.Reflex
agent with internal state
2.Sensor
does not provide the complete state of the world.
3. must
keep its internal state
Updating the internal wo rld
requires two kinds of knowledge
1.
How world evolves
2.
How agent’s action affect the world
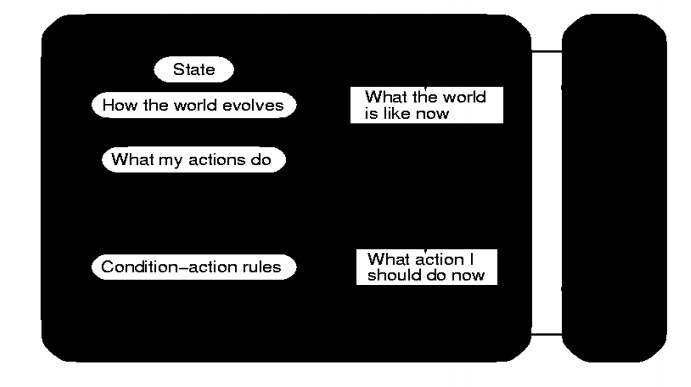

Algorithm Explanation:
UPDATE-INPUT: This is
responsible for creating the new internal stated description.
Goal-based agents:
The agent
has a purpose and the action to be
taken depends on the curre nt state and on what it tries to acc omplish (the
goal).
In some
cases the goal is easy to achieve. In others it involves planning, sifting through a search
space for possible solutions, developing a strategy.
Characteriscs
– Action depends on the goal. (consideration of
future)
– e.g. path finding
– Fundamentally different from the
condition-action rule.
– Search and Planning
– Solving “car-braking” problem?
– Yes, possible … but not likely natural.
•
Appears less efficient.
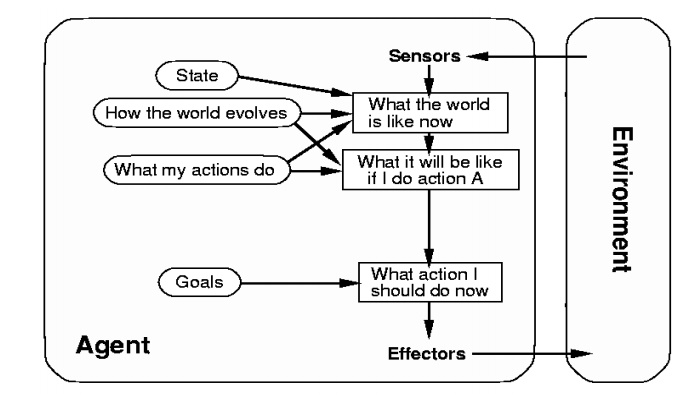
Utility-based agents
If one
state is preferred over the other, then it has higher utility for the agent
Utility-Function
(state) = real number (degree of happiness)
The agent
is aware of a utility function that estimates how close the current state is to
the agent's goal.
•
Characteristics
– to generate high-quality behavior
– Map the
internal states to real numbers. (e.g., game playing)
Looking
for higher utility value utility function
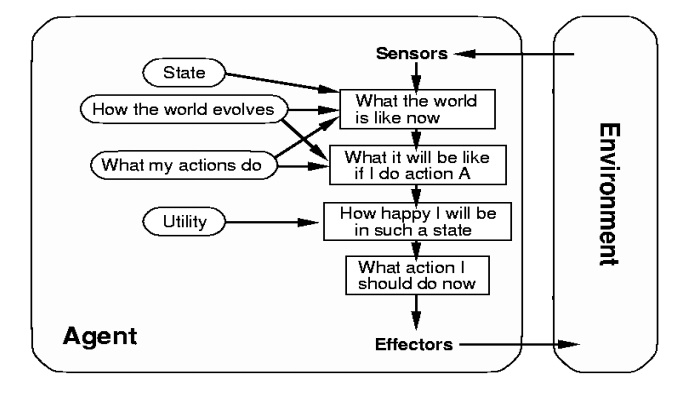
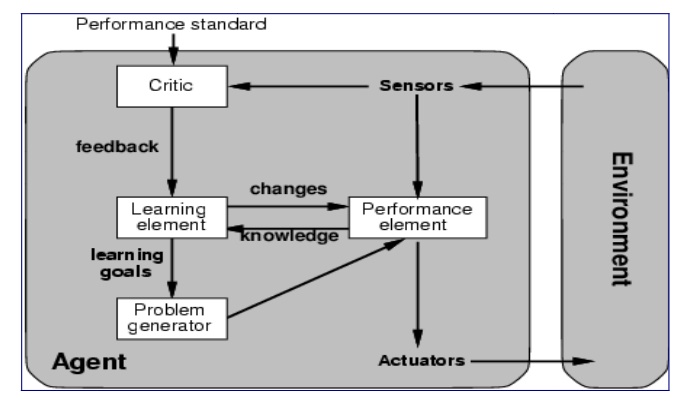
Learning Agents
Agents
cap able of acquiring new competence through obse rvations and actions.
