Chapter: Embedded Systems Design : Real-time operating systems
Linux
Linux
Linux started as a personal interest project by Linus Torvalds at the
University of Helsinki in Finland to produce an operating system that looked
and felt like UNIX. It was based on work that he had done in porting Minix , an
operating system that had been shipped with a textbook that described its inner
workings.
After much discussion via user groups on the Internet, the first version
of Linux saw the light of day on the 5 October, 1991. While limited in its
abilities — it could run the GNU bash shell and gcc compiler but not much else
— it prompted a lot of interest. Inspired by Linus Torvalds’ efforts, a band of
enthusiasts started to create the range of software that Linux offers today.
While this was progressing, the kernel development continued until some 18
months later, when it reached version 1.0. Since then it has been developed
further with many ports for different processors and platforms. Because of the
large amount of software available for it, it has become a very popular
operating system and one that is often thought off as a candidate for embedded
systems.
However it is based on the interfaces and design of the UNIX operating
system which for various reasons is not consid-ered suitable for embedded
design. If this is the case, how is it that Linux is now forging ahead in the
embedded world. To answer this question, it is important to understand how it
came about and was developed. That means starting with the inspiration behind
Linux, the UNIX operating system.
Origins and beginnings
UNIX was first described in an article published by Ken Thompson and
Dennis Ritchie of Bell Research Labs in 1974, but its origins owe much to work
carried out by a consortium formed in the late 1960s, by Bell Telephones,
General Electric and the Massachusetts Institute of Technology, to develop
MULTICS — a MULTIplexed Information and Computing Service. Their goal was to
move away from the then traditional method of users submitting work in as
punched cards to be run in batches — and receiving their results several hours
(or days!) later. Each piece of work (or job) would be run sequentially — and
this combination of lack of response and the punched card medium led to many
frustrations — as anyone who has used such machines can con-firm. A single
mistake during the laborious task of producing punched cards could stop the job
from running and the only help available to identify the problem was often a
‘syntax error’ mes-sage. Imagine how long it could take to debug a simple
program if it took the computer several hours to generate each such mes-sage!
The idea behind MULTICS was to generate software which would allow a
large number of users simultaneous access to the computer. These users would
also be able to work interactively and on-line in a way similar to that
experienced by a personal computer user today. This was a fairly revolutionary
concept. Computers were very expensive and fragile machines that re-quired
specially trained staff to keep other users away from and protect their machine. However, the project was
not as successful as had been hoped and Bell dropped out in 1969. The
experienced gained in the project was turned to other uses when Thompson and
Ritchie designed a computer filing system on the only ma-chine available — a
Digital Equipment PDP-7 mini computer.
While this was happening, work continued on the GE645 computer used in
the MULTICS project. To improve performance and save costs (processing time was
very expensive), they wrote a very simple operating system for the PDP-7 to
enable it to run a space travel game. This operating system, which was
essentially the first version of UNIX, included a new filing system and a few
utilities.
The PDP-7 processor was better than nothing — but the new software
really cried out for a better, faster machine. The problem faced by Thompson
and Ritchie was one still faced by many today. It centred on how to persuade
management to part with the cash to buy a new computer, such as the newer
Digital Equipment Company’s PDP-11. Their technique was to interest the Bell
legal department in the UNIX system for text processing and use this to justify
the expenditure. The ploy was successful and UNIX development moved along.
The next development was that of the C programming language, which
started out as an attempt to develop a FORTRAN language compiler. Initially, a
programming language called B which was developed, which was then modified into
C. The development of C was crucial to the rapid movement of UNIX from a niche
within a research environment to the outside world.
UNIX was rewritten in C in 1972 — a major departure for an operating
system. To maximise the performance of the computers then available, operating
systems were usually written in a low level assembly language that directly
controlled the processor. This had several effects. It meant that each computer
had its own operating system, which was unique, and this made application
programs hardware dependent. Although the applications may have been written in
a high level language (such as FORTRAN or BASIC) which could run on many
different machines, differences in the hardware and operating systems would
frequently prevent these applications from being moved between systems. As a
result, many man hours were spent porting software from one computer to another
and work around this computer equivalent of the Tower of Babel.
