Chapter: Security in Computing : Program Security
Modularity, Encapsulation, and Information Hiding
Modularity, Encapsulation, and Information Hiding
Code usually has a long
shelf-life and is enhanced over time as needs change and faults are found and
fixed. For this reason, a key principle of software engineering is to create a
design or code in small, self-contained units, called components or modules;
when a system is written this way, we say that it is modular. Modularity offers
advantages for program development in general and security in particular.
If a component is isolated
from the effects of other components, then it is easier to trace a problem to
the fault that caused it and to limit the damage the fault causes. It is also
easier to maintain the system, since changes to an isolated component do not
affect other components. And it is easier to see where vulnerabilities may lie
if the component is isolated. We call this isolation encapsulation.
Information hiding is another characteristic of modular software.
When information is hidden, each component hides its precise implementation or some other design
decision from the others. Thus, when a change is needed, the overall design can
remain intact while only the necessary changes are made to particular
components.
Let us look at these
characteristics in more detail.
Modularity
Modularization is the process of dividing a
task into subtasks. This division is done on a logical or functional basis.
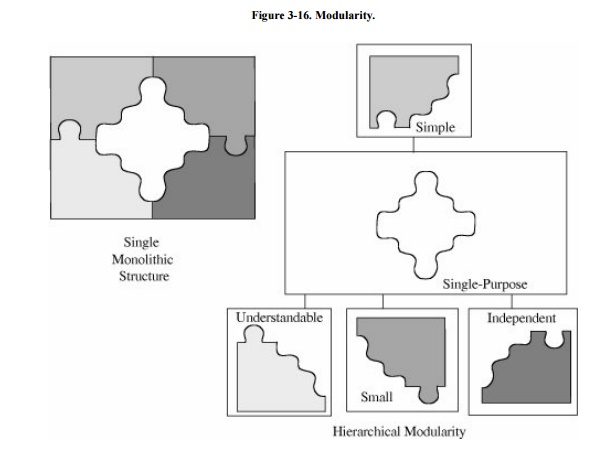
Each component performs a separate, independent part of the task. Modularity is depicted in Figure 3-16. The goal is to have each component
meet four conditions:
·
single-purpose: performs one function
·
small: consists of an amount of information for which a human can
readily grasp both structure and content
·
simple: is of a low degree of complexity so that a human can
readily understand the purpose and structure of the module
·
independent: performs a task isolated from other modules
Other component
characteristics, such as having a single input and single output or using a
limited set of programming constructs, indicate modularity. From a security
standpoint, modularity should improve the likelihood that an implementation is
correct.
In particular, smallness is
an important quality that can help security analysts understand what each
component does. That is, in good software, design and program units should be
only as large as needed to perform their required functions. There are several
advantages to having small, independent components.
Maintenance. If a component implements a single
function, it can be replaced easily with a revised one if necessary. The new
component may be needed because of a change in requirements, hardware, or
environment. Sometimes the replacement is an enhancement, using a smaller,
faster, more correct, or otherwise better module. The interfaces between this
component and the remainder of the design or code are few and well described,
so the effects of the replacement are evident.
Understandability. A system composed of many small components is
usually easier to comprehend than one large, unstructured block of code.
Reuse. Components developed
for one purpose can often be reused in other systems. Reuse of correct,
existing design or code components can significantly reduce the difficulty of
implementation and testing.
Correctness. A failure can be quickly traced to its cause if the components
perform only one task each.
Testing. A single component with well-defined inputs, outputs, and function
can be tested exhaustively by itself, without concern for its effects on other modules (other than the expected function
and output, of course).
Security analysts must be
able to understand each component as an independent unit and be assured of its
limited effect on other components.
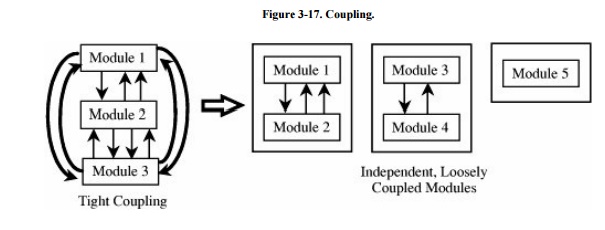
A modular component usually
has high cohesion and low coupling. By cohesion,
we mean that all the elements of a component have a logical and functional
reason for being there; every aspect of the component is tied to the
component's single purpose. A highly cohesive component has a high degree of
focus on the purpose; a low degree of cohesion means that the component's
contents are an unrelated jumble of actions, often put together because of
time-dependencies or convenience.
