Chapter: Embedded Systems Design : Real-time operating systems
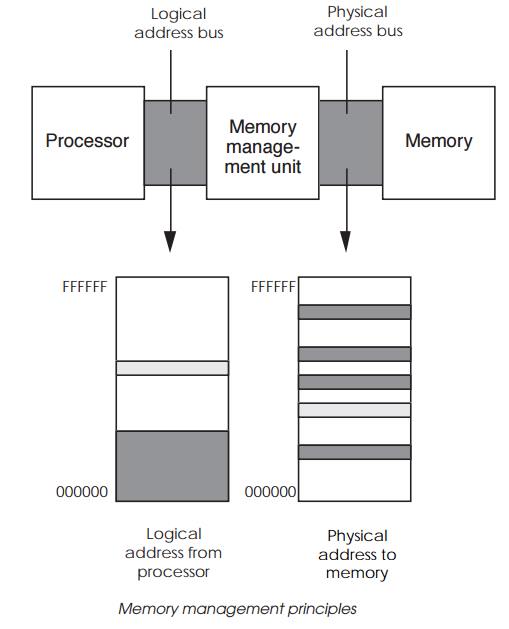
Memory management address translation
Memory management address
translation
While the use of memory management usually implies the use of an
operating system to remove the time-consuming job of defining and writing the
driver software, it does not mean that every operating system supports memory
management.
Many do not or are extremely limited in the type of memory management
facilities that they support. For operating systems that do support it, the
designer can access standard software that controls the translation of logical
addresses to different physical addresses as shown in the diagram.
In this example, the processor thinks that it is accessing memory at the
bottom of its memory map, while in reality it is being fetched from different
locations in the main memory map. The memory does not even need to be
contiguous: the processor’s single block or memory can be split into smaller
blocks, each with a different translation address.
This address translation is extremely powerful and allows the embedded
system designer many options to provide greater fault detection and/or security
within the system or even cost reduction through the use of virtual memory. The
key point is that memory management divides the processor memory map into
definable regions with different properties such as read and write only access
for one way data transfers and task or process specific memory access.
If no memory management hardware is present, most operating systems can
replace their basic address translation facility with a software-based scheme,
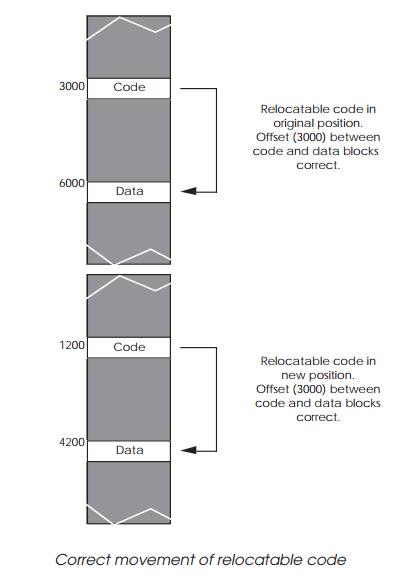
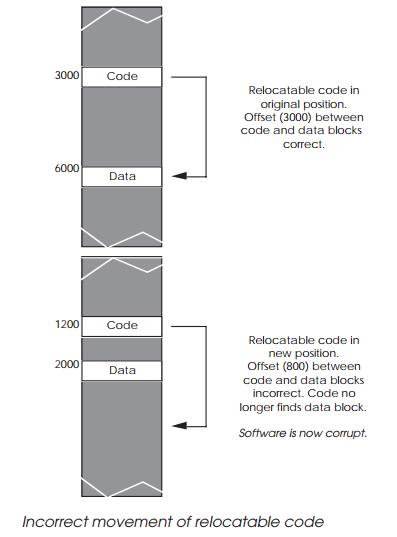
provided code is written to be position independent and relocatable. The more
sophisticated techniques start to impose a large software overhead which in
many cases is hard to justify within a simple system. Address translation is
often necessary to execute programs in different locations from that in which
they were generated. This allows the reuse of existing software modules and
facilitates the easy transfer of software from a prototype to a final system.
The relocation techniques are based on additional software built into
the program loader or even into the operating system itself. If the operating
system program loader cannot allocate the original memory, the program is
relocated into the next available block and the program allowed to execute.
