Chapter: Embedded Systems Design : Real-time operating systems
Linux software structure, Physical and Memory management
Linux software structure
The software structure used within UNIX is very modular, despite its
long development history. It consists of several layers starting with
programming languages, command scripts and applications, shells and utilities,
which provide the interface software or application the user sees. In most
cases, the only difference between the three types of software is their
interaction and end product, although the more naive user may not perceive
this.
The most common software used is the shell, with its commands and
utilities. The shell is used to provide the basic login facilities and system
control. It also enables the user to select application software, load it and
then transfer control to it. Some of its commands are built into the software
but most exist as applications, which are treated by the system in the same way
as a database or other specialised application.
Programming languages, such as C and Fortran, and their related tools
are also applications but are used to write new software to run on the system.
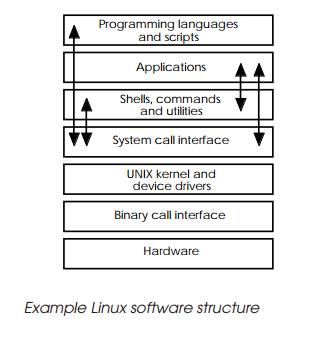
As shown in the diagram, all these layers of software interface with the
rest of the operating system via the system call interface. This provides a set
of standard commands and services for the software above it and enables their
access to the hardware, filing systems, terminals and processor. To read data
from a file, a set of system calls are carried out which locate the file, open
it and transfer the required data to the application needing it. To find out
the time, another call is used, and so on. Having transferred the data, system
calls are used to call the UNIX kernel and special software modules, known as
device drivers, which actually per-form the work required.
Up to this point, the software is essentially working in a standard
software environment, where the actual hardware con-figuration (processor,
memory, peripherals and so on) is still hidden. The hardware dependant software
which actually drives the hardware is located at the binary call interface.
Of all the layers, the kernel is the heart of the operating system and
it is here that the multi-tasking and multi-user aspects of Linux and memory
control are implemented. Control is achieved by allocating a finite amount of
processor time to each process — an application, a user shell, and so on.
When a process starts executing, it will either be stopped involuntarily
(when its CPU time has been consumed) or, if it is waiting for another service
to complete, such as a disk access. The next process is loaded and its CPU time
starts. The scheduler decides which process executes next, depending on how
much CPU time a process needs, although the priority can be changed by the
user. It should be noted that often the major difference between UNIX variants
and/or implementations is the scheduling algo-rithm used.
Processes and standard I/O
One problem facing multi-user operating systems is that of access to I/O
devices, such as printers and terminals. Probably the easiest method for the
operating system is to address all peripher-als by unique names and force
application software to directly name them. The disadvantage of this for the
application is that it could be difficult to find out which peripheral each
user is using, especially if a user may login via a number of different
terminals. It would be far easier for the application to use some generic name
and let the operating system translate these logical names to physical devices.
This is the approach taken by Linux.
Processes have three standard files associated with them: stdin, stdout
and stderr. These are the default input, output and error message files. Other
files or devices can be reassigned to these files to either receive or provide
data for the active process. A list of all files in the current directory can
be displayed on the terminal by typing ls<cr> because the terminal is
automatically assigned to be stdout. To send the same data to a file, ls >
filelist<cr> is entered instead. The extra > filelist redirects the
output of the ls command. In the first case, ls uses the normal stdout file
that is assigned to the terminal and the directory information appears on the
terminal screen. In the second exam-ple, stdout is temporarily assigned to the
file filelist. Nothing is sent to the terminal screen — the data is stored
within the file instead.
Data can be fed from one process directly into another using a ‘pipe’. A
process to display a file on the screen can be piped into another process which
converts all lower case characters to upper case. It can then pipe its data
output into another process, which pages it automatically before displaying it.
This command line can be written as a data file or ‘shell script’, which
provides the commands to the user interface or shell. Shell scripts form a
programming language in their own right and allow complex commands to be
constructed from simple ones. If the user does not like the particular way a
process presents information, a shell script can be written which executes the
process, edits and reformats the data and then presents it. There are two
commonly used shell interfaces: the standard Bourne shell and the ‘C’ shell.
Many application programs provide their own shell which hide the Linux
operating system completely from the user.
