Chapter: Artificial Intelligence
Types of Parsing
PARSING PROCESS
Parsing is the term used to describe the process of automatically
building syntactic analysis of a sentence in terms of a given grammar and
lexicon. The resulting syntactic analysis may be used as input to a process of
semantic interpretation. Occasionally, parsing is also used to include both
syntactic and semantic analysis. The parsing process is done by the parser. The
parsing performs grouping and labeling of parts of a sentence in a way that
displays their relationships to each other in a proper way.
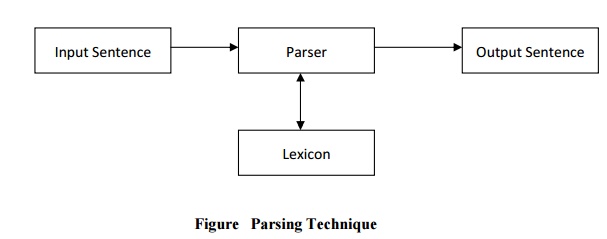
The parser is a computer program which accepts the natural language
sentence as input and generates an output structure suitable for analysis. The
lexicon is a dictionary of words where each word contains some syntactic, some
semantic and possibly some pragmatic information. The entry in the lexicon will
contain a root word and its various derivatives. The information in the lexicon
is needed to help determine the function and meanings of the words in a
sentence. The basic parsing technique is shown in figure .
Generally in computational linguistics the lexicon supplies paradigmatic
information about words including part of speech labels, irregular plurals and
sub categorization information for verbs. Traditionally, lexicons were quite
small and were constructed largely by hand. The additional information being
added to the lexicon increase the complexity of the lexicon. The organization
and entries of a lexicon will vary from one implementation to another but they
are usually made up of variable length data structures such as lists or records
arranged in alphabetical order. The word order may also be given in terms of
usage frequency so that frequently used words like ŌĆ£aŌĆØ, ŌĆ£theŌĆØ and ŌĆ£anŌĆØ will
appear at the beginning of the list facilitating the search. The entries in a
lexicon could be grouped and given word category (by articles, nouns, pronouns,
verbs, adjectives, adverbs and so on) and all words contained within the
lexicon listed within the categories to which they belong. The entries are like
a, an (determiner), be (verb), boy, stick, glass (noun), green, yellow, red
(adjectives), I, we, you, he, she, they (pronouns) etc.
In most contemporary grammatical formalisms, the output of parsing is
something logically equivalent to a tree, displaying dominance and precedence
relations between constituents of a sentence. Parsing algorithms are usually
designed for classes of grammar rather than tailored towards individual
grammars.
Types of Parsing
The parsing technique can be categorized into two types such as
1.
Top down Parsing
2.
Bottom up Parsing
Let us discuss about these two parsing techniques and how they will work
for input sentences.
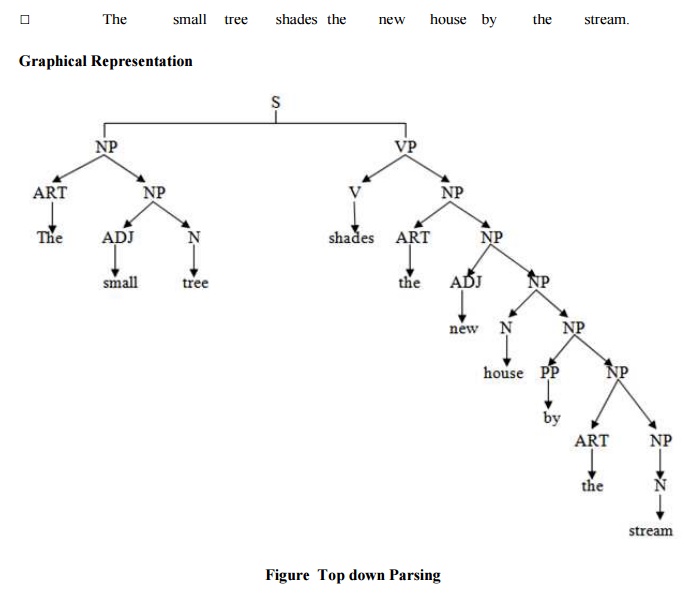
1 Top down Parsing
Top down parsing starts with the starting symbol and proceeds towards
the goal. We can say it is the process of construction the parse tree starting
at the root and proceeds towards the leaves. It is a strategy of analyzing
unknown data relationships by hypothesizing general parse tree structures and
then considering whether the known fundamental structures are compatible with
the hypothesis. In top down parsing words of the sentence are replaced by their
categories like verb phrase (VP), Noun phrase (NP), Preposition phrase (PP),
Pronoun (PRO) etc. Let us consider some examples to illustrate top down
parsing. We will consider both the symbolical representation and the graphical
representation. We will take the words of the sentences and reach at the
complete sentence. For parsing we will consider the previous symbols like PP,
NP, VP, ART, N, V and so on. Examples of top down parsing are LL
(Left-to-right, left most derivation), recursive descent parser etc.