Coupling refers to the degree with
which a component depends on other components in the system. Thus, low or loose
coupling is better than high or
tight coupling because the loosely coupled components are free from unwitting
interference from other components. This difference in coupling is shown in Figure 3-17.
Encapsulation
Encapsulation hides a
component's implementation details, but it does not necessarily mean complete
isolation. Many components must share information with other components,
usually with good reason. However, this sharing is carefully documented so that
a component is affected only in known ways by others in the system. Sharing is
minimized so that the fewest interfaces possible are used. Limited interfaces
reduce the number of covert channels that can be constructed.
An encapsulated component's
protective boundary can be translucent or transparent, as needed. Berard [BER00] notes that encapsulation is the
"technique for packaging the information [inside a component] in such a
way as to hide what should be hidden and make visible what is intended to be
visible."
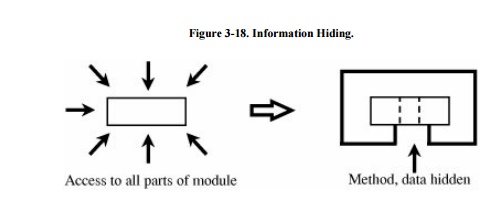
Information Hiding
Developers who work where
modularization is stressed can be sure that other components will have limited
effect on the ones they write. Thus, we can think of a component as a kind of
black box, with certain well-defined inputs and outputs and a well-defined
function. Other components' designers do not need to know how the module
completes its function; it is enough to be assured that the component performs
its task in some correct manner.
This concealment is the information hiding,
depicted in Figure 3-18. Information
hiding is desirable because developers cannot easily and maliciously alter the
components of others if they do not know how the components work.
These three
characteristicsmodularity, encapsulation, and information hidingare fundamental
principles of software engineering. They are also good security practices
because they lead to modules that can be understood, analyzed, and trusted.
Mutual Suspicion
Programs are not always trustworthy.
Even with an operating system to enforce access limitations, it may be
impossible or infeasible to bound the access privileges of an untested program
effectively. In this case, the user U is legitimately suspicious of a new
program P. However, program P may be invoked by another program, Q. There is no
way for Q to know that P is correct or proper, any more than a user knows that
of P.
Therefore, we use the concept
of mutual suspicion to describe the
relationship between two programs. Mutually suspicious programs operate as if
other routines in the system were malicious or incorrect. A calling program
cannot trust its called subprocedures to be correct, and a called subprocedure
cannot trust its calling program to be correct. Each protects its interface
data so that the other has only limited access. For example, a procedure to
sort the entries in a list cannot be trusted not to modify those elements,
while that procedure cannot trust its caller to provide any list at all or to
supply the number of elements predicted.
Confinement
Confinement is a technique
used by an operating system on a suspected program. A confined program is
strictly limited in what system resources it can access. If a program is not
trustworthy, the data it can access are strictly limited. Strong confinement
would be helpful in limiting the spread of viruses. Since a virus spreads by
means of transitivity and shared data, all the data and programs within a
single compartment of a confined program can affect only the data and programs
in the same compartment. Therefore, the virus can spread only to things in that
compartment; it cannot get outside the compartment.
Genetic Diversity
At your local electronics
shop you can buy a combination printerscannercopierfax machine. It comes at a
good price (compared to costs of the four separate components) because there is
considerable overlap in functionality among those four. It is compact, and you
need only install one thing on your system, not four. But if any part of it
fails, you lose a lot of capabilities all at once.
Related to the argument for
modularity and information hiding and reuse or interchangeability of software
components, some people recommend genetic diversity: it is risky having many
components of a system come from one source, they say.
Geer at al. [GEE03a] wrote a report examining the monoculture
of computing dominated by one manufacturer: Microsoft today, IBM yesterday,
unknown tomorrow. They look at the parallel in agriculture where an entire crop
is vulnerable to a single pathogen. Malicious code from the Morris worm to the
Code Red virus was especially harmful because a significant proportion of the
world's computers ran versions of the same operating systems (Unix for Morris,
Windows for Code Red). Geer refined the argument in [GEE03b],
which was debated by Whitaker [WHI03b]
and Aucsmith [AUC03].
Tight integration of products
is a similar concern. The Windows operating system is tightly linked to
Internet Explorer, the Office Suite, and the Outlook e-mail handler. A
vulnerability in one of these can also affect the others. Because of the tight
integration, fixing a vulnerability in one can have an impact on the others,
whereas a vulnerability in another vendor's browser, for example, can affect
Word only to the extent they communicate through a well-defined interface.