Executing commands
After a user has logged onto the system, Linux starts to run the shell
program by assigning stdin to the terminal keyboard and stdout to the terminal
display. It then prints a prompt and waits for a command to be entered. The
shell takes the command line and deciphers it into a command with options, file
names and so on. It then looks in a few standard directories to find the right
program to execute or, if the full path name is used, goes the directory
specified and finds the file. If the file cannot be found, the shell returns an
error message.
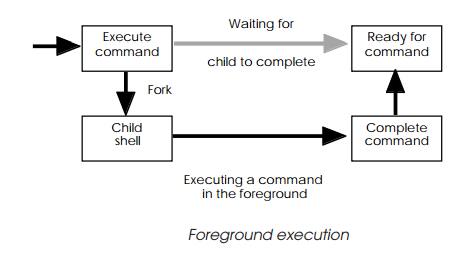
The next stage appears to be a little strange. The shell forks i.e. it
creates a duplicate of itself, with all its attributes. The only difference
between this new child process and its parent is the value returned from the
operating system service that performs the creation. The parent simply waits for
the child process to complete. The child starts to run the command and, on its
comple-tion, it uses the operating system exit call to tell the kernel of its
demise. It then dies. The parent is woken up, it issues another prompt, and the
mechanism repeats. Running programs in this way is called executing in the
foreground and while the child is performing the required task, no other
commands will be ex-ecuted (although they will still be accepted from the
keyboard!).
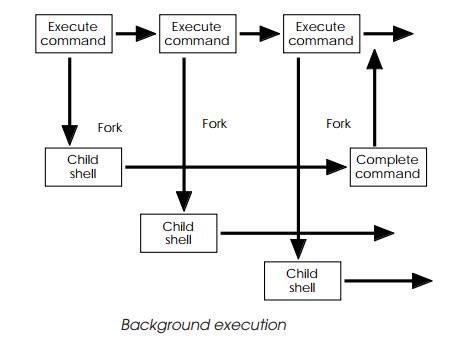
An alternative way of proceeding is to execute the com-mand in
background. This is done by adding an ampersand to the end of the command. The
shell forks, as before, with each com-mand as it is entered — but instead of
waiting for the child to complete, it prompts for the next command. The example
below shows three commands executing in background. As they com-plete, their
output appears on stdout. (To prevent this disrupting a command running in
foreground, it is usual to redirect stdout to a file.) Each child is a process
and is scheduled by the kernel, as necessary.
Physical I/O
There are two classes of physical I/O devices and their names describe
the method used to collect and send data to them. All are accessed by reading
and writing to special files, usually located in the /dev directory, as previously explained. Block de-vices transfer
data in multiples of the system block size. This method is frequently used for
disks and tapes. The other method is called character I/O and is used for
devices such as terminals and printers.
Block devices use memory buffers and pools to store data. These buffers
are searched first to see if the required data is present, rather than going to
the slow disk or tape to fetch it. This gives some interesting user
characteristics. The first is that fre-quently used data is often fetched from
memory buffers rather than disk, making the system response apparently much
better. This effect is easily seen when an application is started a second
time. On its first execution, the system had to fetch it in from disk but now
the information is somewhere in memory and can be accessed virtually
instantaneously. The second characteristic is the performance improvement often
seen when the system RAM is increased. With more system memory, more buffers are
avail-able and the system spends less time accessing the disk.
It is possible to access some block devices directly, without using
memory buffers. These are called raw accesses and are used, for example, when
copying disks.
For devices such as terminals and printers, block transfers do not make
much sense and here character transfers are used. Although they do not use
memory buffers and pools in the same way as block devices, the Linux kernel
buffers requests for single characters. This explains why commands must be
terminated with a carriage return — to tell the kernel that the command line is
now complete and can be sent to the shell.
Memory management
With many users running many different processes, there is a great
potential for problems concerning memory allocation and the protection of users
from accesses to memory and peripherals that are currently being used by other
users of the system. This is especially true when software is being tested
which may attempt to access memory that does not exist or is already being
used. To solve this sort of problem, Linux depends on a memory manage-ment unit
(MMU) — hardware which divides all the memory and peripherals into sections
which are marked as read only, read or write, operating system accesses only, and
so on. If a program tries to write to a read only section, an error occurs
which the kernel can handle. In addition, the MMU can translate the memory
addresses given by the processor to a different address in memory.
Related Topics