Chapter: Compilers : Principles, Techniques, & Tools : Syntax Analysis
Syntax Analysis
Chapter 4
Syntax Analysis
This chapter is devoted to parsing methods that are typically used in
compilers. We first present the basic concepts, then techniques suitable for
hand implementation, and finally algorithms that have been used in automated
tools. Since programs may contain syntactic errors, we discuss extensions of
the parsing methods for recovery from common errors.
By design, every programming language has precise rules that prescribe
the syntactic structure of well-formed programs. In C, for example, a program
is made up of functions, a function out of declarations and statements, a
statement out of expressions, and so on. The syntax of programming language
constructs can be specified by context-free grammars or BNF (Backus-Naur Form)
nota-tion, introduced in Section 2.2. Grammars offer significant benefits for
both language designers and compiler writers.
A grammar gives a precise, yet
easy-to-understand, syntactic specification of a programming language.
From certain classes of grammars,
we can construct automatically an effi-cient parser that determines the
syntactic structure of a source program. As a side benefit, the
parser-construction process can reveal syntactic ambiguities and trouble spots
that might have slipped through the initial design phase of a language.
• The structure imparted to a language by a properly designed grammar is
useful for translating source programs into correct object code and for
detecting errors.
A grammar allows a language to be evolved or developed iteratively, by
adding new constructs to perform new tasks. These new constructs can be
integrated more easily into an implementation that follows the gram-matical
structure of the language.
Introduction
1 The Role of the Parser
2 Representative Grammars
3 Syntax Error Handling
4 Error-Recovery Strategies
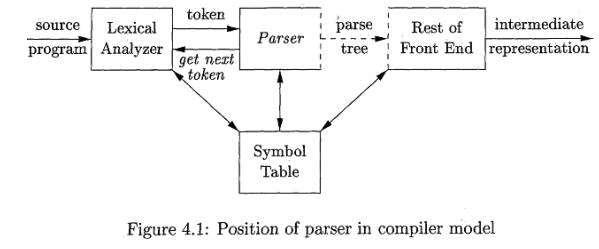
In this section, we examine the way the parser fits into a typical
compiler. We then look at typical grammars for arithmetic expressions. Grammars
for ex-pressions suffice for illustrating the essence of parsing, since parsing
techniques for expressions carry over to most programming constructs. This
section ends with a discussion of error handling, since the parser must respond
gracefully to finding that its input cannot be generated by its grammar.
1. The Role of the Parser
In our
compiler model, the parser obtains a string of tokens from the lexical analyzer,
as shown in Fig. 4.1, and verifies that the string of token names can be
generated by the grammar for the source language. We expect the parser to
report any syntax errors in an intelligible fashion and to recover from
commonly occurring errors to continue processing the remainder of the program.
Conceptually, for well-formed programs, the parser constructs a parse tree and
passes it to the rest of the compiler for further processing. In fact, the
parse tree need not be constructed explicitly, since checking and translation
actions can be interspersed with parsing, as we shall see. Thus, the parser and
the rest of the front end could well be implemented by a single module.
There are three general types of parsers for grammars: universal,
top-down, and bottom-up. Universal parsing methods such as the
Cocke-Younger-Kasami algorithm and Earley's algorithm can parse any grammar
(see the bibliographic notes). These general methods are, however, too
inefficient to use in production compilers.
The
methods commonly used in compilers can be classified as being either top-down
or bottom-up. As implied by their names, top-down methods build parse trees
from the top (root) to the bottom (leaves), while bottom-up methods start from
the leaves and work their way up to the root. In either case, the input to the
parser is scanned from left to right, one symbol at a time.
The most efficient top-down and bottom-up methods work only for
sub-classes of grammars, but several of these classes, particularly, LL and LR
gram-mars, are expressive enough to describe most of the syntactic constructs
in modern programming languages. Parsers implemented by hand often use LL
grammars; for example, the predictive-parsing approach of Section 2.4.2 works
for LL grammars. Parsers for the larger class of LR grammars are usually
constructed using automated tools.
