Chapter: Data Warehousing and Data Mining : Association Rule Mining and Classification
Mining Methods
Mining
Methods
The method that mines the
complete set of frequent itemsets with candidate generation. Apriori property
& The Apriori Algorithm.
Apriori property
All nonempty subsets of a frequent item set most
also be frequent.
o
An item set I does not satisfy the minimum support
threshold, min-sup, then I is not frequent, i.e., support(I) < min-sup
o
If an item A is added to the item set I then the
resulting item set (I U A) can not occur more frequently than I.
Monotonic functions are functions that move in only one direction.
This property is called anti-monotonic.
If a set can not pass a test, all its supersets will fail the same test
as well.
This property is monotonic in failing the test.
The Apriori Algorithm
Join Step: Ck is generated by joining Lk-1with
itself
Prune Step:
Any (k-1)-itemset that is not frequent cannot be a subset of a frequent
k-itemset


The method that mines the
complete set of frequent itemsets without generation.
Compress a large database into a compact, Frequent-Pattern tree (FP-tree) structure
highly
condensed, but complete for frequent pattern mining
avoid
costly database scans
Develop an efficient, FP-tree-based frequent pattern mining method
A
divide-and-conquer methodology: decompose mining tasks into smaller ones
Avoid
candidate generation: sub-database test only!
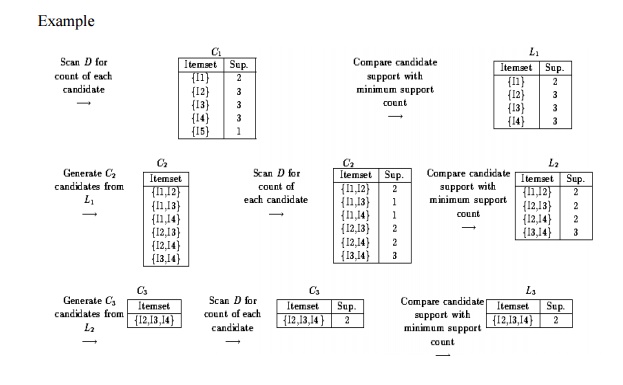
Example 5.5 FP-growth
(finding frequent itemsets without candidate generation). We re-examine the mining of transaction database, D, of Table 5.1 in Example 5.3 using the
frequent pattern growth approach.

Benefits of the FP-tree Structure
Completeness:
o
never breaks a long pattern of any transaction
o
preserves complete information for frequent pattern
mining
Compactness
o
reduce irrelevant information—infrequent items are
gone
o
frequency descending ordering: more frequent items
are more likely to be shared
o
never be larger than the original database (if not
count node-links and counts)
o
Example: For Connect-4 DB, compression ratio could
be over 100
Mining Frequent Patterns Using
FP-tree
General idea (divide-and-conquer)
o
Recursively grow frequent pattern path using the
FP-tree
Method
o
For each item, construct its conditional
pattern-base, and then its conditional FP-tree
o
Repeat the process on each newly created
conditional FP-tree
o
Until the resulting FP-tree is empty, or it
contains only one path (single path will generate all the combinations of its
sub-paths, each of which is a frequent pattern)
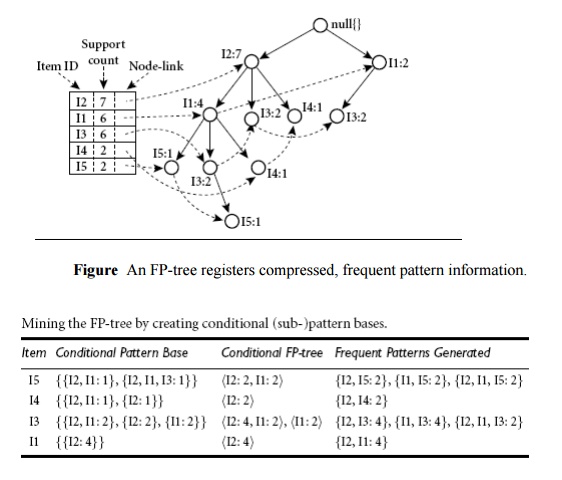
Major Steps to Mine FP-tree
1. Construct
conditional pattern base for each node in the FP-tree
2. Construct
conditional FP-tree from each conditional pattern-base
3. Recursively
mine conditional FP-trees and grow frequent patterns obtained so far
o
If the conditional FP-tree contains a single path,
simply enumerate all the patterns
Principles of Frequent Pattern
Growth
Pattern growth property
Let a be a frequent itemset in DB, B be a's
conditional pattern base, and b be an
itemset in B. Then a È b is a
frequent itemset in DB iff b is
frequent in B.
―abcdef ‖ is a frequent
pattern, if and only if
―abcde ‖ is a frequent pattern, and
―f ‖ is frequent in the set of
transactions containing ―abcde ‖
Why Is Frequent Pattern Growth
Fast?
Our performance study shows
FP-growth
is an order of magnitude faster than Apriori, and is also faster than
tree-projection
Reasoning
No
candidate generation, no candidate test
Use
compact data structure
Eliminate
repeated database scan
Basic
operation is counting and FP-tree building
Related Topics