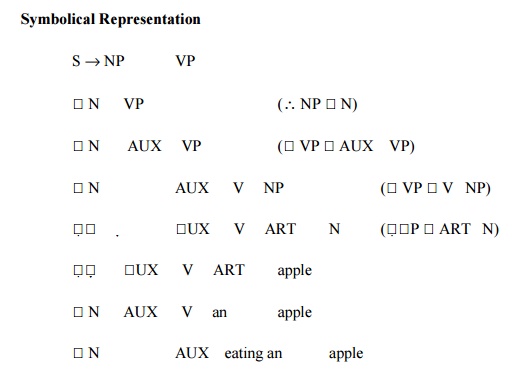
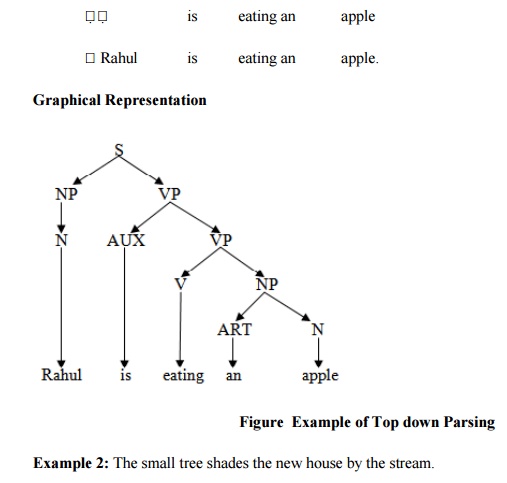
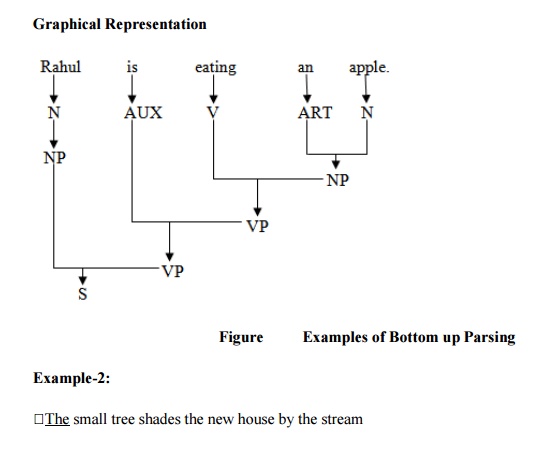
Example 1: Rahul is eating an apple.
2. Bottom
up Parsing
In this parsing technique the process begins with the sentence and the
words of the sentence is replaced by their relevant symbols. This process was
first suggested by Yngve (1955). It is also called shift reducing parsing. In
bottom up parsing the construction of parse tree starts at the leaves and proceeds
towards the root. Bottom up parsing is a strategy for analyzing unknown data
relationships that attempts to identify the most fundamental units first and
then to infer higher order structures for them. This process occurs in the
analysis of both natural languages and computer languages. It is common for
bottom up parsers to take the form of general parsing engines that can wither
parse or generate a parser for a specific programming language given a specific
of its grammar.
A generalization of this type of algorithm is familiar from computer
science LR (k) family can be seen as shift reduce algorithms with a certain
amount (ŌĆ£KŌĆØ words) of look ahead to determine for a set of possible states of
the parser which action to take. The sequence of actions from a given grammar
can be pre-computed to give a ŌĆśparsing tableŌĆÖ saying whether a shift or reduce
is to be performed and which state to go next. Generally bottom up algorithms
are more efficient than top down algorithms, one particular phenomenon that they
deal with only clumsily are ŌĆ£e mpty rulesŌĆØ: rules in which the right hand side
is the empty string. Bottom up parsers find instances of such rules applying at
every possible point in the input which can lead to much wasted effort. Let us
see some examples to illustrate the bottom up parsing.



