Chapter: Embedded Systems Design : Interrupts and exceptions
RISC exceptions
RISC exceptions
RISC architectures have a slightly different approach to exception
handling compared to that of CISC architectures. This difference can catch
designers out.
Taking the PowerPC architecture as an example, there are many
similarities: an exception is still defined as a transition from the user state
to the supervisor state in response to either an external request or error, or
some internal condition that requires servicing. Generating an exception is the
only way to move from the user state to the supervisor state. Example
exceptions include external interrupts, page faults, memory protection
violations and bus errors. In many ways the exception handling is similar to
that used with CISC processors, in that the processor changes to the supervisor
state, vectors to an exception handler routine, which investigates the
exception and services it before returning control to the original program.
This general principle still holds but there are fundamental differences which
require careful consideration.
When an exception is recognised, the address of the instruc-tion to be
used by the original program when it restarts and the machine state register
(MSR) are stored in the supervisor registers, SRR0 and SRR1. The processor
moves into the supervisor state and starts to execute the handler, which
resides at the associated vector location in the vector table. The handler can,
by examining the DSISR and FPSCR registers, determine the exact cause and
rectify the problem or carry out the required function. Once completed, the rfi
instruction is executed. This restores the MSR and the instruction address from
the SRR0 and SRR1 registers and the interrupted program continues.

There are four general types of exception: asynchronous precise or
imprecise and synchronous precise and imprecise. Asynchronous and synchronous
refer to when the exception is caused: a synchronous exception is one that is
synchronised, i.e. caused by the instruction flow. An asynchronous exception is
one where an external event causes the exception; this can effectively occur at
any time and is not dependent on the instruction flow. A precise exception is
where the cause is precisely defined and is usually recoverable. A memory page
fault is a good example of this. An imprecise exception is usually a
catastrophic failure, where the processor cannot continue processing or allow a
par-ticular program or task to continue. A system reset or memory fault while
accessing the vector table falls into this category.
Synchronous precise
All instruction caused exceptions are handled as synchro-nous precise
exceptions. When such an exception is encountered during program execution, the
address of either the faulting instruction or the one after it is stored in
SRR0. The processor will have completed all the preceding instructions;
however, this does not guarantee that all memory accesses caused by these
instruc-tions are complete. The faulting instruction will be in an
indeter-minate state, i.e. it may have started and be partially or completely
completed. It is up to the exception handler to determine the instruction type
and its completion status using the information bits in the DSISR and FPSCR
registers.
Synchronous imprecise
This is generally not supported within the PowerPC archi-tecture and is
not present on the MPC601, MPC603 or MCP604 implementations. However, the
PowerPC architecture does specify the use of synchronous imprecise handling for
certain floating point exceptions and so this category may be implemented in
future processor designs.
Asynchronous precise
This exception type is used to handle external interrupts and
decrementer-caused exceptions. Both can occur at any time within the
instruction processing flow. All instructions being processed before the
exceptions are completed, although there is no guarantee that all the memory
accesses have completed. SRR0 stores the address of the instruction that would
have been ex-ecuted if no interrupt had occurred.
These exceptions can be masked by clearing the EE bit to zero in the
MSR. This forces the exceptions to be latched but not acted on. This bit is
automatically cleared to prevent this type of interrupt causing an exception
while other exceptions are being processed.
The number of events that can be latched while the EE bit is zero is not
stated. This potentially means that interrupts or decrementer exceptions could
be missed. If the latch is already full, any subsequent events are ignored. It
is therefore recom-mended that the exception handler performs some form of
handshaking to ensure that all interrupts are recognised.
Asynchronous imprecise
Only two types of exception are associated with this: system resets and
machine checks. With a system reset all current process-ing is stopped, all
internal registers and memories are reset; the processor executes the reset
vector code and effectively restarts processing. The machine check exception is
only taken if the ME bit of the MSR is set. If it is cleared, the processor
enters the checkstop state.
Recognising RISC exceptions
Recognising an exception in a superscalar processor, espe-cially one
where the instructions are executed out of program order, can be a little
tricky — to say the least. The PowerPC architecture handles synchronous
exceptions (i.e. those caused by the instruction stream) in strict program
order, even though instructions further on in the program flow may have already
generated an exception. In such cases, the first exception is han-dled as if
the following instructions have never been executed and the preceding ones have
all completed.
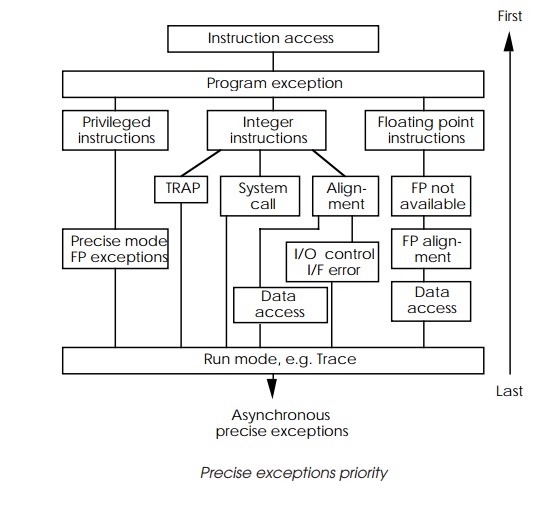
There are occasions when several exceptions can occur at the same time.
Here, the exceptions are handled on a priority basis using the priority scheme
shown in the table below. There is additional priority for synchronous precise
exceptions because it is possible for an instruction to generate more than one
exception. In these cases, the exceptions would be handled in their own
priority order as shown below.