By rewriting UNIX in C, the painstaking work of porting system software
to other computers was greatly reduced and it became feasible to contemplate a
common operating system run-ning on many different computers. The benefit of
this to users was a common interface and way of working, and to software
develop-ers, an easy way to move applications from one machine to another. In
retrospect, this decision was extremely far sighted.
The success of the legal text processing system, coupled with a concern
within Bell about being tied to a number of computer vendors with incompatible
software and hardware, resulted in the idea of using the in-house UNIX system
as a standard environment. The biggest advantage of this was that only one set
of applications needed to be written for use on many different computers. As
UNIX was now written in a high level language, it was a lot more feasible to
port it to different hardware platforms. Instead of rewriting every application
for each compu-ter, only the UNIX operating system would need to be written for
each machine — a lot less work. This combination of factors was too good an
opportunity to miss. In September 1973, a UNIX Development Support group was
formed for the first UNIX applications, which updated telephone directory
information and intercepted calls to changed numbers.
The next piece of serendipity in UNIX development was the result of a
piece of legislation passed in 1956. This prevented AT&T, who had taken
over Bell Telephone, from selling computer products. However, the papers that
Thompson and Ritchie had published on UNIX had created a quite a demand for it
in aca-demic circles. UNIX was distributed to universities and research
institutions at virtually no cost on an ‘as is’ basis — with no support. This
was not a problem and, if anything, provided a motivating challenge. By 1977,
over 500 sites were running UNIX.
By making UNIX available to the academic world in this way, AT&T had
inadvertently discovered a superb way of mar-keting the product. As low cost
computers became available through the advent of the mini computer (and, later,
the micro-processor), academics quickly ported UNIX and moved the rap-idly
expanding applications from one machine to another. Often, an engineer’s first
experience of computing was on UNIX systems with applications only available on
UNIX. This experience then transferred into industry when the engineer
completed training. AT&T had thus developed a very large sales force
promoting its products — without having to pay them! A situation that many
marketing and sales groups in other companies would have given their right arms
for. Fortunately for AT&T, it had started to licence and protect its
intellectual property rights without restricting the flow into the academic
world. Again, this was either far sighted or simply common sense, because they
had to wait until 1984 and more legislation changes before entering the
computer market and starting to reap the financial rewards from UNIX.
The disadvantage of this low key promotion was the ap-pearance of a
large number of enhanced variants of UNIX which had improved appeal — at the
expense of some compatibility. The issue of compatibility at this point was
less of an issue than today.
UNIX was provided with no support and its devotees had to be able to
support it and its applications from day one. This self sufficiency meant that
it was relatively easy to overcome the slight variations between UNIX
implementations. After all, most of the application software was written and
maintained by the users who thus had total control over its destiny. This is
not the case for commercial software, where hard economic factors make the
decision for or against porting an application between systems.
With the advent of microprocessors like the Motorola MC68000 family, the
Intel 8086 and the Zilog Z8000, and the ability to produce mini computer
performance and facilities with low cost silicon, UNIX found itself a low cost
hardware platform. During the late 1970s and early 1980s, many UNIX systems
ap-peared using one of three UNIX variants.
XENIX was a UNIX clone produced by Microsoft in 1979 and ported to all
three of the above processors. It faded into the background with the advent of
MS-DOS, albeit temporarily. Sev-eral of the AT&T variants were combined
into System III, which, with the addition of several features, was later to
become System V. The third variant came from work carried at out at Berkeley
(University of California), which produced the BSD versions destined to became
a standard for the Digital Equipment Compa-ny’s VAX computers and throughout
the academic world.
