Chapter: Security in Computing : Program Security
Nonmalicious Program Errors
Nonmalicious Program Errors
Being human, programmers and
other developers make many mistakes, most of which are unintentional and nonmalicious.
Many such errors cause program malfunctions but do not lead to more serious
security vulnerabilities. However, a few classes of errors have plagued
programmers and security professionals for decades, and there is no reason to
believe they will disappear. In this section we consider three classic error
types that have enabled many recent security breaches. We explain each type,
why it is relevant to security, and how it can be prevented or mitigated.
Buffer Overflows
A buffer overflow is the computing
equivalent of trying to pour two liters of water into a one-liter pitcher: Some
water is going to spill out and make a mess. And in computing, what a mess
these errors have made!
Definition
A buffer (or array or string)
is a space in which data can be held. A buffer resides in memory. Because
memory is finite, a buffer's capacity is finite. For this reason, in many
programming languages the programmer must declare the buffer's maximum size so
that the compiler can set aside that amount of space.
Let us look at an example to
see how buffer overflows can happen. Suppose a C language program contains the
declaration:
char sample[10];
The compiler sets aside 10
bytes to store this buffer, one byte for each of the 10 elements of the array, sample[0] tHRough sample[9]. Now we execute the
statement:
sample[10] = 'B';
The subscript is out of
bounds (that is, it does not fall between 0 and 9), so we have a problem. The
nicest outcome (from a security perspective) is for the compiler to detect the
problem and mark the error during compilation. However, if the statement were
sample[i] = 'B';
we could not identify the
problem until i was set during execution to
a too-big subscript. It would be useful if, during execution, the system
produced an error message warning of a subscript out of bounds. Unfortunately,
in some languages, buffer sizes do not have to be predefined, so there is no
way to detect an out-of-bounds error. More importantly, the code needed to
check each subscript against its potential maximum value takes time and space
during execution, and the resources are applied to catch a problem that occurs
relatively infrequently. Even if the compiler were careful in analyzing the
buffer declaration and use, this same problem can be caused with pointers, for
which there is no reasonable way to define a proper limit. Thus, some compilers
do not generate the code to check for exceeding bounds.
Let us examine this problem
more closely. It is important to recognize that the potential overflow causes a
serious problem only in some instances. The problem's occurrence depends on
what is adjacent to the array sample. For example, suppose each of the ten elements
of the array sample is filled with the letter A
and the erroneous reference uses the letter B, as follows:
for
(i=0; i<=9; i++) sample[i] = 'A';
sample[10] = 'B'
All program and data elements
are in memory during execution, sharing space with the operating system, other
code, and resident routines. So there are four cases to consider in deciding
where the 'B' goes, as shown in Figure 3 -1.
If the extra character overflows into the user's data space, it simply
overwrites an existing variable value (or it may be written into an as-yet
unused location), perhaps affecting the program's result, but affecting no
other program or data.
Figure 3-1. Places Where a
Buffer Can Overflow.
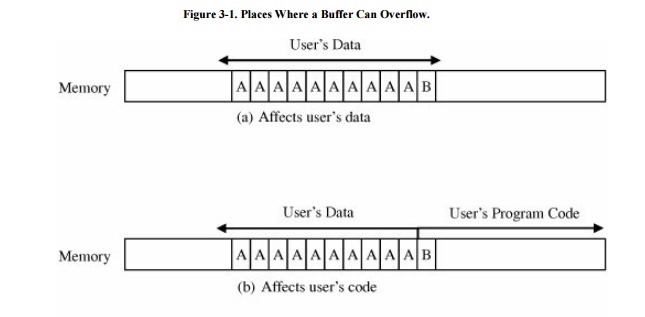
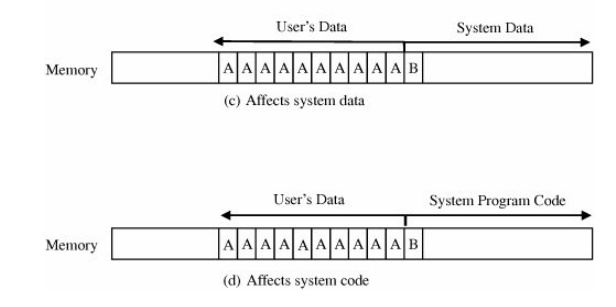
In the second case, the 'B'
goes into the user's program area. If it overlays an already executed
instruction (which will not be executed again), the user should perceive no
effect. If it overlays an instruction that is not yet executed, the machine
will try to execute an instruction with operation code 0x42, the internal code
for the character 'B'. If there is no instruction with operation code 0x42, the
system will halt on an illegal instruction exception. Otherwise, the machine
will use subsequent bytes as if they were the rest of the instruction, with
success or failure depending on the meaning of the contents. Again, only the
user is likely to experience an effect.