Peer Reviews
We turn next to the process of developing
software. Certain practices and techniques can assist us in finding real and
potential security flaws (as well as other faults) and fixing them before we
turn the system over to the users. Pfleeger et al. [PFL01]
recommend several key techniques for building what they call "solid
software":
·
peer reviews
·
hazard analysis
·
testing
·
good design
·
prediction
·
static analysis
·
configuration management
·
analysis of mistakes
Here, we look at each
practice briefly, and we describe its relevance to security controls. We begin
with peer reviews.
You have probably been doing
some form of review for as many years as you have been writing code:
desk-checking your work or asking a colleague to look over a routine to ferret
out any problems. Today, a software review is associated with several formal
process steps to make it more effective, and we review any artifact of the
development process, not just code. But the essence of a review remains the
same: sharing a product with colleagues able to comment about its correctness.
There are careful distinctions among three types of peer reviews:
Review: The artifact is presented informally to a team of reviewers; the
goal is consensus and buy-in before development proceeds further.
Walk-through: The artifact is presented to the team by its creator, who leads and
controls the discussion. Here, education is the goal, and the focus is on learning about a single document.
Inspection: This more formal process is a detailed analysis in which the
artifact is checked against a prepared list of concerns. The creator does not lead the discussion,
and the fault identification and correction are often controlled by statistical
measurements.
A wise engineer who finds a
fault can deal with it in at least three ways:
·
by learning how, when, and why errors occur
·
by taking action to prevent mistakes
·
by scrutinizing products to find the instances and effects of errors
that were missed
Peer reviews address this
problem directly. Unfortunately, many organizations give only lip service to
peer review, and reviews are still not part of mainstream software engineering
activities.
But there are compelling
reasons to do reviews. An overwhelming amount of evidence suggests that various
types of peer review in software engineering can be extraordinarily effective.
For example, early studies at Hewlett-Packard in the 1980s revealed that those
developers performing peer review on their projects enjoyed a significant
advantage over those relying only on traditional dynamic testing techniques,
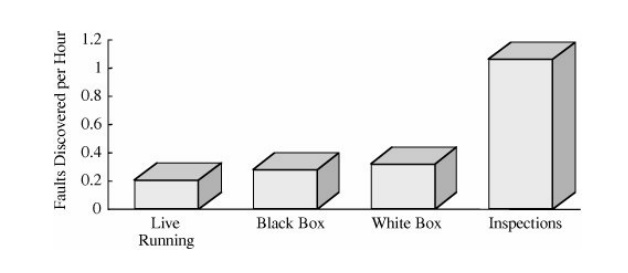
whether black box or white box. Figure 3 -19
compares the fault discovery rate (that is, faults discovered per hour) among
white-box testing, black-box testing, inspections, and software execution. It
is clear that inspections discovered far more faults in the same period of time
than other alternatives. This result is particularly compelling for large,
secure systems, where live running for fault discovery may not be an option.
Researchers and practitioners have repeatedly
shown the effectiveness of reviews. For instance, Jones [JON91] summarized the data in his large
repository of project information to paint a picture of how reviews and
inspections find faults relative to other discovery activities. Because
products vary so wildly by size, Table 3-6
presents the fault discovery rates relative to the number of thousands of lines
of code in the delivered product.

The inspection process involves several
important steps: planning, individual preparation, a logging meeting, rework,
and reinspection. Details about how to perform reviews and inspections can be
found in software engineering books such as [PFL01]
and [PFL06a].
During the review process,
someone should keep careful track of what each reviewer discovers and how
quickly he or she discovers it. This log suggests not only whether particular
reviewers need training but also whether certain kinds of faults are harder to
find than others. Additionally, a root cause analysis for each fault found may
reveal that the fault could have been discovered earlier in the process. For
example, a requirements fault that surfaces during a code review should
probably have been found during a requirements review. If there are no
requirements reviews, you can start performing them. If there are requirements
reviews, you can examine why this fault was missed and then improve the
requirements review process.
The fault log can also be
used to build a checklist of items to be sought in future reviews. The review
team can use the checklist as a basis for questioning what can go wrong and
where. In particular, the checklist can remind the team of security breaches,
such as unchecked buffer overflows, that should be caught and fixed before the
system is placed in the field. A rigorous design or code review can locate
trapdoors, Trojan horses, salami attacks, worms, viruses, and other program
flaws. A crafty programmer can conceal some of these flaws, but the chance of
discovery rises when competent programmers review the design and code,
especially when the components are small and encapsulated. Management should
use demanding reviews throughout development to ensure the ultimate security of
the programs.
Related Topics