Of the three versions, AT&T were the first to announce that they
would maintain upward compatibility and start the lengthy process of defining
standards for the development of future versions. This development has culminated
in AT&T System V release 4, which has effectively brought the System V,
XENIX and BSD UNIX environments together.
What distinguishes UNIX from other operating systems is its wealth of
application software and its determination to keep the user away from the
physical system resources. There are many compilers, editors, text processors,
compiler construction aids and communication packages supplied with the basic
release. In addi-tion, packages from complete CAD and system modelling to
integrated business office suites are available.
The problem with UNIX was that it was quite an expensive operating
system to buy. The hardware in many cases was specific to a manufacturer and
this restricted the use of UNIX. What was needed was an alternative source of
UNIX. With the advent of Linux, this is exactly what happened.
Inside Linux
The key to understanding Linux as an operating system is to understand
UNIX and then to grasp how much the operating system protects the user from the
hardware it is running on. It is very difficult to know exactly where the
memory is in the system, what a disk drive is called and other such
information. Many facets of the Linux environment are logical in nature, in
that they can be seen and used by the user — but their actual location,
structure and functionality is hidden. If a user wants to run a 20 Mbyte
program on a system, UNIX will use its virtual memory capability to make the
machine behave logically like one with enough memory — even though the system
may only have 4 Mbytes of RAM installed. The user can access data files without
knowing if they are stored on a floppy or a hard disk — or even on another
machine many miles away and connected via a network. UNIX uses its facilities
to present a logical picture to the user while hiding the more physical aspects
from view.
The Linux file system
Linux like UNIX has a hierarchical filing system which contains all the
data files, programs, commands and special files that allow access to the
physical computer system. The files are usually grouped into directories and
subdirectories. The file sys-tem starts with a root directory and divides it
into subdirectories. At each level, there can be subdirectories that continue
the file system into further levels and files that contain data. A directory
can contain both directories and files. If no directories are present, the file
system will stop at that level for that path.
A file name describes its location in the hierarchy by the path taken to
locate it, starting at the top and working down. This type of structure is
frequently referred to as a tree structure which, if turned upside down,
resembles a tree by starting at a single root directory — the trunk — and
branching out.
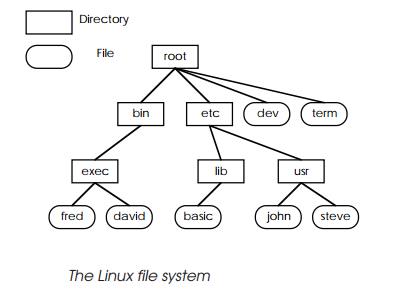
The full name, or path name, for the file steve located at the bottom of the tree would be /etc/usr/steve. The / character at the beginning is the symbol used for the starting
point and is known as root or the root directory. Subsequent use within the
path name indicates that the preceding file name is a directory and that the
path has followed down that route. The /
character is in the opposite direction to that used in MS-DOS systems: a tongue
in cheek way to remember which slash to use is that MS-DOS is backward compared
with Linux — and thus its slash character points backward.
The system revolves around its file structure and all physi-cal
resources are also accessed as files. Even commands exist as files. The
organisation is similar to that used within MS-DOS — but the original idea came
from UNIX, and not the other way around. One important difference is that with
MS-DOS, the top of the structure is always referred to by the name of the hard
disk or storage medium. Accessing an MS-DOS root directory C:\ imme-diately
tells you that drive C holds the data. Similarly, A:\ and B:\ normally refer to
floppy disks. With UNIX, such direct references to hardware do not exist. A
directory is simply present and rarely gives any clues as to its physical
location or nature. It may be a floppy disk, a hard disk or a disk on another
system that is connected via a network.
All Linux files are typically one of four types, although it can be
extremely difficult to know which type they are without referring to the system
documentation. A regular file can
contain any kind of data and is not restricted in size. A special file repre-sents a physical I/O device, such as a terminal.
