Chapter: Artificial Intelligence
Indexing and retrieval techniques
Indexing and retrieval techniques
The Frame
Problem
One tricky aspect of systems that must function in
dynamic environments is due to the so called frame problem. This is the problem
of knowing what changes have and have not taken place following some action.
Some changes will be the direct result of the action. Other changes will be the
result of secondary or side effects rather than the result of the action. Foe
example, if a robot is cleaning the floors in a house, the location of the
floor sweeper changes with the robot even though this is not explicitly stated.
Other objects not attached to the robot remain in their original places. The
actual changes must somehow be reflected in memory, a fear that requires some
ability to infer. Effective memory organization and management methods must
take into account effects caused by the frame problem
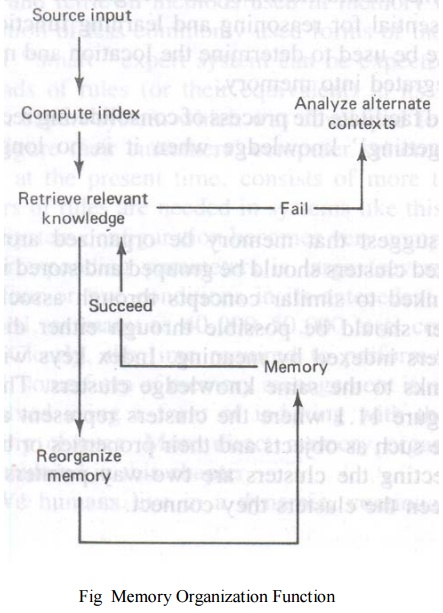
The three basic problems related to knowledge
organization:
classifying and computing indices for input information
presented to system
access and retrieval of knowledge from mrmory
through the use of the computed indices
the reorganization of memory structures when
necessary to accommodate additions, revisions and forgetting. These functions
are depicted in Fig 9.1
When a knowledge base is too large to be held in
main memory, it must be stored as a file in secondary storage (disk, drum or
tape).
Storage and retrieval of information in secondary
memory is then performed through the transfer of equal-size physical blocks
consisting of between 256 and 4096 bytes.
When an item of information is retrieved or stored,
at least one complete block must be transferred between main and secondary
memory.
The time required to transfer a block typically ranges
between 10ms and 100ms, about the same amount of time required to sequentially
searching the whole block for an item.
Grouping related knowledge together as a unit can
help to reduce the number of block transfers, hence the total access time
An example of effective grouping can be found in
some expert system KB organizations
Grouping together rules which share some of the
same conditions and conclusions can reduce block transfer times since such
rules are likely to be needed during the same problem solving session
Collecting rules together by similar conditions or
content can help to reduce the number of block transfers required
Indexed
Organization
While organization by content can help to reduce
block transfers, an indexed organization scheme can greatly reduce the time to
determine the storage location of an item
Indexing is accomplished by organizing the
information in some way for easy access
One way to index is by segregating knowledge into
two or more groups and storing the locations of the knowledge for each group in
a smaller index file
To build an indexed file, knowledge stored as units
is first arranged sequentially by some key value
The key can be any chosen fields that uniquely
identify the record
A second file containing indices for the record
locations is created while the sequential knowledge file is being loaded
Each physical block in this main file results in
one entry in the index file
The index file entries are pairs of record key
values and block addresses
The key value is the key of the first record stored
in the corresponding block
To retrieve an item of knowledge from the main
file, the index file is searched to find the desired record key and obtain the
corresponding block address
The block is then accessed using this address.