The most interesting cases
occur when the system owns the space immediately after the array that
overflows. Spilling over into system data or code areas produces similar
results to those for the user's space: computing with a faulty value or trying
to execute an improper operation.
Security Implication
In this section we consider
program flaws from unintentional or nonmalicious causes. Remember, however,
that even if a flaw came from an honest mistake, the flaw can still cause
serious harm. A malicious attacker can exploit these flaws.
Let us suppose that a
malicious person understands the damage that can be done by a buffer overflow;
that is, we are dealing with more than simply a normal, errant programmer. The
malicious programmer looks at the four cases illustrated in Figure 3 -1 and thinks deviously about the last
two: What data values could the attacker insert just after the buffer to cause
mischief or damage, and what planned instruction codes could the system be
forced to execute? There are many possible answers, some of which are more
malevolent than others. Here, we present two buffer overflow attacks that are
used frequently. (See [ALE96] for more
details.)
First, the attacker may
replace code in the system space. Remember that every program is invoked by the
operating system and that the operating system may run with higher privileges
than those of a regular program. Thus, if the attacker can gain control by
masquerading as the operating system, the attacker can execute many commands in
a powerful role. Therefore, by replacing a few instructions right after
returning from his or her own procedure, the attacker regains control from the
operating system, possibly with raised privileges. If the buffer overflows into
system code space, the attacker merely inserts overflow data that correspond to
the machine code for instructions.
On the other hand, the
attacker may make use of the stack pointer or the return register. Subprocedure
calls are handled with a stack, a data structure in which the most recent item
inserted is the next one removed (last arrived, first served). This structure
works well because procedure calls can be nested, with each return causing
control to transfer back to the immediately preceding routine at its point of
execution. Each time a procedure is called, its parameters, the return address
(the address immediately after its call), and other local values are pushed
onto a stack. An old stack pointer is also pushed onto the stack, and a stack
pointer register is reloaded with the address of these new values. Control is
then transferred to the subprocedure.
As the subprocedure executes,
it fetches parameters that it finds by using the address pointed to by the
stack pointer. Typically, the stack pointer is a register in the processor.
Therefore, by causing an overflow into the stack, the attacker can change
either the old stack pointer (changing the context for the calling procedure)
or the return address (causing control to transfer where the attacker wants
when the subprocedure returns). Changing the context or return address allows
the attacker to redirect execution to a block of code the attacker wants.
In both these cases, a little
experimentation is needed to determine where the overflow is and how to control
it. But the work to be done is relatively smallprobably a day or two for a
competent analyst. These buffer overflows are carefully explained in a paper by
Mudge [MUD95] of the famed l0pht computer security group. Pincus and
Baker [PIN04] reviewed buffer overflows ten years after Mudge and found that, far from being
a minor aspect of attack, buffer overflows have been a very significant attack
vector and have spawned several other new attack types.
An alternative style of
buffer overflow occurs when parameter values are passed into a routine,
especially when the parameters are passed to a web server on the Internet.
Parameters are passed in the URL line, with a syntax similar to
http://www.somesite.com/subpage/userinput.asp?parm1=(808)555-1212
&parm2=2009Jan17
In this example, the page userinput receives two parameters, parm1 with value (808)555-
1212
(perhaps a U.S. telephone number) and parm2 with value 2009Jan17 (perhaps a date). The web browser on the
caller's machine will accept values from a user who probably completes fields on a form.
The browser encodes those values and transmits them back to the server's web
site.
The attacker might question
what the server would do with a really long telephone number, say, one with 500
or 1000 digits. But, you say, no telephone in the world has such a number; that
is probably exactly what the developer thought, so the developer may have
allocated 15 or 20 bytes for an expected maximum length telephone number. Will
the program crash with 500 digits? And if it crashes, can it be made to crash
in a predictable and usable way? (For the answer to this question, see
Litchfield's investigation of the Microsoft dialer program [LIT99].) Passing a
very long string to a web server is a slight variation on the classic buffer overflow,
but no less effective.
As noted earlier, buffer
overflows have existed almost as long as higher-level programming languages
with arrays. For a long time they were simply a minor annoyance to programmers
and users, a cause of errors and sometimes even system crashes. Rather
recently, attackers have used them as vehicles to cause first a system crash
and then a controlled failure with a serious security implication. The large
number of security vulnerabilities based on buffer overflows shows that developers
must pay more attention now to what had previously been thought to be just a
minor annoyance.
Incomplete Mediation
Incomplete mediation is another security problem that has been with
us for decades. Attackers are exploiting it to cause security problems.
