Chapter: Artificial Intelligence
Integrating knowledge and memory
Integrating knowledge and memory
Integrating new knowledge in traditional data bases
is accomplished by simply adding an item to its key location, deleting an item
from a key directed location, or modifying fields of an existing item with
specific input information.
When an item in inventory is replaced with a new
one, its description is changed accordingly. When an item is added to memory,
its index is computed and it is stored at the corresponding address
More sophisticated memory systems will continuously
monitor a knowledge base and make inferred changes as appropriate
A more comprehensive management system will perform
other functions as well, including the formation of new conceptual structures,
the computation and association of casual linkages between related concepts,
generalization of items having common features and the formation of specialized
conceptual categories and specialization of concepts that have been over
generalized
Hypertext
Hypertext systems are examples of information
organized through associative links, like associative networks
These systems are interactive window systems
connected to a database through associative links
Unlike normal text which is read in linear fashion,
hypertext can be browsed in a nonlinear way by moving through a network of
information nodes which are linked bidirectionally through associative
Users of hypertext systems can wander through the
database scanning text and graphics, creating new information nodes and
linkages or modify existing ones
This approach to documentation use is said to more
closely match the cognitive process
It provides a new approach to information access
and organization for authors, researchers and other users of large bodies of
information
Memory
organization system
HAM, a
model of memory
One of the earliest computer models of memory was
the Human Associative memory (HAM) system developed by John Anderson and Gordon
Bower
This memory is organized as a network of
prepositional binary trees
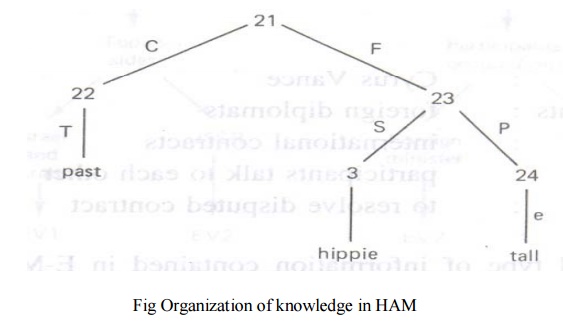
An example of a simple tree which represents the
statement “In a park s hippie touched a debutante” is illustrated in Fig 9.5
When an informant asserts this statement to HAM,
the system parses the sentence and builds a binary tree representation
Node in the tree are assigned unique numbers, while
links are labeled with the
following functions:
C: context for tree fact P: predicate
e: set membership R:
relation
F: a fact S:
subject
L: a location T:
time
object
As HAM is informed of new sentences, they are
parsed and formed into new tree-like memory structures or integrated with
existing ones
For example, to add the fact that the hippie was
tall, the following subtree is attached to the tree structure of Fig below by
merging the common node hippie (node 3) into a single node
When HAM is posed with a query, it is formed into a
tree structure called a probe. This structure is then matched against existing
memory structures for the best match
The structure with the closest match is used to
formulate an answer to the query
Matching is accomplished by first locating the leaf
nodes in memory that match leaf nodes in the probe
The corresponding links are then checked to see if
they have the same labels and in the same order
The search process is constrained by searching only
node groups that have the same relation links, based on recency of usage
The search is not exhaustive and nodes accessed
infrequently may be forgotten
Access to nodes in HAM is accomplished through word
indexing in LISP
Memory
Organization with E-MOPs
One system was developed by Janet Kolodner to study
problems associated with the retrieval and organization of reconstructive
memory, called CYRUS (Computerized Yale Retrieval and Updating System) stores
episodes from the lives of former secretaries of state Cyrus Vance and Edmund
Muskie
The episodes are indexed and stored in long term
memory for subsequent use in answering queries posed in English
The basic memory model in CYRUS is a network
consisting of Episodic Memory Organization Packets (E-MOPs)
Each such E-MOP is a frame-like node structure
which contains conceptual information related to different categories of
episodic events
E-MOP are indexed in memory by one or more
distinguishing features. For example, there are basic E-MOPs for diplomatic
meetings with foreign dignitaries, specialized political conferences,
traveling, state dinners as well as other basic events related to diplomatic
state functions
This diplomatic meeting E-MOP called $MEET,
contains information which is common to all diplomatic meeting events
The common information which characterizes such as
E-MOP is called its content
For example, $MEET might contain the following
information:
A second type of information contained in E-MOPs
are the indices which index either individual episodes or other E-MOPs which
have become specializations of their parent E-MOPs
A typical $MEET E-MOP which has indices to two
particular event meetings EV1 and EV2, is illustrated in Fig 9.6
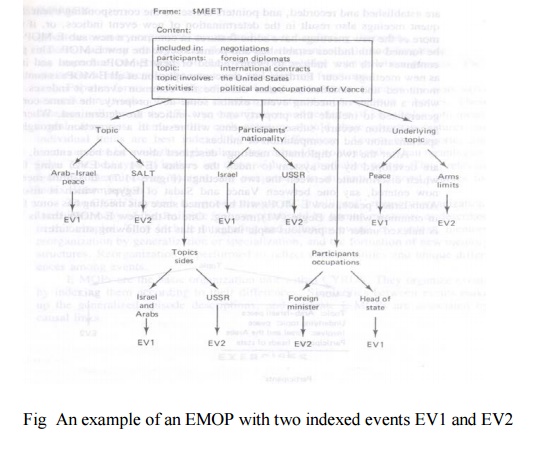
For example, one of the meetings indexed was
between Vance and Gromyko of the USSR in which they discussed SALT. This is
labeled as event EV1 in the figure. The second meeting was between Vance and
Begin of Israel in which they discussed Arab-Israeli peace. This is labeled as
event EV2
Note that each of these events can be accessed
through more than one feature (index). For example, EV1 can be located from the
$MEET event through a topic value of “Arab-Israel peace,” through a
participants’ nationality value of “Israel,” through a participants’ occupation
value of “head of state,” and so on
As new diplomatic meetings are entered into the
system, they are either integrated with the $MEET E-MOP as a separately indexed
event or merged with another event to form a new specialized meeting E-MOP.
When several events belonging to the same MOP
category are entered, common event features are used to generalize the E-MOP.
This information is collected in the frame contents. Specialization may also be
required when over-generalization has occurred. Thus, memory is continually
being reorganized as new facts are entered.
This process prevents the addition of excessive
memory entries and much redundancy which would result if every event entered
resulted in the addition of a separate event
Reorganization can also cause forgetting, since
originally assigned indices may be changed when new structures are formed
When this occurs, an item cannot be located, so the
system attempts to derive new indices from the context and through other indices
by reconstructing related events
The key issues in this type of the organizations
are:
The selection and computation of good indices for
new events so that similar events can be located in memory for new event
integration
Monitoring and reorganization of memory to
accommodate new events as they occur
Access of the correct event information when
provided clues for retrieval
Related Topics