If, for example, with the single-step trace mode enabled, an integer
instruction executed and encountered an alignment error, this exception would
be handled before the trace exception. These synchronous precise priorities all
have a higher priority than the level 4 and 5 asynchronous precise exceptions,
i.e. the external interrupt and decrementer exceptions.
When an exception is recognised, the continuation instruc-tion address
is stored in SRR0 and the MSR is stored in SRR1. This saves the machine context
and provides the interrupted program with the ability to continue. The
continuation instruction may not have started, or be partially or fully
complete, depending on the nature of the exception. The FPSCR and DSISR
registers contain further diagnostic information for the handler. When in this
state, external interrupts and decrementer exceptions are disabled. The EE bit
is cleared automatically to prevent such asynchronous events from unexpectedly
causing an exception while the handler is coping with the current one.
It is important to note that the machine status or context which is
necessary to allow normal execution to continue is automatically stored in SRR0
and SRR1 — which overwrites the previous contents. As a result, if another
exception occurs during an exception handler execution, the result can be
catastrophic: the exception handler’s machine status information in SRR0 and
SRR1 would be overwritten and lost. In addition, the status information in
FPSCR and DSISR is also overwritten. Without this information, the handler
cannot return to the original program. The new exception handler takes control,
processes its exception and, when the rfi instruction is executed, control is
passed back to the first exception handler. At this point, this handler does
not have its own machine context information to enable it to return control to
the original program. As a result the system will, at best, have lost track of
that program; at worst, it will probably crash.
This is not the case with the stack-based exception handlers used on
CISC processors. With these architectures, the machine status is stored on the
stack and, provided there is sufficient stack available, exceptions can safely
be nested, with each exception context safely and automatically stored on the
stack.
It is for this reason that the EE bit is automatically cleared to
disable the external and decrementer interrupts. Their asynchro-nous nature
means that they could occur at any time and if this happened at the beginning
of an exception routine, that routine’s ability to return control to the
original program would be lost. However, this does impose several constraints
when program ming exception handlers. For the maximum performance in the
exception handler, it cannot waste time by saving the machine status
information on a stack or elsewhere. In this case, exception handlers should
prevent any further exceptions by ensuring that they:
•
reside in memory and not be
swapped out;
•
have adequate stack and memory
resources and not cause page faults;
•
do not enable external or
decrementer interrupts;
•
do not cause any memory bus
errors.
For exception handlers that require maximum performance but also need
the best security and reliability, they should imme-diately save the machine
context, i.e. SRR registers FPSCR and DSISR, preferably on a stack before
continuing execution.
In both cases, if the handler has to use or modify any of the user
programming model, the registers must be saved prior to modification and they
must be restored prior to passing control back. To minimise this process, the
supervisor model has access to four additional general-purpose registers which
it can use inde-pendently of the general-purpose register file in the user
program-ming model.
Enabling RISC exceptions
Some exceptions can be enabled and disabled by the super-visor by
programming bits in the MSR. The EE bit controls external interrupts and
decrementer exceptions. The FE0 and FE1 bits control which floating point
exceptions are taken. Machine check exceptions are controlled via the ME bit.
Returning from RISC exceptions
As mentioned previously, the rfi instruction is used to return from the
exception handler to the original program. This instruction synchronises the
processor, restores the instruction address and machine state register and the
program restarts.
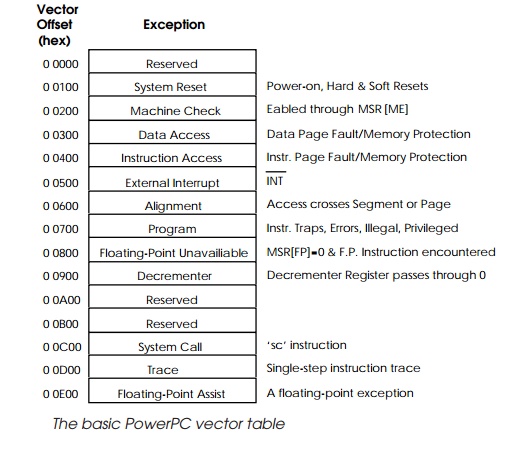
The vector table
Once an exception has been recognised, the program flow changes to the
associated exception handler contained in the vector table.
The vector table is a 16 kbyte block (0 to $3FFF) that is split into 256
byte divisions. Each division is allocated to a particular exception or group
of exceptions and contains the exception handler routine associated with that
exception. Unlike many other architectures, the vector table does not contain
pointers to the routines but the actual instruction sequences themselves. If
the handler is too large to fit in the division, a branch must be used to jump
to its continuation elsewhere in memory.
The table can be relocated by changing the EP bit in the machine state
register (MSR). If cleared, the table is located at $0000000. If the bit is set
to one (its state after reset) the vector table is relocated to $FFF00000.
Obviously, changing this bit before moving the vector table can cause immense
problems!
Identifying the cause
Most programmers will experience exception processing when a program has
crashed or a cryptic message is returned from a system call. The exception
handler can provide a lot of informa-tion about what has gone wrong and the
likely cause. In this section, each exception vector is described and an
indication of the possible causes and remedies given.
The first level investigation is the selection of the appropri-ate
exception handler from the vector table. However, the excep-tion handler must
investigate further to find out the exact cause before trying to survive the
exception. This is done by checking the information in the FPSCR, DSISR, DAR
and MSR registers, which contain different information for each particular
vector.
Related Topics