Chapter: Artificial Intelligence
Clustering and Types of Clustering
CLUSTERING
Clustering is a division of data into groups of similar objects.
Representing the data by fewer clusters necessarily loses certain fine details,
but achieves simplification. It models data by its clusters. Data modeling puts
clustering in a historical perspective rooted in mathematics, statistics and
numerical analysis. From a machine learning perspective clusters correspond to
hidden patterns, the search for clusters in unsupervised learning and the
resulting system represents a data concept. From a practical perspective,
clustering plays an outstanding role in data mining applications such as
scientific data exploration, information retrieval and text mining, spatial database
applications, web analysis, marketing, medical diagnostics, computational
biology and many others.
Clustering is the subject of active research in several fields such as
statistics, pattern recognition and machine learning. Clustering is the classification
of similar objects into different group. We can also define clustering is the
unsupervised learning of a hidden data concept. Besides the term data
clustering, there are a number of terms with similar meanings, including
cluster analysis, automatic classification, numerical taxonomy, and typological
analysis.
Types of Clustering
Categorization of clustering algorithms is neither straight forward nor
canonical. Data clustering algorithms can be hierarchical or partitional.
Two-way clustering, co-clustering or bi-clustering are the names for clustering
where not only the objects are clustered but also the features of the objects.
We provide a classification of clustering algorithms listed below.
Clustering Algorithms
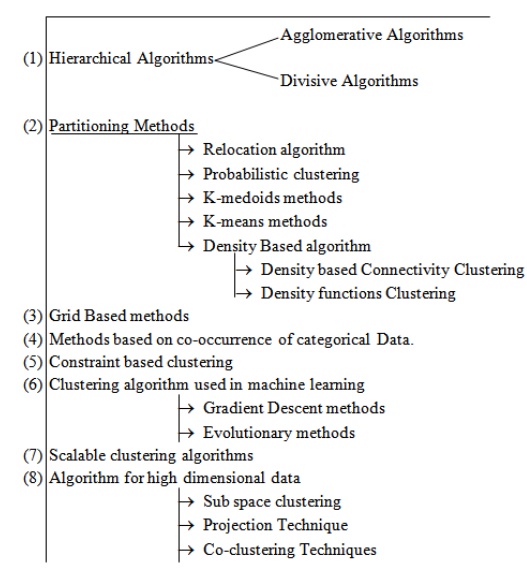
Different Clustering Algorithms
Related Topics