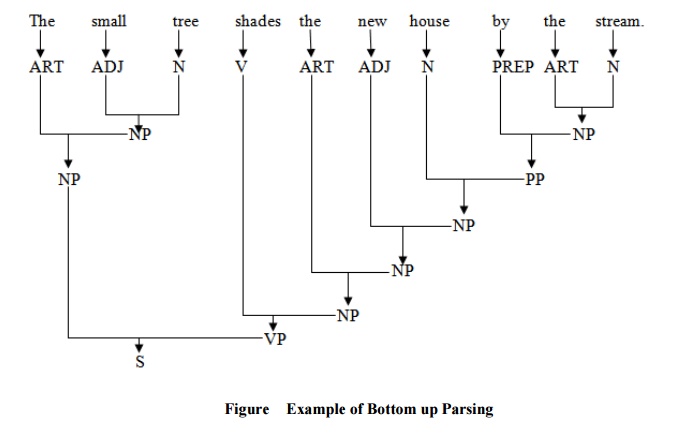
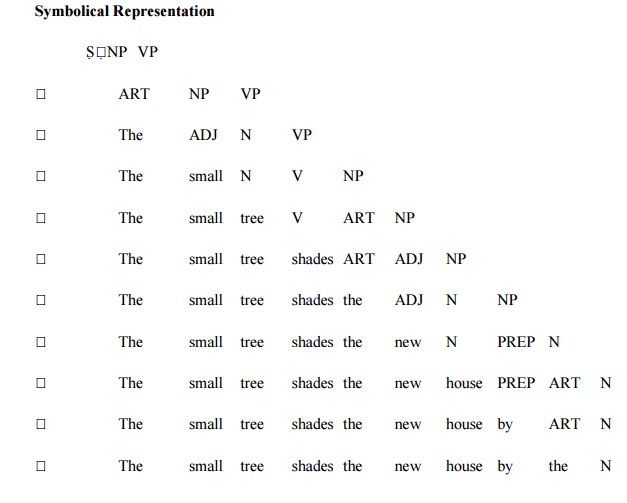
Example-2:
The small tree shades the new house by the stream
ART small tree shades the new house by the stream
ART ADJ tree shades the new house by the stream
ART ADJ N shades the new house by the stream
ART ADJ N V the new house by the stream
ART ADJ N V ART new house by the stream
ART ADJ N V ART ADJ house by the stream
ART ADJ N V ART ADJ N by the stream
ART ADJ N V ART ADJ N PREP the stream
ART ADJ N V ART ADJ N PREP ART stream
ART ADJ N V ART ADJ N PREP ART N
ART ADJ N V ART ADJ N PREP NP
ART ADJ N V ART ADJ N PP
ART ADJ N V ART ADJ NP
ART ADJ N V ART NP
ART ADJ N V NP
ART ADJ N VP
ART NP VP
NP VP
S
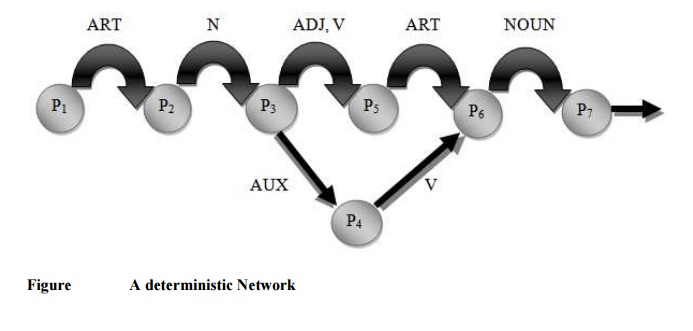
Deterministic Parsing
A deterministic parser is one which permits only one choice for each word category. That means there is only one replacement possibility for every word category. Thus, each word has a different test conditions. At each stage of parsing always the correct choice is to be taken. In deterministic parsing back tracking to some previous positions is not possible. Always the parser has to move forward. Suppose the parser some form of incorrect choice, then the parser will not proceed forward. This situation arises when one word satisfies more than one word categories, such as noun and verb or adjective and verb. The deterministic parsing network is shown in figure.
Non-Deterministic Parsing
The non deterministic parsing allows different arcs to be labeled with the some test. Thus, they can uniquely make the choice about the next arc to be taken. In non deterministic parsing, the back tracking procedure can be possible. Suppose at some extent of point, the parser does not find the correct word, then at that stage it may backtracks to some of its previous nodes and then start parsing. But the parser has to guess about the proper constituent and then backtrack if the guess is later proven to be wrong. So comparative to deterministic parsing, this procedure may be helpful for a number of sentences as it can backtrack at any point of state. A non deterministic parsing network is shown in figure.
Related Topics