Chapter: Security in Computing : Security in Networks
Architecture - Security in Networks
Design and Implementation
Throughout this book we have discussed good
principles of system analysis, design, implementation, and maintenance. Chapter 3, in particular, presented techniques
that have been developed by the software engineering community to improve
requirements, design, and code quality. Concepts from the work of the early
trusted operating systems projects (presented in Chapter
5) have natural implications for networks as well. And assurance,
also discussed in Chapter 5, relates to
networked systems. In general, the Open Web Applications project [OWA02, OWA05]
has documented many of the techniques people can use to develop secure web
applications. Thus, having addressed secure programming from several
perspectives already, we do not belabor the points now.
Architecture
As with so many of the areas
we have studied, planning can be the strongest control. In particular, when we
build or modify computer-based systems, we can give some thought to their
overall architecture and plan to "build in" security as one of the
key constructs. Similarly, the architecture or design of a network can have a
significant effect on its security.
Segmentation
Just as segmentation was a
powerful security control in operating systems, it can limit the potential for
harm in a network in two important ways: Segmentation reduces the number of
threats, and it limits the amount of damage a single vulnerability can allow.
Assume your network
implements electronic commerce for users of the Internet. The fundamental parts
of your network may be
·
a web server, to handle users' HTTP sessions
·
application code, to present your goods and services for purchase
·
a database of goods, and perhaps an accompanying inventory to the
count of stock on hand and being requested from suppliers
·
a database of orders taken
If all these activities were
to run on one machine, your network would be in trouble: Any compromise or
failure of that machine would destroy your entire commerce capability.
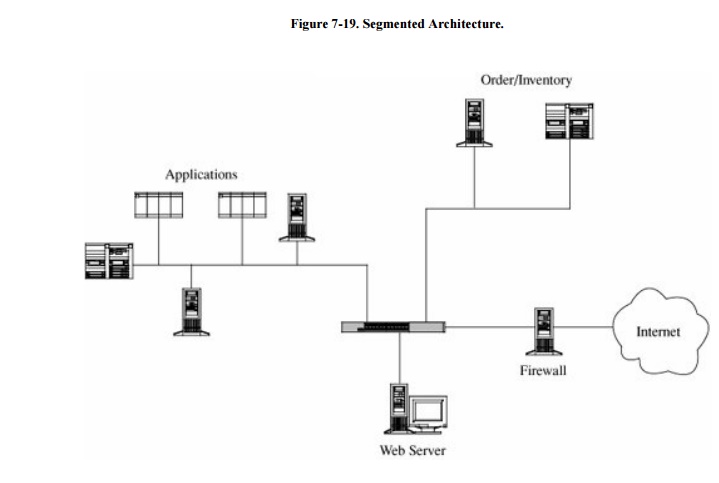
A more secure design uses multiple segments, as
shown in Figure 7-19. Suppose one piece
of hardware is to be a web server box exposed to access by the general public.
To reduce the risk of attack from outside the system, that box should not also
have other, more sensitive, functions on it, such as user authentication or access
to a sensitive data repository. Separate segments and serverscorresponding to
the principles of least privilege and encapsulationreduce the potential harm
should any subsystem be compromised.
Separate access is another
way to segment the network. For example, suppose a network is being used for
three purposes: using the "live" production system, testing the next
production version, and developing subsequent systems. If the network is well
segmented, external users should be able to access only the live system,
testers should access only the test system, and developers should access only
the development system. Segmentation permits these three populations to coexist
without risking that, for instance, a developer will inadvertently change the
production system.
Redundancy
Another key architectural
control is redundancy: allowing a function to be performed on more than one
node, to avoid "putting all the eggs in one basket." For example, the
design of Figure 7-19 has only one web
server; lose it and all connectivity is lost. A better design would have two
servers, using what is called failover mode. In failover mode the servers communicate with each other periodically,
each determining if the other is still active. If one fails, the other takes
over processing for both of them. Although performance is cut approximately in
half when a failure occurs, at least some processing is being done.
Single Points of Failure
Ideally, the architecture
should make the network immune to failure. In fact, the architecture should at
least make sure that the system tolerates failure in an acceptable way (such as
slowing down but not stopping processing, or recovering and restarting
incomplete transactions). One way to evaluate the network architecture's
tolerance of failure is to look for single
points of failure. That is, we should ask if there is a single point in the
network that, if it were to fail, could deny access to all or a significant
part of the network. So, for example, a single database in one location is
vulnerable to all the failures that could affect that location. Good network
design eliminates single points of failure. Distributing the databaseplacing
copies of it on different network segments, perhaps even in different physical
locationscan reduce the risk of serious harm from a failure at any one point.
There is often substantial overhead in implementing such a design; for example,
the independent databases must be synchronized. But usually we can deal with
the failure-tolerant features more easily than with the harm caused by a failed
single link.
Architecture plays a role in
implementing many other controls. We point out architectural features as we
introduce other controls throughout the remainder of this chapter.
Mobile Agents
Mobile code and hostile
agents are potential methods of attack, as described earlier in this chapter.
However, they can also be forces for good. Good agents might look for unsecured
wireless access, software vulnerabilities, or embedded malicious code. Schneider
and Zhou [SCH05]
investigate distributed trust, through a corps
of communicating, state-sharing agents. The idea is straightforward: Just as
with soldiers,
you know some agents will be stopped and others will be subverted by the enemy,
but some agents will remain intact. The corps can recover from Byzantine
failures [LAM82]. Schneider and Zhou propose a design in which no one agent
is critical to the overall success but the overall group can be trusted.
Related Topics