Chapter: Biotechnology Applying the Genetic Revolution: Protein Engineering
Protein Engineering
Protein Engineering
INTRODUCTION
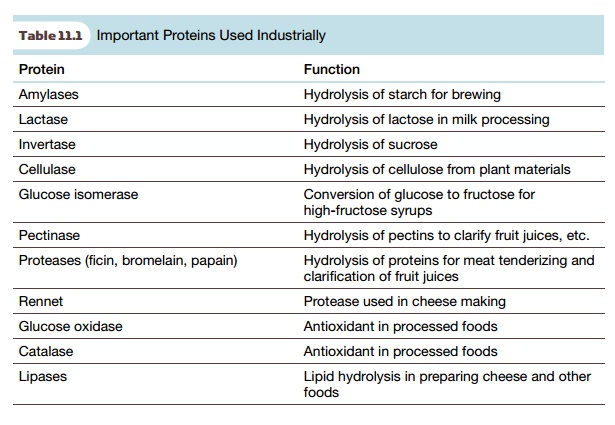
A variety of enzymes have
been in industrial use since before genetic engineering appeared. However,
merely a couple of dozen enzymes account for over 90% of total industrial
enzyme use. Some common examples are listed in Table 11.1. These proteins are
used under relatively harsh conditions and are exposed to oxidizing conditions
not found inside living cells. Consequently, these particular proteins are
unusually robust and stable and are not at all representative of typical
enzymes in this respect. It is notable that most of them are hydrolases that degrade either
carbohydrate polymers or proteins.
Increasing the range of
industrial enzymes has three facets. First, modern biology has identified many
novel enzyme-catalyzed reactions that may be of industrial use. Second, as
discussed in the previous chapter, it is now possible to produce desired
proteins in large amounts because of gene cloning and expression systems.
Third, the sequence of the protein itself may be altered by genetic engineering
to improve its properties. This is known as protein engineering and is the subject of the present chapter.
Methods for manipulating DNA
sequences and for expressing the encoded proteins have been discussed in
previous chapters. Therefore we shall omit these details here. Rather we will
emphasize the possibilities for altering the biological properties of proteins.
In practice, most protein engineering has so far been concerned with making
more stable variants of useful enzymes. The objective here is to engineer
proteins so that they may be used under industrial conditions without being
denatured and losing activity. However, it is also possible to alter proteins
to change the specificity of their enzyme activities or even to create totally
new enzyme activities. Ultimately, it may be possible to design proteins from
basic principles. This will require the ability to predict three-dimensional
protein structure from the polypeptide sequence.
Related Topics