Items within the block are then searched sequentially for the desired record
An indexed file contains a list of the entry pairs
(k,b) where the values k are the keys of the first record in each block whose
starting address is b
Fig 9.2 illustrates the process used to locate a
record using the key value of 378

The largest key value less than 378 (375) gives the
block address (800) where the item will be found
Once the 800 block has been retrieved, it can be
searched linearly to locate the record with key value 378. this key could be
any alphanumeric string that uniquely identifies a block, since such strings
usually have a collation order defined by their code set
If the index file is large, a binary search can be
used to speed up the index file search
A binary search will significantly reduce the
search time over linear search when the number of items is not too small
When a file contains n records, the average time
for a linear search is proportional to n/2 compared to a binary search time on
the order of ln2(n)
Further reductions in search time can be realized
using secondary or higher order arranged index files
In this case the secondary index file would contain
key and block address pairs for the primary index file
Similar indexing would apply for higher order
hierarchies where a separate file is used for each level
Both binary search and hierarchical index file
organization may be needed when the KB is a very large file
Indexing in LISP can be implemented with property
lists, A-lists, and/or hash tables. For example, a KB can be partitioned into
segments by storing each segment as a list under the property value for that
segment
Each list indexed in this way can be found with the
get property function and then searched sequentially or sorted and searched
with binary search methods
A hash-table is a special data structure in LISP
which provides a means of rapid access through key hashing
Hashed
Files
Indexed organizations that permit efficient access
are based on the use of a hash function
A hash function, h, transforms key values k into
integer storage location indices through a simple computation
When a maximum number of items C are to stored, the
hashed values h(k) will range from 0 to C – 1. Therefore, given any key value
k, h(k) should map into one of 0…C – 1
An effective hash function can be computed by
choosing the largest prime number p less than or equal to C, converting the key
value k into an integer k’ if necessary, and then using the value k’ mod p as
the index value h
For example, if C is 1000, the largest prime less
than C is p = 997. thus, if the record key value is 123456789, the hashed value
is h = (k mod 997) = 273
When using hashed access, the value of C should be
chosen large enough to accommodate the maximum number of categories needed
The use of the prime number p in the algorithm
helps to insure that the resultant indices are somewhat uniformly distributed
or hashed throughout the range 0 . . . C – 1
This type of organization is well suited for groups
of items corresponding to C different categories
When two or more items belong to the same category,
they will have the same hashed values. These values are called synonyms
One way to accommodate collisions is with data
structures known as buckets
A bucket is a linked list of one or more items,
where each item is record, block, list or other data strucyure
The first item in each bucket has an address
corresponding to the hashed address
Fig 9.3 illustrates a form of hashed memory
organization which uses buckets to hold all items with the same hashed key
value
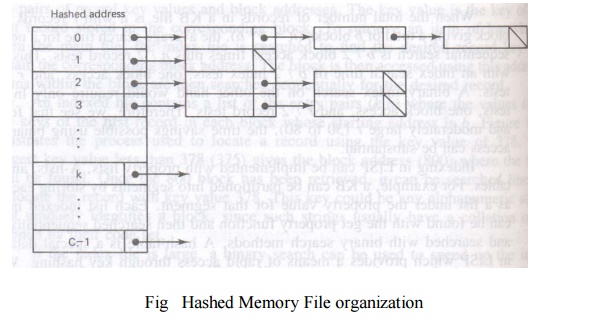
The address of each bucket in this case is the
indexed location in an array
Conceptual
Indexing
A better approach to indexed retrieval is one which
makes use of the content or meaning associated with the stored entities rather
than some nonmeaningful key value
This suggests the use of indices which name and
define the entity being retrieved. Thus, if the entity is an object, its name
and characteristic attributes would make meaningful indices
If the entity is an abstract object such as a
concept, the name and other defining traits would ne meaningful as indices
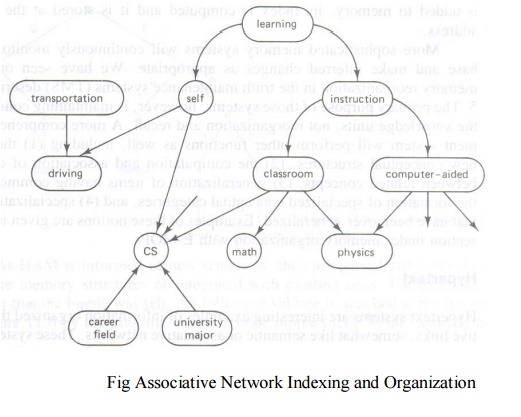
Nodes within the network correspond to different
knowledge entities, whereas the links are indices or pointers to the entities
Links connecting two entities name the association
or relationship between them
The relationship between entities may be defined as
a hierarchical one or just through associative links
As an example of an indexed network, the concept of
computer science CS should be accessible directly through the CS name or
indirectly through associative links like a university major, a career field,
or a type of classroom course
These notions are illustrated in Fig 9.4
Object attributes can also serve as indices to
locate items based on the attribute values
In this case, the best attribute keys are those
which provide the greatest discrimination among objects within the same
category
For example, suppose we wish to organize knowledge
by object types. In this case, the choice of attributes should depend on the
use intended for the knowledge. Since objects may be classified with an
unlimited number of attributes , those attributes which are most discriminable
with respect to the concept meaning should be chosen
Related Topics