Relocatable code does not have any immediate addressing values and makes
extensive use of program relative addressing. Data areas or software
sub-routines are not referenced explicitly but are located by relative
addressing modes using offsets:
•
Explicit addressing
e.g. branch to subroutine at address $0F04FF.
•
Relative addressing
e.g. branch to subroutine which is offset from here by $50 bytes.
Provided the offsets are maintained, then the relative ad-dressing will
locate data and code wherever the blocks are located in memory. Most modern
compilers will use these techniques but do not assume that all of them do.
There are alternative ways of manipulating addresses to provide address
translation, however.
Bank switching
When the first 8 bit processors became available with their 64 kbytes
memory space, there were many comments concerning whether there was a need for
this amount of memory. When the IBM PC appeared with its 640 kbyte memory map,
the same comments were made and here we are today using PCs that probably have
32 Mbytes of RAM. The problem faced by many of the early processor
architectures with a small 64 kbyte memory map is how the space can be expanded
without having to change the architecture and increase register sizes and so
on.
One technique that is used is that of bank switching. With this
technique, additional bits are used to select different banks of memory. Each
bank is the full 64 kbytes in size and is used in the normal way. By writing to
the individual selection bits, an indi-vidual bank can be selected and used. It
could be argued that this is no different from adding additional address bits.
Using two selection bits will support four 64 kbyte banks giving a total memory
space of 256 kbytes. This is the same amount of memory that can be addressed by
increasing the number of address bits from 16 to 18. The difference, however,
is that adding address bits implies that the programming model and processor
knows about the wider address space and can use it. With bank switching, this
is not the case, and the control and manipulation of the banks is under the
control of the program that the processor is running. In other words, the
processor itself has no knowledge that bank switching is taking place. It
simply sees the normal 64 kbyte address space.
This approach is frequently used with microcontrollers that have either
small external address spaces or alternatively limited external address buses.
The selection bits are created by dedicat-ing bits from the microcontroller’s
parallel I/O lines and using these to select and switch the external memory
banks. The bank switching is controlled by writing to these bits within the I/O
port.
This has some interesting repercussions for designs that use a RTOS. The
main problem is that the program must understand when the system context is
safe enough to allow a bank switch to be made. This means that system entities
such as data structures, buffers and anything else that is stored in memory
including program software must fit into the boundaries created by the bank
switching.
This can be fairly simple but it can also be extremely complex. If the
bank switching is used to extend a database, for example, the switching can be
easy to control by inserting a check for a memory bank boundary. Records 1–100
could be in bank A, with bank B holding records 101–200. By checking the record
number, the software can switch between the banks as needed. Such an
implementation could define a subroutine as the access point to the data and
within this routine the bank switching is managed so that it is transparent to
the rest of the software.
Using bank switching to support large stacks or data struc-tures on the
other hand is more difficult because the mechanisms that use the data involve
both automatic and software controlled access. Interrupts can cause stacks to
be incremented automati-cally and there is no easy way of checking for an
overflow and then incorporating the bank switching and so on needed to use it.
In summary, bank switching is used and there are 8 bit processors that
have dedicated bits to support it but the software issues to use it are
immense. As a result, it is frequently left for the system designer to figure
out a way to use it within a design. As a result, few, if any, RTOS
environments support this memory model.
Segmentation
Segmentation can be described as a form of bank switching that the processor
architecture does know about! It works by providing a large external address
bus but maintaining the smaller address registers and pointers within the
original 8 bit architec-ture. To bridge the gap, the memory is segmented
internally into smaller blocks that match the internal addressing and
additional registers known as segment registers are used to hold the
addi-tional address data needed to complete the larger external ad-dress.
Probably the most well-known implementation is the Intel 8086 architecture.
