Chapter: Fundamentals of Database Systems : Query Processing and Optimization, and Database Tuning : Algorithms for Query Processing and Optimization
Algorithms for Query Processing and Optimization
Part 8
Query
Processing and Optimization, and Database
Tuning
Chapter 19
Algorithms
for Query Processing and Optimization
In this chapter we discuss the techniques used internally by a DBMS to process, optimize, and execute high-level queries. A query expressed in a high-level query language such as SQL must first be scanned, parsed, and validated. The scanner identifies the query tokens—such as SQL keywords, attribute names, and relation names—that appear in the text of the query, whereas the parser checks the query syntax to determine whether it is formulated according to the syntax rules (rules of grammar) of the query language. The query must also be validated by checking that all attribute and relation names are valid and semantically meaningful names in the schema of the particular database being queried. An internal representation of the query is then created, usually as a tree data structure called a query tree. It is also possible to rep-resent the query using a graph data structure called a query graph. The DBMS must then devise an execution strategy or query plan for retrieving the results of the query from the database files. A query typically has many possible execution strategies, and the process of choosing a suitable one for processing a query is known as query optimization.
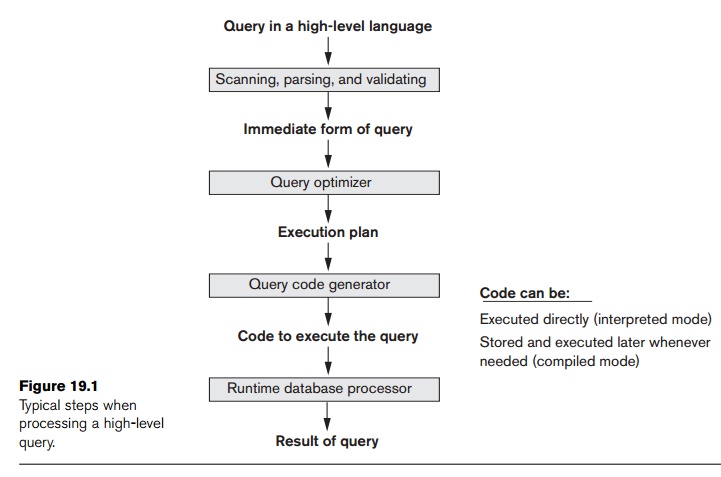
Figure 19.1 shows the different steps of
processing a high-level query. The query
optimizer module has the task of
producing a good execution plan, and the
code generator generates the code to execute that plan. The runtime database processor has the
task of running (executing) the query code, whether in compiled or interpreted
mode, to produce the query result. If a runtime error results, an error
mes-sage is generated by the runtime database processor.
The term optimization
is actually a misnomer because in some cases the chosen execution plan is not
the optimal (or absolute best) strategy—it is just a reasonably efficient strategy for executing the query. Finding the
optimal strategy is usually too time-consuming—except
for the simplest of queries. In addition, trying to find the optimal query
execution strategy may require detailed information on how the files are
implemented and even on the contents of the files—information that may not be
fully available in the DBMS catalog. Hence, planning
of a good execution strategy may be a more accurate description than query optimization.
For lower-level navigational database languages
in legacy systems—such as the net-work DML or the hierarchical DL/1 (see
Section 2.6)—the programmer must choose the query execution strategy while
writing a database program. If a DBMS provides only a navigational language,
there is limited need or opportunity
for extensive query optimization by the DBMS; instead, the programmer is given
the capability to choose the query execution strategy. On the other hand, a
high-level query language—such as SQL for relational DBMSs (RDBMSs) or OQL (see
Chapter 11) for object DBMSs (ODBMSs)—is more declarative in nature because it
specifies what the intended results of the query are, rather than identifying
the details of how the result should
be obtained. Query optimization is thus necessary for queries that are
specified in a high-level query language.
We will concentrate on describing query
optimization in the context of an RDBMS
because many of the techniques we describe have also been adapted for other
types of database management systems, such as ODBMSs. A relational DBMS must
systematically evaluate alternative query execution strategies and choose a
reasonably efficient or near-optimal strategy. Each DBMS typically has a number
of general database access algorithms that implement relational algebra
operations such as SELECT or JOIN (see Chapter 6) or combinations of these
operations. Only execution strategies that can be implemented by the DBMS
access algorithms and that apply to the particular query, as well as to the particular physical database design, can
be considered by the query optimization module.
This chapter starts with a general discussion
of how SQL queries are typically translated into relational algebra queries
and then optimized in Section 19.1. Then we discuss algorithms for implementing
relational algebra operations in Sections 19.2 through 19.6. Following this, we
give an overview of query optimization strategies. There are two main
techniques that are employed during query optimization. The first technique is
based on heuristic rules for
ordering the operations in a query execution strategy. A heuristic is a rule
that works well in most cases but is not guaranteed to work well in every
case. The rules typically reorder the operations in a query tree. The second
technique involves systematically
estimating the cost of different execution strategies and choosing the
execution plan with the lowest cost estimate. These techniques are usually
combined in a query optimizer. We discuss heuristic optimization in Section
19.7 and cost estimation in Section 19.8. Then we provide a brief overview of
the factors considered during query optimization in the Oracle commercial RDBMS
in Section 19.9. Section 19.10 introduces the topic of semantic query
optimization, in which known constraints are used as an aid to devising
efficient query execution strategies.
The topics covered in this chapter require that
the reader be familiar with the mate-rial presented in several earlier
chapters. In particular, the chapters on SQL (Chapters 4 and 5), relational
algebra (Chapter 6), and file structures and indexing (Chapters 17 and 18) are
a prerequisite to this chapter. Also, it is important to note that the topic of
query processing and optimization is vast, and we can only give an introduction
to the basic principles and techniques in this chapter.
Related Topics