Chapter: Psychology: Language
Discovering the Building Blocks of Language
Discovering the
Building Blocks of Language
Neuroscientific findings show
that infants are ready for language learning at birth or almost immediately
thereafter. One group of investigators recorded changes in the blood flow in
2-day-old babies’ brains in the presence of linguistic stimulation. Half of the
time the babies were hearing recordings of normal human speech, and the other
half of the time they were hearing that speech played backward. Blood flow in
the
babies’ left hemisphere increased
for the normal speech but not for the backward speech (Gervain, Macagno, Cogoi,
Peña, & Mehler, 2008). Because the left hemisphere of the brain is the
major site for linguistic activity in humans, this evidence suggests that the
special responsiveness to language-like signals is already happening close to
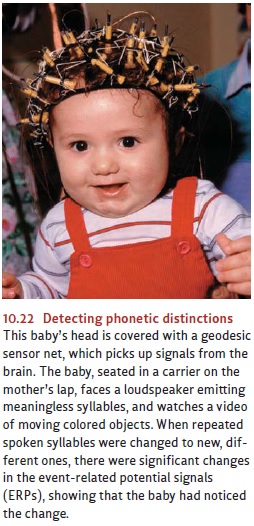
the moment of birth (Figure 10.22).
THE RHYTHMIC FOUNDATIONS OF LANGUAGE LEARNING
Recall that languages vary in
their significant sounds (phonemes and syllables), tones, rhythms, and
melodies, enough so that most of us can guess whether a speaker is utter-ing
Japanese or German or French speech even if we do not understand a word of any
of these languages. The amazing fact is that newborn infants can do almost as
well. Babies’ responsiveness can be measured by an ingenious method that takes
advantage of the fact that, while newborns can do very few things voluntarily,
one of their earliest talents—and pleasures—is sucking at a nipple. In one
study, a nonnutritive nipple (or “pacifier”) was connected to a recording
device such that every time the baby sucked, a bit of French speech was heard
coming from a nearby loudspeaker. The 4-day-old French babies rapidly
discovered that they had the power to elicit this speech just by sucking, and
they sucked faster and faster to hear more of it. After a few minutes,
how-ever, they apparently got bored, and therefore the sucking rate decreased.
Now the experimenter switched the speech com-ing from the microphone from
French to English. Did these neonates notice? The answer is yes. When the
switch was made, their interest was reawakened, and they began sucking faster
and faster again (they dishabituated).
To perfect the experimental proof, the same recordings were flown to the United
States, and the experiment was repeated with 4-day-old American babies, with
the same result. American newborns also can and do discriminate between English
and French speech. Indeed, by 2 months of age, not only do infants make these
discriminations, but now they become linguisti-cally patriotic and listen
longer when their own native language is being spoken (Nazzi, Bertoncini, &
Mehler, 1998; see also Figure 10.23).
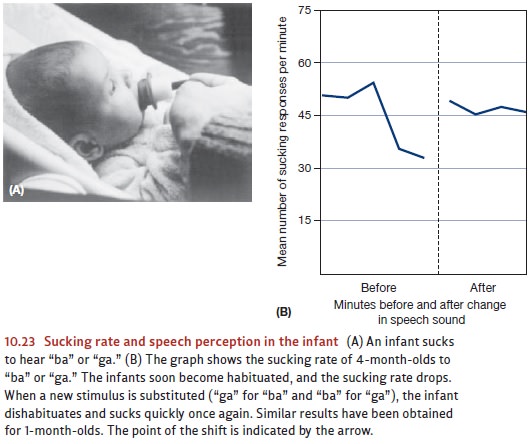
What is it about the native language that is attracting these infants’ attention at these earliest ages? It cannot be the meanings of words, because they as yet do not know any. Evidently the first feature that babies are picking up about their native tongue has to do with the characteristic rhythms of speech in that language (Darwin, 1877; Endress, Nespor, & Mehler, 2009; J. L. Morgan, 1996).