Directories are files that hold lists
of files rather than actual data and named
pipes are similar to regular files but restricted in size.
The physical file system
The physical file system consists of mass storage devices, such as
floppy and hard disks, which are allocated to parts of the logical file system.
The logical file system (previously described) can be implemented on a system
with two hard disks by allocating the bin
directory and the filing subsystem below it to hard disk no. 2 — while the rest
of the file system is allocated to hard disk no. 1. To store data on hard disk
2, files are created somewhere in the bin
directory. This is the logical way of accessing mass storage. How-ever, all
physical input and output can be accessed by sending data to special files
which are normally located in the /dev
directory. This organisation of files is shown.
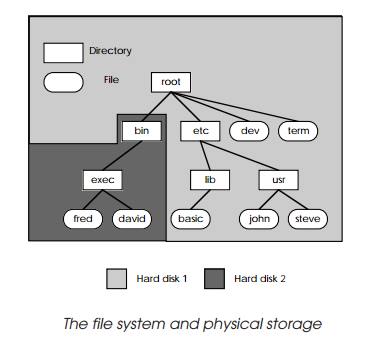
This can create a great deal of confusion: one method of sending data to
a hard disk is by allocating it to part of the logical file system and simply
creating data files. The second method involves sending the data directly to
the special /dev file that represents
the physical disk drive — which itself exists in the logical file system!
This conflict can be explained by an analogy using book-cases. A library
contains many bookcases where many books are stored. The library represents the
logical file system and the bookcases the physical mass storage. Books
represent the data files. Data can be stored within the file system by putting
books into the bookcases. Books can be grouped by subject on shelves within the
bookcases — these represent directories and subdirec-tories. When used
normally, the bookcases are effectively trans-parent and the books are located
or stored depending on their subject matter. However, there may be times when
more storage is needed or new subjects created and whole bookcases are moved or
cleared. In these cases, the books are referred to using the bookcase as the
reference — rather than subject matter.
The same can occur within Linux. Normally, access is via the file
system, but there are times when it is easier to access the data as complete
physical units rather than lots of files and directories. Hard disk copying and
the allocation of part of the logical file system to a floppy disk are two
examples of when access via the special /dev
file is used. Needless to say, accessing hard disks directly without using the
file system can be extremely dangerous: the data is simply accessed by block
numbers without any reference to the type of data that it contains. It is all
too easy to destroy the file system and the information it contains. Another
important difference between the access methods is that direct access can be
performed at any time and with the mass storage in any state. To access data
via the logical file system, data structures must be present to control the
file structure. If these are not present, logical access is impossible.
Building the file system
When a Linux system is powered up, its system software boots the Linux
kernel into existence. One of the first jobs per-formed is the allocation of
mass storage to the logical file system. This process is called mounting and
its reverse, the de-allocation of mass storage, is called unmounting. The mount command specifies the special file
which represents the physical storage and allocates it to a target directory.
When mount is complete, the file
system on the physical storage media has been added to the logical file system.
If the disk does not have a filing system, i.e. the data control structures
previously mentioned do not exist, the disk cannot be successfully mounted.
The mount and umount commands can be used to access
removable media, such as floppy disks, via the logical file system.
The disk is mounted, the data accessed as needed and the disk unmounted
before physically removing it. All that is needed for this access to take place
is the name of the special device file and the target directory. The target
directory normally used is /mnt but
the special device file name varies from system to system. The mount facility is not normally available
to end users for reasons that will
become apparent later in this chapter.
The file system
Files are stored by allocating sufficient blocks of storage to contain
all the data they contain. The minimum amount of storage that can be allocated
is determined by the block size, which can range from 512 bytes to 8 kbytes in
more recent systems. The larger block size reduces the amount of control data
that is needed — but can increase the storage wastage. A file with 1,025 bytes
would need two 1,024 byte blocks to contain it, leaving 1,023 bytes allocated
and therefore not accessible to store other files. End of file markers indicate
where the file actually ends within a block. Blocks are controlled and
allocated by a superblock, which con-tains an inode allocated to each file, directory,
subdirectory or special file. The inode describes the file and where it is
located.
