Chapter: Data Warehousing and Data Mining : Association Rule Mining and Classification
Lazy Learners (or Learning from Your Neighbors)
Lazy
Learners (or Learning from Your Neighbors)
The
classification methods discussed so far in this chapter—decision tree
induction, Bayesian classification, rule-based classification, classification
by backpropagation, support vector machines, and classification based on
association rule mining—are all examples of eager
learners. Eager learners, when given a set of training tuples, will
construct a generalization (i.e., classification) model before receiving new
(e.g., test) tuples to classify. We can think of the learned model as being
ready and eager to classify previously unseen tuples.
k-Nearest-Neighbor
Classifiers
The k-nearest-neighbor method was first
described in the early 1950s. The method is labor intensive when given large
training sets, and did not gain popularity until the 1960s when increased
computing power became available. It has since been widely used in the area of
pattern recognition.
Nearest-neighbor
classifiers are based on learning by analogy, that is, by comparing a given
test tuple with training tuples that are similar to it. The training tuples are
described by n attributes. Each tuple
represents a point in an n-dimensional
space. In this way, all of the training tuples are stored in an n-dimensional pattern space. When given
an unknown tuple, a k-nearest-neighbor classifier searches the pattern space for
the k training tuples that are
closest to the unknown tuple. These k
training tuples are the k ―nearest
neighbors‖ of the unknown tuple.
―Closeness‖
is defined in terms
of a distance metric, such as Euclidean distance. The
Euclidean distance between two points or tuples, say, X1 = (x11, x12, : : : , x1n) and X2 = (x21, x22, : : , x2n), is
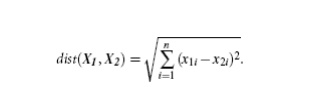
Case-Based
Reasoning
Case-based
reasoning (CBR) classifiers use a database of problem solutions to solve new problems.
Unlike nearest-neighbor classifiers, which store training tuples as points in
Euclidean space, CBR stores the tuples or ―cases‖ for problem solving as
complex symbolic descriptions. Business applications of CBR include problem
resolution for customer service help desks, where cases describe
product-related diagnostic problems. CBR has also been applied to areas such as
engineering and law, where cases are either technical designs or legal rulings,
respectively. Medical education is another area for CBR, where patient case
histories and treatments are used to help diagnose and treat new patients.
When
given a new case to classify, a case-based reasoner will first check if an
identical training case exists. If one is found, then the accompanying solution
to that case is returned. If no identical case is found, then the case-based
reasoner will search for training cases having SCE Department of Information
Technology components that are similar to those of the new case. Conceptually,
these training cases may be considered as neighbors of the new case. If cases
are represented as graphs, this involves searching for subgraphs that are
similar to subgraphs within the new case. The case-based reasoner tries to
combine the solutions of the neighboring training cases in order to propose a
solution for the new case. If incompatibilities arise with the individual
solutions, then backtracking to search for other solutions may be necessary.
The case-based reasoner may employ background knowledge and problem-solving
strategies in order to propose a feasible combined solution.
Related Topics