Definition
Consider the example of the
previous section:
http://www.somesite.com/subpage/userinput.asp?parm1=(808)555-1212
&parm2=2009Jan17
The two parameters look like a telephone number
and a date. Probably the client's (user's) web browser enters those two values
in their specified format for easy processing on the server's side. What would
happen if parm2 were submitted as 1800Jan01?
Or 1800Feb30? Or 2048Min32? Or 1Aardvark2Many?
Something would likely fail.
As with buffer overflows, one possibility is that the system would fail
catastrophically, with a routine's failing on a data type error as it tried to
handle a month named "Min" or even a year (like 1800) that was out of
range. Another possibility is that the receiving program would continue to
execute but would generate a very wrong result. (For example, imagine the
amount of interest due today on a billing error with a start date of 1 Jan
1800.) Then again, the processing server might have a default condition,
deciding to treat 1Aardvark2Many as 3 July 1947. The possibilities are endless.
One way to address the
potential problems is to try to anticipate them. For instance, the programmer
in the examples above may have written code to check for correctness on the
client's side (that is, the user's browser). The client program can search for
and screen out errors. Or, to prevent the use of nonsense data, the program can
restrict choices only to valid ones. For example, the program supplying the
parameters might have solicited them by using a drop -down box or choice list
from which only the twelve conventional months would have been possible
choices. Similarly, the year could have been tested to ensure that the value
was between 1995 and 2015, and date numbers would have to have been appropriate
for the months in which they occur (no 30th of February, for example). Using
these verification techniques, the programmer may have felt well insulated from
the possible problems a careless or malicious user could cause.
However, the program is still
vulnerable. By packing the result into the return URL, the programmer left
these data fields in a place the user can access (and modify). In particular,
the user could edit the URL line, change any parameter values, and resend the
line. On the server side, there is no way for the server to tell if the
response line came from the client's browser or as a result of the user's
editing the URL directly. We say in this case that the data values are not
completely mediated: The sensitive data (namely, the parameter values) are in
an exposed, uncontrolled condition.
Security Implication
Incomplete mediation is easy
to exploit, but it has been exercised less often than buffer overflows.
Nevertheless, unchecked data values represent a serious potential vulnerability.
To demonstrate this flaw's
security implications, we use a real example; only the name of the vendor has
been changed to protect the guilty. Things, Inc., was a very large,
international vendor of consumer products, called Objects. The company was
ready to sell its Objects through a web site, using what appeared to be a
standard e-commerce application. The management at Things decided to let some
of its in-house developers produce the web site so that its customers could
order Objects directly from the web.
To accompany the web site,
Things developed a complete price list of its Objects, including pictures,
descriptions, and drop-down menus for size, shape, color, scent, and any other
properties. For example, a customer on the web could choose to buy 20 of part
number 555A Objects. If the price of one such part were $10, the web server
would correctly compute the price of the 20 parts to be $200. Then the customer
could decide whether to have the Objects shipped by boat, by ground
transportation, or sent electronically. If the customer were to choose boat
delivery, the customer's web browser would complete a form with parameters like
these:
http://www.things.com/order.asp?custID=101&part=555A&qy=20&price
=10&ship=boat&shipcost=5&total=205
So far, so good; everything
in the parameter passage looks correct. But this procedure leaves the parameter
statement open for malicious tampering. Things should not need to pass the
price of the items back to itself as an input parameter; presumably Things knows
how much its Objects cost, and they are unlikely to change dramatically since
the time the price was quoted a few screens earlier.
A malicious attacker may
decide to exploit this peculiarity by supplying instead the following URL,
where the price has been reduced from $205 to $25:
http://www.things.com/order.asp?custID=101&part=555A&qy=20&price
=1&ship=boat&shipcost=5&total=25
Surprise! It worked. The
attacker could have ordered Objects from Things in any quantity at any price.
And yes, this code was running on the web site for a while before the problem
was detected. From a security perspective, the most serious concern about this
flaw was the length of time that it could have run undetected. Had the whole
world suddenly made a rush to Things's web site and bought Objects at a
fraction of their price, Things probably would have noticed. But Things is
large enough that it would never have detected a few customers a day choosing
prices that were similar to (but smaller than) the real price, say 30 percent
off. The e-commerce division would have shown a slightly smaller profit than
other divisions, but the difference probably would not have been enough to
raise anyone's eyebrows; the vulnerability could have gone unnoticed for years.
Fortunately, Things hired a consultant to do a routine review of its code, and
the consultant found the error quickly.
This web program design flaw is easy to imagine
in other web settings. Those of us interested in security must ask ourselves
how many similar problems are there in running code today? And how will those
vulnerabilities ever be found?