Virtual memory
With the large linear addressing offered by today’s 32 bit
microprocessors, it is relatively easy to create large software applications
which consume vast quantities of memory. While it may be feasible to install 64
Mbytes of RAM in a workstation, the costs are expensive compared with 64 Mbytes
of a hard disk. As the memory needs go up, this differential increases. A
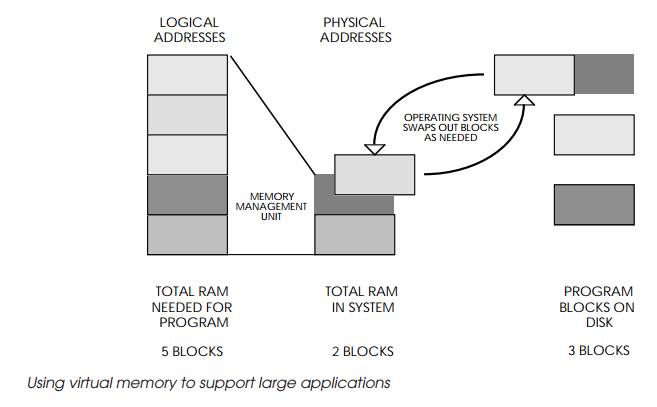
solution is to use the disk storage as the main storage medium, divide the
stored program into small blocks and keep only the blocks in processor system
memory that are needed. This technique is known as virtual memory and relies on
the presence within the system of a memory management unit.
As the program executes, the MMU can track how the program uses the
blocks, and swap them to and from the disk as needed. If a block is not present
in memory, this causes a page fault and forces some exception processing which
performs the swap-ping operation. In this way, the system appears to have large
amounts of system RAM when, in reality, it does not. This virtual memory
technique is frequently used in workstations and in the UNIX operating system.
Its appeal in embedded systems is lim-ited because of the potential delay in
accessing memory that can occur if a block is swapped out to disk.
Choosing an operating system
Comparing an operating system from 10 years ago with one offered today
shows how operating system technology has devel-oped over the past years.
Although the basic functions provided by the old and the newer operating
systems — they all provide multitasking, real-time responses and so on — are
still present, there have been some fundamental changes in the improvement in
the ease of use, performance and debugging facilities. Compar-ing a present-day
car with one from the 1920s is a good analogy. The basic mechanics and
principles have largely remained un-changed — that is, the engine, gearbox,
brakes, transmission — but there has been a great improvement in the ease of
driving, comfort and facilities. This is similar to what has happened with
operating systems. The basic mechanisms of context switches, task control
blocks, linked lists and so on are the basic fundamen-tals of any operating
system or kernel.
As a result, it can be quite difficult to select an operating system. To
make such a choice, it is necessary to understand the different ways that
operating systems have developed over the years and the advantages that this
has brought. The rest of this chapter discusses these changes and can help
formulate the crite-ria that can be used to make a decision.
Assembler versus high level language
In the early 1980s, operating systems were developed in response to
minicomputer operating systems where the emphasis was on providing the facilities
and performance offered by mini-computers. To achieve performance, they were
often written in assembler rather than in a high level language such as C or
PASCAL. The reason for this was simply one of performance: compiler technology
was not advanced enough to provide the compact and fast code needed to run an
operating system. For example, many compilers from the early 1980s did not use
all the M68000 address and data registers and limited themselves to only one or
two. The result was code that was extremely inefficient when compared with hand
coded assembler which did use all the processor’s registers.
The disadvantage is that assembler code is harder to write and maintain
compared to a high level language and is extremely difficult to migrate to other
architectures. In addition, the interface between the operating system and a
high level language was not well developed and in some cases non-existent!
Writing interface libraries was considered part of the software task.
As both processor performance and compiler technology improved, it
became feasible to provide an operating system written in a high level language
such as C which provided a seamless integration of the operating system
interface and appli-cation development language.
The choice of using assembler or a high level language with some
assembler compared to using an integrated operating sys-tem and high level
language is fairly obvious. What was accept-able a few years ago is no longer
the case and today’s successful operating systems are highly integrated with
their compiler tech-nology.
ROMable code
With early operating systems, restrictions in the code devel-opment
often prevented operating systems and compilers from generating code that could
be blown into read only memory for an embedded application. The reasons were
often historic rather than technical, although the argument that most
applications were too big to fit into the relatively small size of EPROM that
was available was certainly true for many years. Today, most users declare this
requirement as mandatory, and it is a standard offer-ing from compilers and
operating system vendors alike.