In this chapter, we assume that the output of the parser is some
represent-ation of the parse tree for the stream of tokens that comes from the
lexical analyzer. In practice, there are a number of tasks that might be
conducted during parsing, such as collecting information about various tokens
into the symbol table, performing type checking and other kinds of semantic
analysis, and generating intermediate code. We have lumped all of these
activities into the "rest of the front end" box in Fig. 4.1. These
activities will be covered in detail in subsequent chapters.
2. Representative Grammars
Some of the grammars that will be examined in this chapter are presented
here for ease of reference. Constructs that begin with keywords like while or
int, are relatively easy to parse, because the keyword guides the choice of the
grammar production that must be applied to match the input. We therefore
concentrate on expressions, which present more of challenge, because of the
associativity and precedence of operators.
Associativity
and precedence are captured in the following grammar, which is similar to ones
used in Chapter 2 for describing expressions, terms, and factors. E represents expressions consisting of
terms separated by + signs, T
represents terms consisting of factors separated by * signs, and F represents factors that can be either
parenthesized expressions or identifiers:
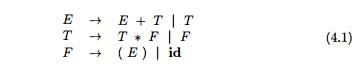
Expression grammar (4.1) belongs to the class of LR grammars that are
suitable for bottom-up parsing. This grammar can be adapted to handle
additional operators and additional levels of precedence. However, it cannot be
used for top-down parsing because it is left recursive.
The following
non-left-recursive variant of the expression grammar (4.1) will be used for
top-down parsing:
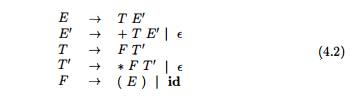
T he
following grammar treats + and * alike, so it is useful for illustrating
techniques for handling ambiguities during parsing:
E -
> E
+ E | E * E 1 ( E )
| id (4.3)
Here, E represents expressions
of all types. Grammar (4.3) permits more than one parse tree for expressions
like a + b*c.
3. Syntax Error Handling
The remainder of this section considers the nature of syntactic errors
and gen-eral strategies for error recovery. Two of these strategies, called
panic-mode and phrase-level recovery, are discussed in more detail in
connection with specific parsing methods.
If a compiler had to process only correct programs, its design and
implemen-tation would be simplified greatly. However, a compiler is expected to
assist the programmer in locating and tracking down errors that inevitably
creep into programs, despite the programmer's best efforts. Strikingly, few
languages have been designed with error handling in mind, even though errors
are so common-place. Our civilization would be radically different if spoken
languages had the same requirements for syntactic accuracy as computer
languages. Most programming language specifications do not describe how a
compiler should respond to errors; error handling is left to the compiler
designer. Planning the error handling right from the start can both simplify
the structure of a compiler and improve its handling of errors.
Common
programming errors can occur at many different levels.
Lexical errors include misspellings of
identifiers, keywords, or operators — e.g.,
the use of an identifier e l i p s e S i z e instead of e l l i p s e S i z e —
and missing quotes around text intended as a string.
Syntactic errors include misplaced
semicolons or extra or missing braces; that
is, "{" or " } . " As another example, in C or Java, the
appearance
of a case statement without an enclosing s w i t c h is a syntactic
error (however, this situation is usually allowed by the parser and caught
later in the processing, as the compiler attempts to generate code).
• Semantic errors include type mismatches between operators and operands. An example is a r e t u r n statement
in a Java method with result type void .
• Logical errors can be anything from incorrect reasoning on the part of the programmer to the use in a C
program of the assignment operator = instead of the comparison operator ==. The
program containing = may be well formed; however, it may not reflect the
programmer's intent.
The precision of parsing methods allows syntactic errors to be detected
very efficiently. Several parsing methods, such as the LL and LR methods,
detect an error as soon as possible; that is, when the stream of tokens from
the lexical analyzer cannot be parsed further according to the grammar for the
language.