Time-of-Check to Time-of-Use Errors
The third programming flaw we
investigate involves synchronization. To improve efficiency, modern processors
and operating systems usually change the order in which instructions and
procedures are executed. In particular, instructions that appear to be adjacent
may not actually be executed immediately after each other, either because of
intentionally changed order or because of the effects of other processes in
concurrent execution.
Definition
Access control is a
fundamental part of computer security; we want to make sure that only those who
should access an object are allowed that access. (We explore the access control
mechanisms in operating systems in greater detail in Chapter 4.) Every requested access must be governed by an
access policy stating who is allowed access to what; then the request must be
mediated by an access-policy-enforcement agent. But an incomplete mediation
problem occurs when access is not checked universally. The time-of-check to time-of-use (TOCTTOU) flaw concerns mediation that
is performed with a "bait and switch" in the middle. It is also known
as a serialization or synchronization flaw.
To understand the nature of this
flaw, consider a person's buying a sculpture that costs $100. The buyer removes
five $20 bills from a wallet, carefully counts them in front of the seller, and
lays them on the table. Then the seller turns around to write a receipt. While
the seller's back is turned, the buyer takes back one $20 bill. When the seller
turns around, the buyer hands over the stack of bills, takes the receipt, and
leaves with the sculpture. Between the time the security was checked (counting
the bills) and the access (exchanging the sculpture for the bills), a condition
changed: What was checked is no longer valid when the object (that is, the
sculpture) is accessed.
A similar situation can occur with computing
systems. Suppose a request to access a file were presented as a data structure,
with the name of the file and the mode of access presented in the structure. An
example of such a structure is shown in Figure 3-2.

The data structure is
essentially a "work ticket," requiring a stamp of authorization; once
authorized, it is put on a queue of things to be done. Normally the access
control mediator receives the data structure, determines whether the access
should be allowed, and either rejects the access and stops or allows the access
and forwards the data structure to the file handler for processing.
To carry out this
authorization sequence, the access control mediator would have to look up the
file name (and the user identity and any other relevant parameters) in tables.
The mediator could compare the names in the table to the file name in the data
structure to determine whether access is appropriate. More likely, the mediator
would copy the file name into its own local storage area and compare from
there. Comparing from the copy leaves the data structure in the user's area,
under the user's control.
It is at this point that the incomplete
mediation flaw can be exploited. While the mediator is checking access rights
for the file my_file, the user could change the file name descriptor to
your_file, the value shown in Figure 3-3.
Having read the work ticket once, the mediator would not be expected to reread
the ticket before approving it; the mediator would approve the access and send
the now-modified descriptor to the file handler.
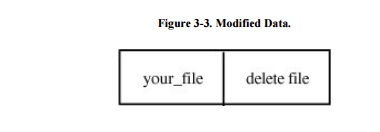
The problem is called a
time-of-check to time -of- use flaw because it exploits the delay between the
two times. That is, between the time the access was checked and the time the
result of the check was used, a change occurred, invalidating the result of the
check.
Security Implication
The security implication here is pretty clear:
Checking one action and performing another is an example of ineffective access
control. We must be wary whenever a time lag or loss of control occurs, making
sure that there is no way to corrupt the check's results during that interval.
Fortunately, there are ways
to prevent exploitation of the time lag. One way is to ensure that critical
parameters are not exposed during any loss of control. The access checking
software must own the request data until the requested action is complete.
Another way is to ensure serial integrity; that is, to allow no interruption
(loss of control) during the validation. Or the validation routine can
initially copy data from the user's space to the routine's areaout of the
user's reachand perform validation checks on the copy. Finally, the validation
routine can seal the request data with a checksum to detect modification.
Combinations of Nonmalicious Program Flaws
These three vulnerabilities are bad enough when
each is considered on its own. But perhaps the worst aspect of all three flaws
is that they can be used together as one step in a multistep attack. An
attacker may not be content with causing a buffer overflow. Instead the
attacker may begin a three-pronged attack by using a buffer overflow to disrupt
all execution of arbitrary code on a machine. At the same time, the attacker
may exploit a time-of-check to time-of-use flaw to add a new user ID to the
system. The attacker then logs in as the new user and exploits an incomplete
mediation flaw to obtain privileged status, and so forth. The clever attacker
uses flaws as common building blocks to build a complex attack. For this
reason, we must know about and protect against even simple flaws. (See Sidebar 3-3 for other examples of the effects of
unintentional errors.) Unfortunately, these kinds of flaws are widespread and
dangerous. As we see in the next section, innocuous-seeming program flaws can
be exploited by malicious attackers to plant intentionally harmful code.
Related Topics