Scheduling algorithms
One area of constant debate is that of the scheduling algo-rithms that
are used to select which task is to execute next. There are several different
approaches which can be used. The first is to switch tasks only at the end of a
time slice. This allows a fairer distribution of the processing power across a
large number of tasks but at the expense of response time. Another is to take
the first approach but allow certain events to force switch a task even if the
current one has not used up all its allotted time slice. This allows external
interrupts to get a faster response. Another event that can be used to
interrupt the task is an operating system call.
Others have implemented priority systems where a task’s priority and
status within the ready list can be changed by itself, the operating system or
even by other tasks. Others have a fixed priority system where the level is
fixed when the task is created. Some operating systems even allow different
scheduling algo-rithms to be implemented so that a designer can change them to
give a specific response.
Changing algorithms and so on are usually indicative of trying to
squeeze the last bit of performance from the system and in such cases it may be
better to use a faster processor, or even in extreme cases actually accept that
the operating system cannot meet the required performance and use another.
Pre-emptive scheduling
One consistent requirement that has appeared is that of pre-emptive
scheduling. This refers to a particular scheduling algo-rithm where the highest
priority task will interrupt or pre-empt a currently executing task
irrespective of whether it has used its allotted time slice, and will continue
running until a higher level task is ready to. This gives the best response to
interrupts and events but can be a little dangerous. If a task is given the
highest priority and does not lower its priority or pre-empt itself, then other
tasks will not get an opportunity to execute. Therefore the ability to pre-empt
is often restricted to special tasks with time critical routines.
Modular approach
The idea of reusing code whenever possible is not a new one but it can
be difficult to implement. Obvious candidates with an operating system are
device drivers for I/O , and kernels for different processors. The key is in
defining a standard interface which allows such modules to be reused without
having to alter or change the code. This means that memory maps must not be
hardwired, or assumptions made by the driver or operating system. One of the
problems with early versions of many operat-ing systems was the fact that it
was not until fairly late in their development that a modular approach for
device drivers was available. As a result, the standard release included
several driv-ers for the same peripheral chip, depending on which VMEbus board
it was located.
Today, this approach is no longer acceptable and operating systems are
more modular in their approach and design. The advantages for users are far
more compact code, shorter develop-ment times and the ability to reuse code. A
special driver can be re-used without modification. This coupled with the need
to keep up with the number of boards that need standard ports has led to the
development of automated build systems that can take modular drivers and create
a new version extremely quickly.
Re-entrant code
This follows on from the previous topic but has one funda-mental difference
in that a re-entrant software module can be shared be many tasks and also
interrupted at any point and reused without any problems. For example, consider
module A which is shared by two tasks B and C. If task B uses module A and
exits from it, the module will be left in a known state, ready for another task
to use it. If task C starts to use it and in the middle of its execution is
switched out in favour of task B, then the problem may appear. If task B starts
to use module A, it may experience problems because A will be in an
indeterminate state. Even if it does not, other problems may still be lurking.
If module A uses global variables, then task B will cause them to be reset.
When task C returns to continue execution, its global data will have been
destroyed.
A re-entrant module can tolerate such interruptions with-out
experiencing these types of problems. The golden rule is for the module to only
access data associated with the task that is using the module code. Variables
are stored on stacks, in registers or in memory areas specific to the task and
not to the module. If shared modules are not re-entrant, care must be taken to
ensure that a context switch does not occur during its execution. This may mean
disabling or locking out the scheduler or dispatcher.
Cross-development platforms
Today, most software development is done on cross-development platforms
such as Sun workstations, UNIX systems and IBM PCs. This is in direct contrast
to early systems which required a dedicated software development system. The
degree of platform support and the availability of good development tools which
go beyond the standard of symbolic level debug have become a major product
selling point.
Integrated networking
This is another area which is becoming extremely impor-tant. The ability
to use a network such as TCP/IP on Ethernet to control target boards, download
code and obtain debugging information is fast becoming a mandatory requirement.
It is rapidly replacing the more traditional method of using serial RS232 links
to achieve the same end.
Multiprocessor support
This is another area which has changed dramatically. Ten years ago it
was possible to use multiple processors provided the developer designed and
coded all the inter-processor communi-cation. Now, many of today’s operating
systems can provide optional modules that will do this automatically. However,
mul-tiprocessing techniques are often misunderstood and as this is such a big
topic for both hardware and software developers it is treated in more depth
later in this text.
Related Topics