Chapter: Plant Biochemistry: A plant cell has three different genomes
In the nucleus the genetic information is divided among several chromosomes
In the nucleus the genetic information is divided among several chromosomes
For almost the whole of their developmental cycle, eukaryotic cells, as they are diploid, normally contain two chromosome sets, one set from the mother and the other set from the father. Only the generative cells (e.g., egg, pollen) are haploid, that is, they possess just one set of chromosomes. The DNA of the genome is replicated during the interphase of mitosis and gen erates in this way a quadruple chromosome set. During the anaphase, this set is distributed by the spindle apparatus to two opposite poles of the cell. Thus, after cell division, each daughter cell contains a double chromosome set and is diploid again. Colchicine, an alkaloid from the autumn crocus, inhibits the spindle apparatus and thus interrupts the distribution of the chromosomes during the anaphase. In such a case, all the chromosomes of the mother cell can end up in only one of the daughter cells, which then possesses four sets of chromosomes, to render it tetraploid. Infrequently this tetraploidy occurs spontaneously due to mitosis malfunction.
Tetraploidy is often stable and is then inherited by the following gene rations via somatic cells. Hexaploid plants can be generated by crossing tetraploid plants with diploid plants, although this is seldom successful. Tetraploid and hexaploid (polyploid) plants often show a higher growth rate, and this is why many polyploid crop plants are profitable in agriculture. Polyploid plants can also be generated by protoplast fusion, a method that can produce hybrids between two different breeding lines. When very differ ent species are crossed, the resulting diploid hybrids are often sterile due to incompatibilities in their chromosomes. In contrast, polyploid hybrids generally are fertile.

The chromosome content of various plants is listed in Table 20.2. The crucifer Arabidopsis thaliana (Fig. 20.1), an inconspicuous weed growing at the roadside in central Europe, has only 2×5 chromosomes with alto gether just 7×107 base pairs (Table 20.1). Arabidopsis corresponds in all details to a typical dicot plant and, when grown in a growth chamber, has a lifecycle of only six weeks. The breeding of a defined line of Arabidopsis thaliana by the botanist Friedrich Laibach (Frankfurt) in 1943 marked the beginning of the worldwide use ofArabidopsis as a model plant for the investigation of the functions of genes and the interplay of the gene products. By now the genome of Arabidopsis thaliana has been completely sequenced.

The often much higher number of chromosomes that can be found in other plants is in part the result of a gene combination. Hence, rape seed (Brassica napus) with 2×19 chromosomes is a crossing of Brassica rapa (2×10 chromosomes) and Brassica oleracea (2×9 chromosomes) (Table 20.2). In this case, a diploid genome is the result of crossing. In wheat, on the other hand, the successive crossing of three wild forms resulted in hexaploidy: Crossing of einkorn wheat and goat grass (2×7 chromosomes each) resulted in wild emmer wheat (4×7 chromosomes), and this crossed with another wild wheat resulted in the wheat (Triticum aestivum) with 6×7 chromosomes which is cultivated nowadays. Tobacco (Nicotiana tab-acum) is also a cross between two species (Nicotiana tomentosiformis and N. sylvestris), each with 2×12 chromosomes.
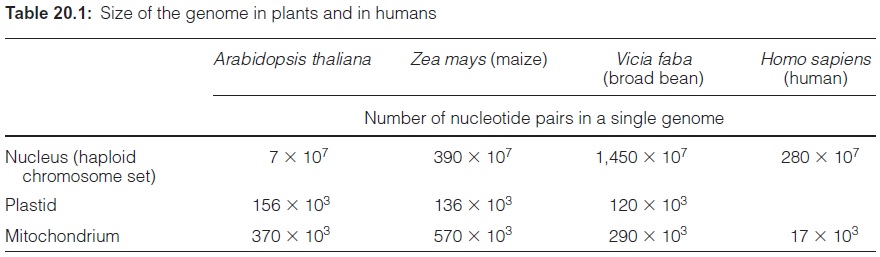
The nuclear genome of broad bean with 14.5×109 nucleotide pairs has a 200-fold higher DNA content than Arabidopsis. However, this does not mean that the number of protein-encoding genes (structural genes) in the broad bean genome is 200-fold higher than in Arabidopsis. Presumably the number of structural genes in both plants does not differ by more than a factor of two to three. The difference in the size of the genome is due to a different number of identical DNA sequences of various sizes arranged in sequence, termed repetitive DNA, of which a very large part may contain no encoding function at all. In broad bean, for example, 85% of the DNA rep resents repetitive sequences. This includes the tandem repeats, a large number (sometimes thousands) of identical repeated DNA sequences (of a unit size of 170–180 bp, sometimes also 350 bp). The tandem repeats are spread over the entire chromosome, often arranged as blocks, especially at the beginning and the end of the chromosome, and sometimes also in the interior. This highly repetitive DNA is calledsatellite DNA. This also includes microsatel lite DNA. Its sequence is genus or even species specific. In some plants, more than 15% of the total nuclear genome consists of satellite DNA. Perhaps it plays a role in the segregation of species. The sequence of the satellite DNA can be used as a species-specific marker in generating hybrids by protoplast fusion in order to check the outcome of the fusion in cell culture. The polymorphism of satellite DNA is also used for identifying human genomes in criminal cases.
The genes for ribosomal RNAs also occur as repetitive sequences and, together with the genes for some transfer RNAs, are present in the nuclear genome in several thousand copies.
In contrast, structural genes are present in only a few copies, sometimes just one (single-copy gene). Structural genes encoding for structurally and functionally related proteins with a high nucleotide identity often form a gene family. Such a gene family, for instance, is formed by the genes for the small subunit of the ribulose bisphosphate carboxylase, which exist several times in a slightly modified form in the nuclear genome (e.g., five times in tomato). So far 14 members of the light harvesting complex (LHC) gene family have been identified in tomato. Zein, which is present in maize kernels as a storage protein , is encoded by a gene family of about 100 genes. In Arabidopsis almost 40% of the proteins pre dicted from the genome sequence belong to gene families with more than five members, and 300 genes have been identified that encode P450 proteins.
The DNA sequences of plant nuclear genomes have been analyzed
It was a breakthrough in the year 2000 when the entire nuclear genome of Arabidopsis thaliana was completely sequenced (157 Mb). The sequence data revealed that the nuclear genome contains about 26,800 structural genes, twice as many as in the insect Drosophila. A comparison with known DNA sequences from animals showed that about one-third of the Arabidopsis genes are plant specific. By now the rice, poplar and moss genome have been sequenced (rice: 490 Mb, ca. 32,000 genes, poplar: 485 Mb ca. 45,600 genes,Physcomitrella patens: 511 Mb, ca. 28,000 genes).
The function of many of these genes is not yet known. The elucidation of these functions is a great challenge. One approach to solve this is a comparison of sequence data with identified sequences from microorganisms, animals, and plants, available in data banks, by means of bioinformatics. Another way is to eliminate the function of a certain gene by mutation and then investigate its effect on metabolism. A gene function can be eliminated by random mutations (e.g., by Ti-plasmids) (T-DNA insertion mutant). In this case, the mutated gene has to be identified. Alternatively, defined genes can be mutated by the RNAi technique. All these investigations require an automated evaluation with a very high technical expenditure. The project Arabidopsis 2010 (USA) and the German partner program AFGN (Arabidopsis functional genomics network) aim to fully elucidate the function of the Arabidopsis genome by the year 2010.
Related Topics