Chapter: Psychology: Perception
Perception: Other Modalities
OTHER MODALITIES
We’ve almost finished our
discussion of perception, but before we bring the discussion to a close,
there’s just one more topic to explore. We’ve exam-ined visual perception and
how we recognize the things we see. What about the other modalities? How do we
hear—and understand—the speech that reaches our ears or the music we listen to?
How do we perceive smells and tastes? How do we experience the warmth of the
sun or the cold of an icy wind?
Of course, the various senses
differ in many ways. Still, let’s not lose track of how much the different
sense modalities have in common. For example, as we noted, all of the
modalities are powerfully influenced by contrast effects, so sugar tastes
sweeter after a sip of lemon juice, just as red seems more intense after
looking at green. Likewise, each sense is influenced by the others—and so what we taste is
influenced by the smells that are present, how a voice sounds depends on
whether it’s coming from a face that looks friendly, and so on.
Many of the phenomena discussed
also have direct parallels in other senses. For example, we’ve examined the
perceiver’s role in organizing the visual input, and similar points can be made
for hearing: Just as vision must parse the input, decid-ing where one object
ends and the next begins, our sense of hearing must parse the stream of sounds, deciding where one note ends and
the next begins or where one word ends and the next begins. And, just as in
vision, the input for hearing is sometimes ambiguous—fully compatible with more
than one parsing. This was evident, for exam-ple, in the mondegreens we
discussed earily—including the celebrated misperception of Jimi Hendrix’s song
“Purple Haze.” The song contained the lyric, “’Scuse me while I kiss the sky,”
but many people mis-heard the lyric as “. . . while I kiss this guy.” The two
key phrases (“the sky” and “this guy”) are virtually identical acoustically,
and the difference between them is therefore “in the ear of the beholder”; no
wonder, then, that the phrase was often misperceived.
Hearing, like vision, also
requires us to group together
separate elements in order to hear coherent sequences. This requirement is
crucial, for example, for the perception of music. We must group together the
notes in the melody line, perceiving them separately from the notes in the
harmony, in order to detect the relationships from one note to the next within
the melody; otherwise, the melody would be lost to us.
Likewise, our recognition of
sounds seems to begin with the input’s acoustic features, just as the
recognition of objects begins with the input’s visual features. Our analysis of
sound features is supplemented by top-down (knowledge-driven) processing, just
as it is for vision, and the relevant knowledge for hearing includes the
hearer’s knowledge about the context as well as her broader knowledge about the
world.
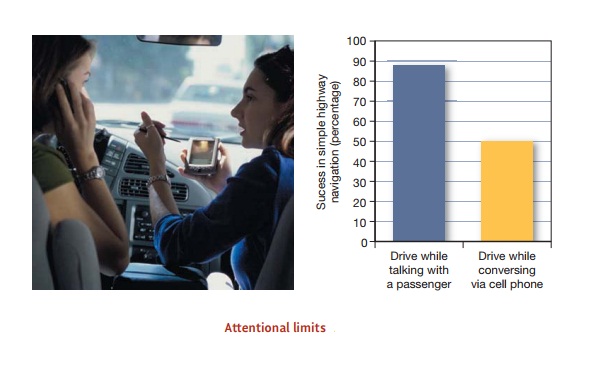
And hearing, like vision, is
powerfully influenced by attention (Figure 5.39). Indeed, some of the classic
work on attention is done with auditory inputs and yields data con-sistent with
the findings we reviewed for vision: When our attention is focused on one
auditory input, we hear remarkably little from other inputs. Thus, if we’re
listening to one conversation at a cocktail party, we’ll be able to hear that
the unattended voice behind us is loud rather than soft, a male’s rather than a
female’s; but we’ll have no idea what the unattended voice is actually saying
or even whether the unattended speech
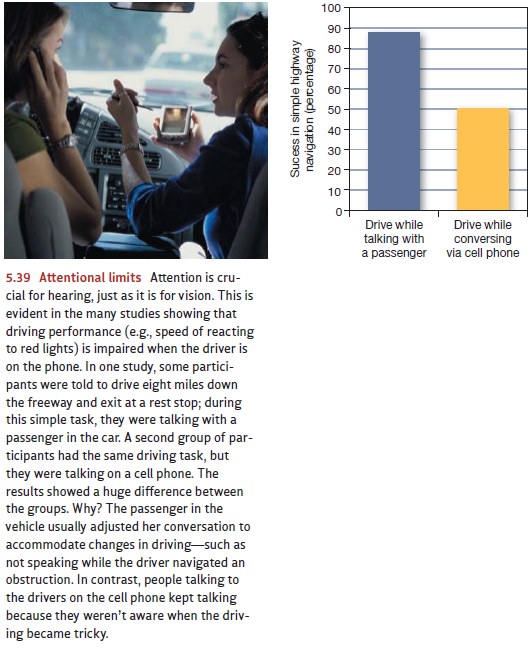
makes any sense at all. This
point has been documented by studies that require partic-ipants to pay
attention to a voice arriving (through headphones) in one ear, while another
(unattended) voice is presented to the other ear. In this setup, participants
grasp virtually none of the content of the unattended message. In one classic
study, the participants couldn’t even tell whether the speaker on the
unattended ear was reading the passage backward or forward (Cherry, 1953;
Reisberg, 2010).
But let’s be clear that
participants aren’t totally deaf to an unattended message. If, for example,
this message contains the participants’ own names, a substantial number of
par-ticipants will detect this significant stimulus (Moray, 1959). Participants
may also detect other personally relevant stimuli, such as the name of a
favorite restaurant or the title of a book they’ve just read (Conway, Cowan,
& Bunting, 2001; Wood & Cowan, 1995). The reason for this is priming.
The participant has presumably encountered these significant stimuli recently,
so the relevant detectors are probably still “warmed up” and will respond even
to a weak input. Just as in vision, therefore, the perception of a stimulus can
be pro-moted either by expectations or by recent exposure; and either form of
priming can offset the significant disadvantages associated with the absence of
attention.
In short, then, many of the
lessons we’ve learned about vision can be applied directly to the sense of
hearing. This is true for many of our specific claims about vision; it’s also
true for our methodological claims—particularly the need for multiple levels of
descrip-tion. In hearing no less than in vision, it’s immensely useful to
approach the problems of perception in more than one way, with a close
examination of function (what the processes achieve) and the biology (how the
processes are implemented in the nervous system) if we are to understand how
people come to know the world around them.
Related Topics