Chapter: Psychology: Perception
Network Models of Perception
NETWORK MODELS
OF PERCEPTION
The last few sections have
created a new question for us. We’ve been focusing on the inter-pretive nature
of perception. In all cases, people don’t just “pick up” and record the stimuli
that reach the eye, the way a camera or videorecorder might. Instead, they
organize and shape the input. When they encounter ambiguity—and they often
do—they make choices about how the ambiguity should be resolved.
But how exactly does this
interpretation take place? This question needs to be pur-sued at two levels.
First, we can try to describe the sequence of events in functional terms—first,
this is analyzed; then that is analyzed—laying out in detail
the steps needed to accomplish the task. Second, we can specify the neural
processes that actu-ally support the analysis and carry out the processing.
Let’s look at both types of expla-nation, starting with the functional
approach.
Feature Nets
Earlier, we noted some complications for any theorizing that involves features. Even with these complications, though, it’s clear that feature detection playsa central role in object recognition. We saw that the visual system does analyze the input in terms of features: Specialized cells—feature detectors—respond to lines at various angles, curves at various positions, and the like. More evidence for the importance of features comes from behavioral studies that use a visual search procedure. In this task, a research participant is shown an array of visual forms and asked to indicate as quickly as she can whether a particular target is present— whether a vertical line is visible among the forms shown, perhaps, or a red circle is visible amid a field of squares. This task is easy if the target can be distinguished from the field by just one salient feature—for example, searching for a vertical among a field of horizontals, or for a green target amidst a group of red distracters. In such cases, the target “pops out” from the distracter elements, and search time is virtually independent of the number of items in the display—so people can search through four targets, say, as fast as they can search through two, or eight as fast as they can search through four. These results make it clear that features have priority in our visual perception. We can detect them swiftly, easily, and presumably at an early stage in the sequence of events required to recognize an object.
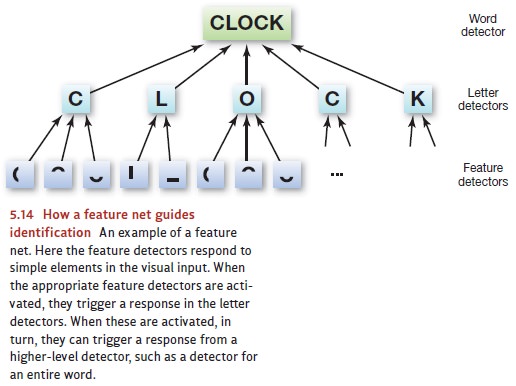
But how do we use this feature
information? And how, knowing about the complications we’ve discussed, can we
use this information to build a full model of object recognition? One option is
to set up a hierarchy of detectors
with detectors in each layer serving as the triggers for detectors in the next
layer (Figure 5.14). In the figure, we’ve illustrated this idea with a
hierarchy for recognizing words; the
idea would be the same with one for recogniz-ing objects. At the lowest level of the hierarchy would be the feature
detectors we’ve already described—those responsive to horizontals, verticals,
and so forth. At the next level of the hierarchy would be detectors that
respond to combinations of these simple features. Detectors at this second
level would not have to survey the visual world directly. Instead, they’d be
triggered by activity at the initial level. Thus, there might be an “L”
detector in the second layer of detectors that fires only when triggered by
both the vertical- and horizon-tal-line detectors at the first level.
Hierarchical models like the one
just described are known as feature nets
because they involve a network of detectors that has feature detectors at its
bottom level. In the earliest feature nets proposed, activation flowed only
from the bottom up—from feature detectors to more complex detectors and so on
through a series of larger and larger units (see, for example, Selfridge,
1959). Said differently, the input pushes the process forward, and so we can
think of these processes as “data driven.” More recent models, however, have
also included a provision for “top-down” or “knowledge-driven”
processes—processes that are guided by the ideas and expectations that the
perceiver brings to the situation.
To see how top-down and bottom-up
processes interact, consider a problem in word recognition. Suppose you’re
shown a three-letter word in dim light. In this setting, your visual system
might register the fact that the word’s last two letters are AT; but at least initially, the system
has no information about the first letter. How, then, would you choose among MAT, CAT, and RAT? Suppose that, as part of the same experiment, you’ve just been
shown a series of words including several names of animals (dog,mouse, canary). This experience will
activate your detectors for these words, and the acti-vation is likely to
spread out to the memory neighbors of these detectors—including (probably) the
detectors for CAT and RAT. Activation of the CAT or RAT detector, in turn, will cause a top-down, knowledge-driven
activation of the detectors for the letters in these words, including C and R (Figure 5.15).