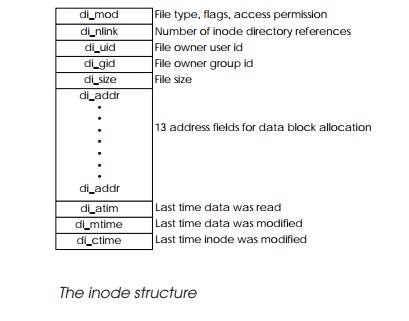
Using the library and book analogy, the superblock repre-sents the library catalogue which is used to
determine the size and location of each book. Each book has an entry — an inode — within the catalogue.
The example inode below, which
is taken from a Motorola System V/68 computer, contains information describing
the file type, status flags and access permissions (read, write and execute)
for the three classifications of users that may need the file: the owner who
created the file originally, any member of the owner’s group and, finally,
anyone else. The owner and groups are iden-tified by their identity numbers,
which are included in the inode. The
total file size is followed by 13 address fields, which point to the blocks
that have been used to store the file data. The first ten point directly to a
block, while the other three point indirectly to other blocks to effectively
increase the number of blocks that can be allocated and ultimately the file
size. This concept of direct and indirect pointers is analogous to a library
catalogue system: the inode represents
the reference card for each book or file. It would have sufficient space to describe exactly where the book was
located, but if the entry referred to a collection, the original card may not
be able to describe all the books and overflow cards would be needed. The inode uses indirect addresses to point
to other data structures and solve the overflow problem.
Why go to these lengths when all that is needed is the location of the
starting block and storage of the data in consecutive blocks? This method
reduces the amount of data needed to locate a complete file, irrespective of
the number of blocks the file uses. However, it does rely on the blocks being
available in contiguous groups, where
the blocks are consecutively ordered. This does not cause a problem when the
operating system is first used, and all the files are usually stored in
sequence, but as files are created and deleted, the free blocks become
fragmented and intermingled with existing files. Such a fragmented disk may
have 20 Mbytes of storage free, but would be unable to create files greater than
the largest contiguous number of blocks — which could be 10 or 20 times
smaller. There is little more frustrating than being told there is insufficient
storage available when the same system reports that there are many megabytes
free. Linux is more efficient in using the mass storage — at the expense of a
more complicated directory control structure. For most users, this complexity
is hidden from view and is not relevant to their use of the file system.
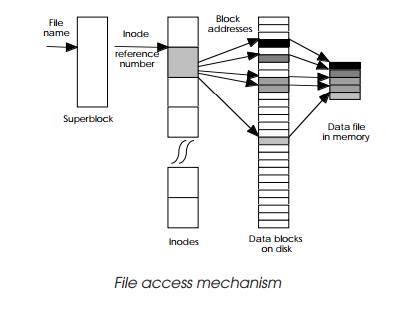
So what actually happens when a user wants a file or executes a command?
In both cases, the mechanism is very similar. The operating system takes the
file or command name and looks it up within the superblock to discover the inode
reference number. This is used to locate the inode itself and check the access permissions before allowing the
process to continue. If permission is granted, the inode block addresses are used to locate the data blocks stored on
hard disk. These blocks are put into memory to reconstitute the file or command
program. If the data file represents a command, control is then passed to it,
and the command executed.
The time taken to perform file access is inevitably depend-ant on the
speed of the hard disk and the time it takes to access each individual block.
If the blocks are consecutive or close to each other, the total access time is
much quicker than if they are dispersed throughout the disk. Linux also uses
mass storage as a replacement for system memory by using memory management
techniques and its system response is therefore highly dependant on hard disk
performance. UNIX uses two techniques to help improve performance: partitioning
and data caching.
Related Topics