Chapter: Data Warehousing and Data Mining : Association Rule Mining and Classification
Classification and Prediction
Classification
and Prediction
Classification:
o
predicts categorical class labels
o
classifies data (constructs a model) based on the
training set and the values (class labels) in a classifying attribute and uses
it in classifying new data
Prediction
models
continuous-valued functions, i.e., predicts unknown or missing values
Typical
applications
o
Credit approval
o
Target marketing
o
Medical diagnosis
o
Fraud detection
Classification: Basic Concepts
Supervised learning (classification)
o
Supervision: The training data (observations,
measurements, etc.) are accompanied by labels
indicating the class of the observations a New data is classified based on the
training set
Unsupervised learning (clustering)
o
The class labels of training data is unknown
o
Given a set of measurements, observations, etc.
with the aim of establishing the existence of classes or clusters in the data
Classification vs. Numeric
Prediction
Classification
o
predicts categorical class labels (discrete or
nominal)
o
classifies data (constructs a model) based on the
training set and the values (class labels) in a classifying attribute and uses
it in classifying new data
Numeric Prediction
o
models continuous-valued functions, i.e., predicts
unknown or missing values
Typical applications
o
Credit/loan approval:
o
Medical diagnosis: if a tumor is cancerous or
benign
o
o Fraud detection: if a transaction is fraudulent
o
Web page categorization: which category it is
Classification—A Two-Step Process
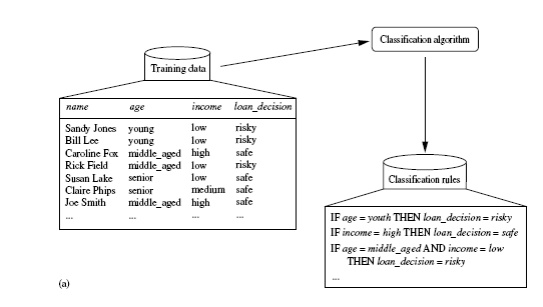
Model construction: describing a set of predetermined classes
o
Each tuple/sample is assumed to belong to a
predefined class, as determined by the class label attribute
o
The set of tuples used for model construction:
training set
o
The model is represented as classification rules,
decision trees, or mathematical formulae
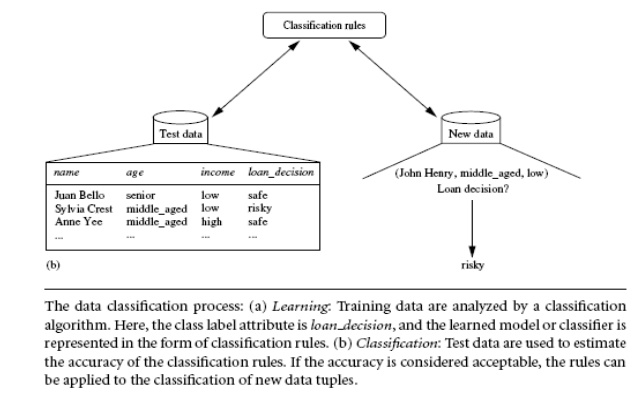
Model usage: for classifying future or unknown objects
Estimate
accuracy of the model
o
The known label of test sample is compared with the
classified result from the model
o
Accuracy rate is the percentage of test set samples
that are correctly classified by the model
o
Test set is independent of training set, otherwise
over-fitting will occur
Process (1): Model Construction
Process (2): Using the Model in
Prediction
Issues Regarding Classification
and Prediction
Data
cleaning: This refers to the preprocessing of data in order to remove or reduce noise (by applying smoothing techniques, for
example) and the treatment of missing
values (e.g., by replacing a missing value with the most commonly occurring
value for that attribute, or with the most probable value based on statistics).
Relevance
analysis: Many of the attributes in the data may be redundant. Correlation analysis can be used to identify
whether any two given attributes are statistically related.
Data
transformation and reduction: The data may be transformed by
normalization, particularly when
neural networks or methods involving distance measurements are used in the
learning step. Normalization involves scaling all values for a given attribute
so that they fall within a small specified range, such as -1.0 to 1.0, or 0.0
to 1.0. In methods that use distance
Comparing Classification and
Prediction Methods
Classification
and prediction methods can be compared and evaluated according to the following
criteria:
o
Accuracy
o
Speed
o
Robustness
o
Scalability
o
Interpretability
Related Topics