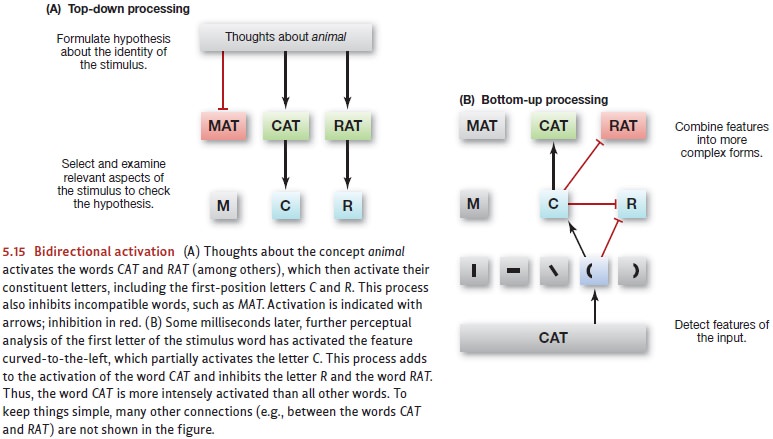
While all this is going on, the
data-driven analysis continues; by now, your visual sys-tem has likely detected
that the left edge of the target letter is curved (Figure 5.15B). This
bottom-up effect alone might not be enough to activate the detector for the
letter C; but notice that this
detector is also receiving some (top-down) stimulation (Figure 5.15A). As a
result, the C detector is now
receiving stimulation from two sources—from below (the feature detector) and
above (from CAT), and this
combination of inputs will probably be enough to activate the C detector. Then, once this detector is
activated, it will feed back to the CAT
detector, activating it still further. (For an example of models that work in
this way, see McClelland, Rumelhart, & Hinton, 1986; also Grainger, Rey,
& Dufau, 2008.)
It’s important, though, that we
can describe all of these steps in two different ways. If we look at the actual
mechanics of the process, we see that detectors are activating (or inhibiting)
other detectors; that’s the only thing going on here. At the same time, we can also
describe the process in broader terms: Basically, the initial activation of CAT functions as a knowledge-driven
“hypothesis” about the stimulus, and that hypothesis makes the visual system
more receptive to the relevant “data” coming from the feature detectors. In
this example, the arriving data confirm the hypothesis, thus leading to the
exclusion of alternative hypotheses.
With these points in view, let’s return to the question we asked earlier: We’ve discussed how the perceptual system interprets the input, and we’ve emphasized that the interpretation is guided by rules. But what processes in our mind actually do the “inter-preting”? We can now see that the interpretive process is carried out by a network of detectors, and the interpretive “rules” are built into the way the network functions. For example, how do we ensure that the perceptual interpretation is compatible with all the information in the input? This point is guaranteed by the fact that the feature detectors help shape the network’s output, and this simple fact makes it certain that the output will be constrained by information in the stimulus. How do we ensure that our perception contains no contradiction (e.g., perceiving a surface to be both opaque and transparent)? This is guaranteed by the fact that detectors within the network can inhibit other (incompatible) detectors. With mechanisms like these in place, the network’s output is sure to satisfy all of our rules—or at least to provide the best compromise possible among the various rules.
From Features to Geons to Meaning
The network we’ve described so
far can easily recognize targets as simple as squares and circles, letters and
numerals. But what about the endless variety of three-dimensional objects that
surround us? For these, theorists believe we can still rely on a network of
detectors; but we need to add some intermediate levels of analysis.
A model proposed by Irving
Biederman, for example, relies on some 30 geomet-ric components that he calls geons (short for “geometric ions”).
These are three-dimensional figures such as cubes, cylinders, pyramids, and the
like; nearly all objects can be broken down perceptually into some number of
these geons. To recognize an object, therefore, we first identify its features
and then use these to identify the component geons and their relationships. We
then consult our visual memory to see if there’s an object that matches up with
what we’ve detected (Biederman, 1987; Figure 5.16).
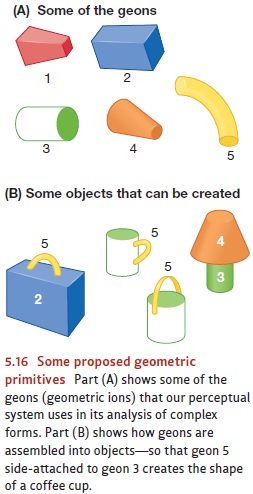
In Biederman’s system, we might
describe a lamp, say, as being a certain geon (num-ber 4 in Figure 5.16) on top
of another (number 3). This combination of geons gives us a complete
description of the lamp’s geometry. But this isn’t the final step in object
recognition, because we still need to assign some meaning to this geometry. We
need to know that the shape is something we call a lamp—that it’s an object that casts light and can be switched on
and off.
As with most other aspects of
perception, those further steps usually seem effortless. We see a lamp (or a
chair, or a pickup truck) and immediately know what it is and what it is for.
But as easy as these steps seem, they’re far from trivial. Remarkably, we can
find cases in which the visual system successfully produces an accurate
structural descrip-tion but fails in these last steps of endowing the perceived
object with meaning. The cases involve patients who have suffered certain brain
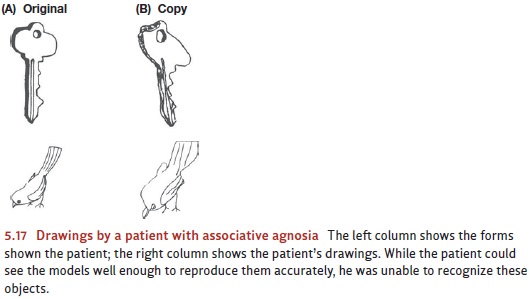
lesions leading to visual agnosia (Farah, 1990). Patients with this disorder
can see, but they can’t recognize what they see . Some patients can perceive
objects well enough to draw recognizable pictures of them; but they’re unable
to identify either the objects or their own drawings. One patient, for example,
produced the drawings shown in Figure 5.17. When asked to say what he had
drawn, he couldn’t name the key and said the bird was a tree stump. He
evidently had formed adequate structural descriptions of these objects, but his
ability to process what he saw stopped there; his perceptions were stripped of
their meaning (Farah, 1990, 2004).
Related Topics