By the age of 1 or 2 months,
before they can even sit up unaided, infants
also become sensitive
to distinctions between
phonemes (Eimas, Siqueland, Jusczyk,
and Vigorito, 1971).
At first, infants respond to just about all sound
distinctions made in any language, and so Japanese babies can detect the
distinction between la versus ra as easily as American babies, despite the
fact that this contrast is not readily discerned by adult Japanese speakers.
However, these per- ceptual abilities erode if
they are not exercised, and so infants lose the ability to make
distinctions that are not used in their language community. Thus,
Japanese infants gradually
stop distinguishing between la and ra. In the same way, American infants stop distinguishing between
two different k sounds that are
perceptually distinct to Arabic speakers. By the age of 12 months, just as true
speech begins, sensitivity to foreign contrasts has diminished sig-nificantly,
as the baby recalibrates to listen specifically for the particulars of the
lan-guage to which she is being exposed (Werker, 1995; Figure 10.24).

BUILDING THE MORPHEME AND WORD UNITS FROM THE SEPARATE SOUNDS AND SYLLABLES
Infants must also find the
boundaries between words. Often it is a challenge to do so, as we see from
errors that children sometimes make along the way. English-speaking toddlers
often reach their arms up to their mothers and fathers, plaintively crying out,
“Ca-ree-oo.” This is, apparently, an infant pronunciation of carry you, but we know from other
evidence that the children are not mixed up as to the words you and me, nor do they have an urge to lift and transport their parent.
Where, then, does this odd usage come from? The children have repeatedly heard
their caregivers ask them, “Do you want me to carry you?” and they apparently
perceived this utterance to end in a single three-syllable word that is
pronounced carreeoo—and means Carry me!
These kinds of errors often
persist unnoticed for years. For instance, one 7-year-old, carefully writing
her first story about a teacher, spelled out Class be smissed!—showing that she had falsely thought there was a
word boundary within the word dismissed
(L Gleitman, H. Gleitman, & Shipley, 1972). These word-segmentation
problems come about because, as we noted earlier, spoken morphemes are not
uttered with silent gaps between them, unlike the case for writing, where gaps
(white spaces) demarcate the words. The right question, then, is not, How come
learners make some mistakes in find-ing word boundaries? but rather, How come
they get these right most of the time? The answer appears to be that infants
mentally register which syllables occur right next to each other with unusual
frequency. For instance, the syllables rab
and it often occur next to each
other; this is because together they form the frequent word rabbit. But stub fol-lowed by it is
much rarer, because there does not happen to be a word in English pro-nounced stubbit. Beginning well before infants
understand any meaningful words at all, they are sensitive to these frequencies
of co-occurrence. This process has been demon-strated experimentally with
artificial syllable sequences. Infants heard a 2-minute tape recording in which
syllables were spoken in a monotonous tone, with no pauses in between the
syllables. But there was a pattern. The experimenters had decided in advance to
designate the sequence “pabiku” as a word. Therefore, they arranged the sequences
so that if the infant heard “pabi,” then “ku” was sure to follow (just as, in
ordinary circum-stances, hearing “rab” is a good predictor that one is about to
hear “it”). For other sylla-bles and syllable pairs, there was no invariant
sequencing. Astonishingly, the babies detected these patterns and their
frequencies. In a subsequent test, they showed no evi-dence of surprise if they
heard the string “pabikupabikupabiku.” From the babies’ point of view, this
simply repeated a pattern they already knew. However, the babies did show
surprise if they were presented with the string “tudarotudarotudaro.” This was
not a pat-tern they had heard before, although they had heard each of its
syllables many times. Thus, the babies had learned the vocabulary of this made-up
language. They had detected the statistical pattern of which syllables followed
which, despite their rather brief, entirely passive exposure to these sounds
and despite the absence of any supporting cues such as pauses or meanings that
go with the sounds (Aslin, Saffran, & Newport, 1998; G. F. Marcus, Vijayan,
Bandi Rao, & Vishton, 1999; Saffran, 2003; Xu & Garcia, 2008).
Related Topics