Learning agent has the following components
Learning eleme nt
Suggests
modification to the existing rule to the critic
Performance ele ment
Collectio
n of knowledge and procedures for selecting the driving actions
Choice de
pends on Learning element
Critic
Observes
the world and passes information to the learnin g element
Problem generator
Identifies
certain areas of behavior needs improvement and suggest experiments
Agent Example
A file
manager agent.
Sensors:
commands like ls, du, pwd.
Actuators:
commands lik e tar, gzip, cd, rm, cp, etc.
Purpose:
compress and archive files that have not been used in a while.
Environment:
fully obse rvable (but partially observed), deterministic (st rategic),
episodic, dynamic, discrete.
Problem Formulation
Problem
formulation is the process of deciding what actions and states to consider,
given a goal
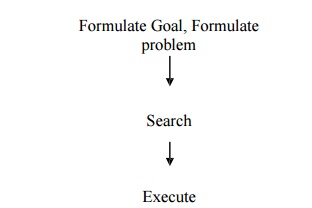
PROBLEMS
Four components of problem definition
– Initial
state – that the agent starts in
– Possible
Actions
•
Uses a Successor Function
– Returns <action, successor>
pair
•
State Space – the state space forms a
graph in which the nodes are states and arcs between nodes are
actions.
•
Path
– Goal
Test – which determine whether a given state is goal state
– Path
cost – function that assigns a numeric cost to each path.
SOME
REAL-WORLD PROBLEMS
•
Route finding
•
Touring (traveling salesman)
•
Logistics
•
VLSI layout
•
Robot navigation
•
Learning
TOY PROBLEM
Example-1 : Vacuum World
Problem Formulation
•
States
– 2 x 22 = 8 states
– Formula n2n states
•
Initial
State
– Any one of 8 states
•
Successor
Function
– Legal states that result from three actions
(Left, Right, Suck)
•
Goal Test
– All squares are clean
•
Path Cost
– Number of steps (each step costs a value of
1)
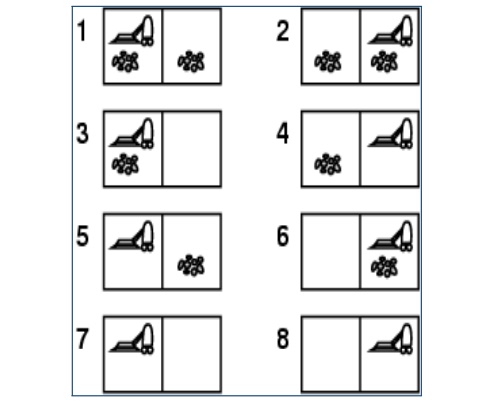
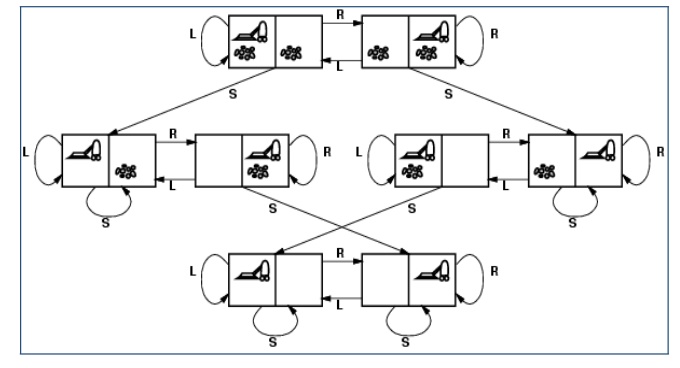
State Space for the Vacuum World.
Labels on
Arcs denote L: Left, R: Right, S: Suck
Related Topics