Chapter: Embedded Systems Design : Real-time operating systems
Priority inversion
Priority inversion
It is also possible to get a condition called priority inversion where a
lower priority task can continue running despite there being a higher priority
task active and waiting to preempt.
This can occur if the higher priority task is in some way blocked by the
lower priority task through it having to wait until a message or semaphore is
processed. This can happen for several reasons.
Disabling interrupts
While in the interrupt service routine, all other interrupts are
disabled until the routine has completed. This can cause a problem if another
interrupt is received and held pending. What happens is that the higher
priority interrupt is held pending in favour of the lower priority one — albeit
that it occurred first. As a result, priority inversion takes place until
interrupts are re-enabled at which point the higher priority interrupt will
start its exception processing, thus ending the priority inversion.
One metric of an operating system is the longest period of time that all
interrupts are disabled. This must then be added to any other interrupt latency
calculation to determine the actual latency period.
Message queues
If a message is sent to the operating system to activate a task, many
systems will process the message and then reschedule accordingly. In this way,
the message queue order can now define the task priority. For example, consider
an ISR that sends an unblocking message to two tasks, A and B, that are blocked
waiting for the message. The ISR sends the message for task A first followed by
task B. The ISR is part of the RTOS kernel and therefore may be subject to
several possible conditions:
•
Condition 1
Although the message calls may be completed, their action may be held
pending by the RTOS so that any resulting pre-emption is stopped from switching
out the ISR.
•
Condition 2
The ISR may only be allowed to execute a single RTOS call and in doing
so the operating system itself will clean up any stack frames. The operating
system will then send messages to tasks notifying them of the interrupt and in
this way simulate the interrupt signal. This is normally done through a list.
These conditions can cause priority inversion to take place. With
condition 1, the ISR messages are held pending and proc-essed. The problem
arises with the methodology used by the operating system to process the pending
messages. If it processes all the messages, effectively unblocking both tasks
before instigat-ing the scheduler to decide the next task to run, all is well.
Task B will be scheduled ahead of task A because of its higher priority. The
downside is the delay in processing all the messages before selecting the next
task.
Most operating systems, however, only have a single call to process and
therefore in normal operation do not expect to handle multiple messages. In
this case, the messages are handled indi-vidually so that after the first
message is processed, task A would be unblocked and allowed to execute. The
message for task B would either be ignored or processed as part of the
housekeeping at the next context switch. This is where priority inversion would
occur. The ISR has according to its code unblocked both tasks and thus would
expect the higher priority task B to execute. In practice, only task A is
unblocked and is running, despite it being at a lower priority. This scenario
is a programming error but one that is easy to make.
To get around this issue, some RTOS implementations restrict an ISR to
making either one or no system calls. With no system calls, the operating
system itself will treat the ISR event as an internal message and will unblock
any task that is waiting for an ISR event. With a single system call, a task
would take the responsibility for controlling the message order to ensure that
priority inversion does not take place.
Waiting for a resource
If a resource is shared with a low priority task and it does not release
it, a higher priority task that needs it can be blocked until it is released. A
good example of this is where the interrupt handler is distributed across a
system and needs to access a common bus to handle the interrupt. This can be
the case with a VMEbus system, for example.
VMEbus interrupt messages
VMEbus is an interconnection bus that was developed in the early 1980s
for use within industrial control and other real-time applications. The bus is
asynchronous and is very similar to that of the MC68000. It comprises of a
separate address, data, interrupt and control buses.
If a VMEbus MASTER wishes to inform another that a message is waiting or
urgent action is required, a VMEbus inter-rupt can be generated. The VMEbus
supports seven interrupt priority levels to allow prioritisation of a resource.
Any board can generate an interrupt by asserting one of the levels.
Interrupt handling can either be centralised, and handled by one MASTER, or can
be distributed among many. For multi-processor applications, distributed
handling allows rapid direct communication to individual MASTERs by any board
in the system capable of generating an interrupt: the MASTER that has been
assigned to handle the interrupt requests the bus and starts the interrupt
acknowledgement cycle. Here, careful consideration of the arbitration level
chosen for the MASTER is required. The interrupt response time depends on the
time taken by the handler to obtain the bus prior to the acknowledgement. This
has to be correctly assigned to achieve the required performance. If it has a
low priority, the overall response time may be more than that obtained for a
lower priority interrupt whose handler has a higher arbitration level. The
diagrams below show the relationship for both priority and round robin
arbitration schemes. Again, as with the case with arbitration schemes, the round
robin system has been assumed on average to provide equal access for all the
priority levels.
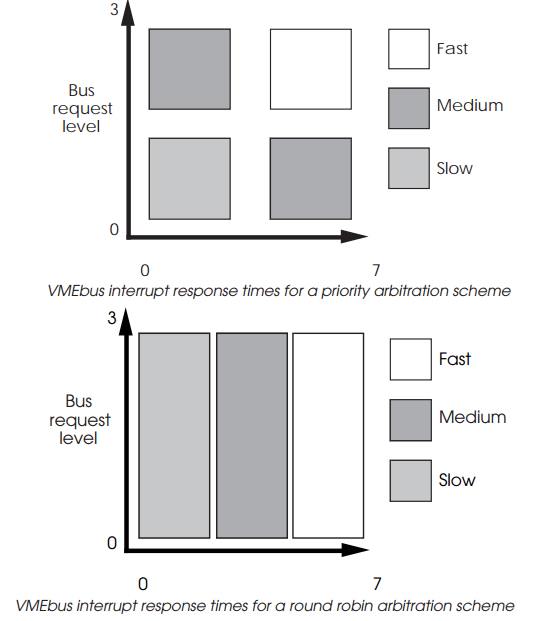
Priority inversion can occur if a lower priority interrupt may be
handled in preference to a higher priority one, simply because of the
arbitration levels. To obtain the best response, high priority interrupts
should only be assigned to high arbitration level MASTERs. The same factors,
such as local traffic on the VMEbus and access time, increase the response time
as the priority level decreases.
VMEbus only allows a maximum of seven separate inter-rupt levels and
this limits the maximum number of interrupt handlers to seven. For systems with
larger numbers of MASTERs, polling needs to be used for groups of MASTERs
assigned to a single interrupt level. Both centralised and distributed
interrupt handling schemes have their place within a multiprocessor sys-tem.
Distributed schemes allow interrupts to be used to pass high priority messages
to handlers, giving a fast response time which might be critical for a
real-time application. For simpler designs, where there is a dominant
controlling MASTER, one handler may be sufficient.
Fairness systems
There are times when the system requires different charac-teristics from
those originally provided or alternatively wants a system response that is not
priority based. This can be achieved by using a fairness system where the bus
access is distributed across the requesting processors. There are various
schemes that are available such as round-robin where access is simply passed
from one processor to another. Other methods can use time sharing where the bus
is given to a processor on the understanding that it must be relinquished
within a maximum time frame.
These type of systems can affect the interrupt response because bus
access is often necessary to service an interrupt.
Related Topics