Chapter: Security in Computing : Program Security
Trapdoors - Targeted Malicious Code: Examples, Causes
Targeted Malicious Code
So far, we have looked at
anonymous code written to affect users and machines indiscriminately. Another
class of malicious code is written for a particular system, for a particular
application, and for a particular purpose. Many of the virus writers'
techniques apply, but there are also some new ones. Bradbury [BRA06] looks at the change over time in
objectives and skills of malicious code authors.
Trapdoors
A trapdoor is an undocumented
entry point to a module. Developers insert trapdoors during code development,
perhaps to test the module, to provide "hooks" by which to connect
future modifications or enhancements, or to allow access if the module should
fail in the future. In addition to these legitimate uses, trapdoors can allow a
programmer access to a program once it is placed in production.
Examples of Trapdoors
Because computing systems are
complex structures, programmers usually develop and test systems in a methodical,
organized, modular manner, taking advantage of the way the system is composed
of modules or components. Often, programmers first test each small component of
the system separate from the other components, in a step called unit testing, to ensure that the
component works correctly by itself. Then, developers test components together
during integration testing, to see
how they function as they send messages and data from one to the other. Rather
than paste all the components together in a "big bang" approach, the
testers group logical clusters of a few components, and each cluster is tested
in a way that allows testers to control and understand what might make a
component or its interface fail. (For a more detailed look at testing, see
Pfleeger and Atlee [PFL06a].)
To test a component on its own, the developer
or tester cannot use the surrounding routines that prepare input or work with
output. Instead, it is usually necessary to write "stubs" and
"drivers," simple routines to inject data in and extract results from
the component being tested. As testing continues, these stubs and drivers are
discarded because they are replaced by the actual components whose functions
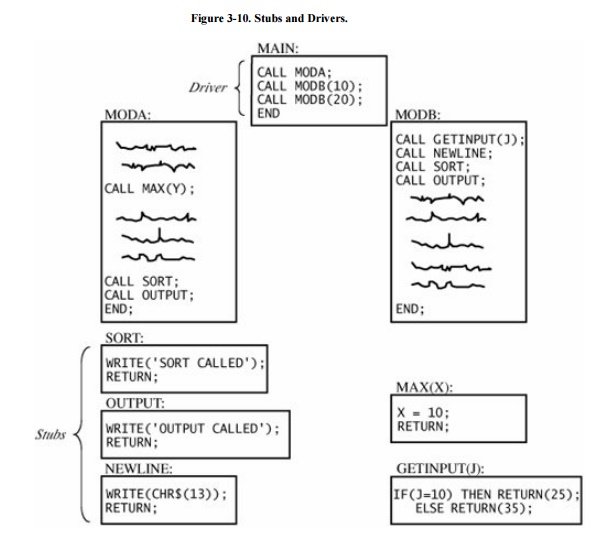
they mimic. For example, the two modules MODA and MODB in Figure 3-10 are being tested with the driver MAIN
and the stubs SORT, OUTPUT, and NEWLINE.
During both unit and
integration testing, faults are usually discovered in components. Sometimes,
when the source of a problem is not obvious, the developers insert debugging
code in suspicious modules; the debugging code makes visible what is going on
as the components execute and interact. Thus, the extra code may force
components to display the intermediate results of a computation, to print the
number of each step as it is executed, or to perform extra computations to
check the validity of previous components.
To control stubs or invoke
debugging code, the programmer embeds special control sequences in the
component's design, specifically to support testing. For example, a component
in a text formatting system might be designed to recognize commands such as
.PAGE, .TITLE, and .SKIP. During testing, the programmer may have invoked the
debugging code, using a command with a series of parameters of the form var =
value. This command allows the programmer to modify the values of internal
program variables during execution, either to test corrections to this
component or to supply values passed to components this one calls.
Command insertion is a
recognized testing practice. However, if left in place after testing, the extra
commands can become a problem. They are undocumented control sequences that
produce side effects and can be used as trapdoors. In fact, the Internet worm
spread its infection by using just such a debugging trapdoor in an electronic
mail program.
Poor error checking is another source of trapdoors. A good developer
will design a system so that any data value is checked before it is used; the
checking involves making sure the data type is correct as well as ensuring that
the value is within acceptable bounds. But in some poorly designed systems,
unacceptable input may not be caught and can be passed on for use in
unanticipated ways. For example, a component's code may check for one of three
expected sequences; finding none of the three, it should recognize an error.
Suppose the developer uses a CASE statement to look for each of the three
possibilities. A careless programmer may allow a failure simply to fall through
the CASE without being flagged as an error. The fingerd flaw exploited by the
Morris worm occurs exactly that way: A C library I/O routine fails to check
whether characters are left in the input buffer before returning a pointer to a
supposed next character.
Hardware processor design
provides another common example of this kind of security flaw. Here, it often
happens that not all possible binary opcode values have matching machine
instructions. The undefined opcodes sometimes implement peculiar instructions,
either because of an intent to test the processor design or because of an
oversight by the processor designer. Undefined opcodes are the hardware
counterpart of poor error checking for software.
As with viruses, trapdoors are not always bad.
They can be very useful in finding security flaws. Auditors sometimes request
trapdoors in production programs to insert fictitious but identifiable
transactions into the system. Then, the auditors trace the flow of these
transactions through the system. However, trapdoors must be documented, access
to them should be strongly controlled, and they must be designed and used with
full understanding of the potential consequences.
Causes of Trapdoors
Developers usually remove
trapdoors during program development, once their intended usefulness is spent.
However, trapdoors can persist in production programs because the developers
·
forget to remove them
·
intentionally leave them in the program for testing
·
intentionally leave them in the program for maintenance of the
finished program, or
·
intentionally leave them in the program as a covert means of access
to the component after it becomes an accepted part of a production system
The first case is an
unintentional security blunder, the next two are serious exposures of the
system's security, and the fourth is the first step of an outright attack. It
is important to remember that the fault is not with the trapdoor itself, which
can be a useful technique for program testing, correction, and maintenance.
Rather, the fault is with the system development process, which does not ensure
that the trapdoor is "closed" when it is no longer needed. That is,
the trapdoor becomes a vulnerability if no one notices it or acts to prevent or
control its use in vulnerable situations.
In general, trapdoors are a
vulnerability when they expose the system to modification during execution.
They can be exploited by the original developers or used by anyone who
discovers the trapdoor by accident or through exhaustive trials. A system is
not secure when someone believes that no one else would find the hole.
Related Topics