Chapter: An Introduction to Parallel Programming : Parallel Program Development
Performance of the OpenMP implementations
Performance of the OpenMP implementations
Table 6.9 shows run-times of the two OpenMP
implementations on the same two fifteen-city problems that we used to test the
Pthreads implementations. The programs
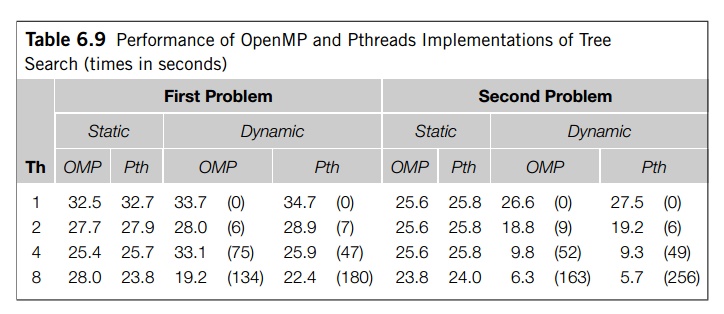
were also run on the same system we used for
the Pthreads and serial tests. For ease of comparison, we also show the
Pthreads run-times. Run-times are in seconds and the numbers in parentheses
show the total number of times stacks were split in the dynamic
implementations.
For the most part, the OpenMP implementations
are comparable to the Pthreads implementations. This isn’t surprising since the
system on which the programs were run has eight cores, and we wouldn’t expect
busy-waiting to degrade overall performance unless we were using more threads
than cores.
There are two notable exceptions for the first
problem. The performance of the static OpenMP implementation with eight threads
is much worse than the Pthreads implementation, and the dynamic implementation
with four threads is much worse than the Pthreads implementation. This could be
a result of the nondeterminism of the programs, but more detailed profiling
will be necessary to determine the cause with any certainty.
Related Topics