More precisely, they have the viable-prefix property, meaning that they
detect that an error has occurred as soon as they see a prefix of the input
that cannot be completed to form a string in the language.
Another reason for emphasizing error recovery during parsing is that
many errors appear syntactic, whatever their cause, and are exposed when
parsing cannot continue. A few semantic errors, such as type mismatches, can
also be detected efficiently; however, accurate detection of semantic and
logical errors at compile time is in general a difficult task.
The error handler in a parser has goals that are simple to state but
chal-lenging to realize:
• Report the presence of errors clearly and
accurately.
• Recover from each error quickly enough to
detect subsequent errors.
• Add minimal overhead to the processing of
correct programs.
Fortunately, common errors are simple ones, and a relatively
straightforward error-handling mechanism often suffices.
How should an error handler report the presence of an error? At the very
least, it must report the place in the source program where an error is
detected, because there is a good chance that the actual error occurred within
the previous few tokens. A common strategy is to print the offending line with
a pointer to the position at which an error is detected.
4. Error-Recovery Strategies
Once an error is detected, how should the parser recover? Although no
strategy has proven itself universally acceptable, a few methods have broad
applicabil-ity. The simplest approach is for the parser to quit with an
informative error message when it detects the first error. Additional errors
are often uncovered if the parser can restore itself to a state where
processing of the input can con-tinue with reasonable hopes that the further
processing will provide meaningful diagnostic information. If errors pile up,
it is better for the compiler to give up after exceeding some error limit than
to produce an annoying avalanche of "spurious" errors.
The balance of this section is devoted to the following recovery
strategies: panic-mode, phrase-level, error-productions, and global-correction.
Panic – Mode Recovery
With this method, on discovering an error, the parser discards input
symbols one at a time until one of a designated set of synchronizing tokens is found. The synchronizing tokens are usually
delimiters, such as semicolon or }, whose role in the source program is clear
and unambiguous. The compiler designer must select the synchronizing tokens
appropriate for the source language. While panic-mode correction often skips a
considerable amount of input without check-ing it for additional errors, it has
the advantage of simplicity, and, unlike some methods to be considered later,
is guaranteed not to go into an infinite loop.
Phrase - Level
Recovery
On discovering an error, a parser may perform local correction on the
remaining input; that is, it may replace a prefix of the remaining input by
some string that allows the parser to continue. A typical local correction is
to replace a comma by a semicolon, delete an extraneous semicolon, or insert a
missing semicolon. The choice of the local correction is left to the compiler
designer. Of course, we must be careful to choose replacements that do not lead
to infinite loops, as would be the case, for example, if we always inserted
something on the input ahead of the current input symbol.
Phrase-level replacement has been used in several error-repairing
compilers, as it can correct any input string. Its major drawback is the
difficulty it has in coping with situations in which the actual error has
occurred before the point of detection.
Error
Productions
By anticipating common errors that might be encountered, we can augment
the grammar for the language at hand with productions that generate the
erroneous constructs. A parser constructed from a grammar augmented by these
error productions detects the anticipated errors when an error production is
used during parsing. The parser can then generate appropriate error diagnostics
about the erroneous construct that has been recognized in the input.
Global
Correction
Ideally, we would like a compiler to make as few changes as possible in
processing an incorrect input string. There are algorithms for choosing a
minimal sequence of changes to obtain a globally least-cost correction. Given
an incorrect input string x and
grammar G, these algorithms will find
a parse tree for a related string y,
such that the number of insertions, deletions, and changes of tokens required
to transform x into y is as small as possible.
Unfortunately, these methods are in general too costly to implement in terms of
time and space, so these techniques are currently only of theoretical interest.
Do note that a closest correct program may not be what the programmer
had in mind. Nevertheless, the notion of least-cost correction provides a
yardstick for evaluating error-recovery techniques, and has been used for
finding optimal replacement strings for phrase-level recovery.
Related Topics