Chapter: Security in Computing : Program Security
Covert Channels: Programs That Leak Information
Covert Channels: Programs That Leak Information
So far, we have looked at
malicious code that performs unwelcome actions. Next, we turn to programs that
communicate information to people who should not receive it. The communication
travels unnoticed, accompanying other, perfectly proper, communications. The general
name for these extraordinary paths of communication is covert channels. The concept of a covert channel comes from a paper
by Lampson; Millen presents a good
taxonomy of covert channels.
Suppose a group of students
is preparing for an exam for which each question has four choices (a, b, c, d);
one student in the group, Sophie, understands the material perfectly and she
agrees to help the others. She says she will reveal the answers to the
questions, in order, by coughing once for answer "a," sighing for
answer "b," and so forth. Sophie uses a communications channel that
outsiders may not notice; her communications are hidden in an open channel.
This communication is a human example of a covert channel.
We begin by describing how a
programmer can create covert channels. The attack is more complex than one by a
lone programmer accessing a data source. A programmer who has direct access to
data can usually just read the data and write it to another file or print it
out. If, however, the programmer is one step removed from the datafor example,
outside the organization owning the datathe programmer must figure how to get
at the data. One way is to supply a bona fide program with a built-in Trojan
horse; once the horse is enabled, it finds and transmits the data. However, it
would be too bold to generate a report labeled "Send this report to Jane
Smith in Camden, Maine"; the programmer has to arrange to extract the data
more surreptitiously. Covert channels are a means of extracting data clandestinely.
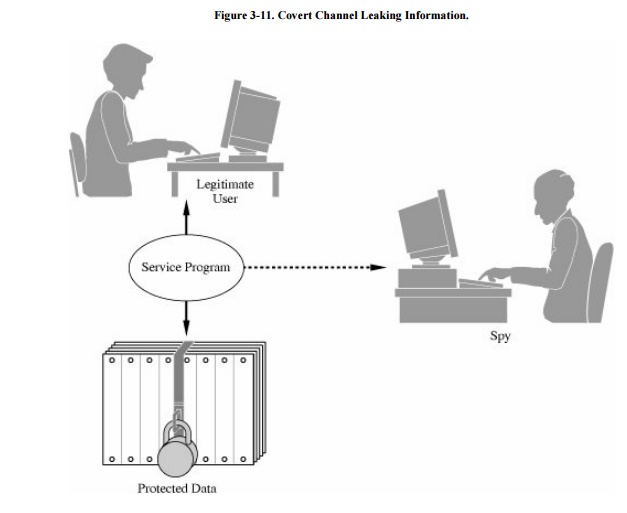
Figure 3-11 shows a
"service program" containing a Trojan horse that tries to copy
information from a legitimate user (who is allowed access to the
information) to a "spy" (who ought not be allowed to access the
information). The user may not know that a Trojan horse is running and may not
be in collusion to leak information to the spy.
Covert Channel Overview
A programmer should not have access to
sensitive data that a program processes after the program has been put into operation.
For example, a programmer for a bank has no need to access the names or
balances in depositors' accounts. Programmers for a securities firm have no
need to know what buy and sell orders exist for the clients. During program
testing, access to the real data may be justifiable, but not after the program
has been accepted for regular use.
Still, a programmer might be
able to profit from knowledge that a customer is about to sell a large amount
of a particular stock or that a large new account has just been opened.
Sometimes a programmer may want to develop a program that secretly communicates
some of the data on which it operates. In this case, the programmer is the
"spy," and the "user" is whoever ultimately runs the
program written by the programmer.
How to Create Covert Channels
A programmer can always find
ways to communicate data values covertly. Running a program that produces a
specific output report or displays a value may be too obvious. For example, in
some installations, a printed report might occasionally be scanned by security
staff before it is delivered to its intended recipient.
If printing the data values
themselves is too obvious, the programmer can encode the data values in another
innocuous report by varying the format of the output, changing the lengths of
lines, or printing or not printing certain values. For example, changing the
word "TOTAL" to "TOTALS" in a heading would not be noticed,
but this creates a 1-bit covert channel. The absence or presence of the S
conveys one bit of information. Numeric values can be inserted in insignificant
positions of output fields, and the number of lines per page can be changed.
Examples of these subtle channels are shown in Figure
3-12.


Storage Channels
Some covert channels are
called storage channels because they
pass information by using the presence or absence of objects in storage.
A simple example of a covert
channel is the file lock channel .
In multiuser systems, files can be "locked" to prevent two people
from writing to the same file at the same time (which could corrupt the file,
if one person writes over some of what the other wrote). The operating system
or database management system allows only one program to write to a file at a
time by blocking, delaying, or rejecting write requests from other programs. A
covert channel can signal one bit of information by whether or not a file is
locked.
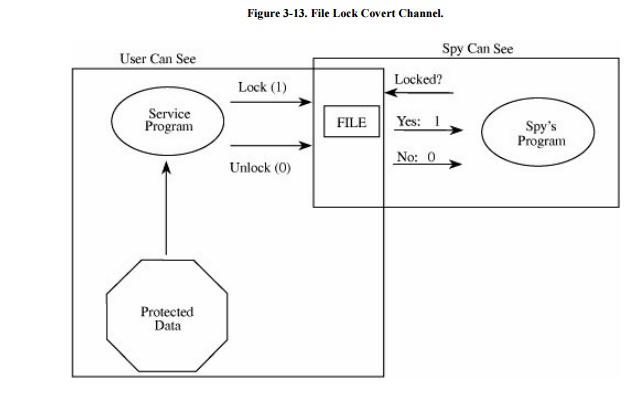
Remember that the service program contains a
Trojan horse written by the spy but run by the unsuspecting user. As shown in Figure 3-13, the service program reads
confidential data (to which the spy should not have access) and signals the
data one bit at a time by locking or not locking some file (any file, the
contents of which are arbitrary and not even modified). The service program and
the spy need a common timing source, broken into intervals. To signal a 1, the
service program locks the file for the interval; for a 0, it does not lock.
Later in the interval the spy tries to lock the file itself. If the spy program
cannot lock the file, it knows the service program must have locked the file,
and thus the spy program concludes the service program is signaling a 1; if the
spy program can lock the file, it knows the service program is signaling a 0.
This same approach can be
used with disk storage quotas or other resources. With disk storage, the
service program signals a 1 by creating an enormous file, so large that it
consumes most of the available disk space. The spy program later tries to
create a large file. If it succeeds, the spy program infers that the service
program did not create a large file, and so the service program is signaling a
0; otherwise, the spy program infers a 1. Similarly the existence of a file or
other resource of a particular name can be used to signal. Notice that the spy
does not need access to a file itself; the mere existence of the file is
adequate to signal. The spy can determine the existence of a file it cannot
read by trying to create a file of the same name; if the request to create is
rejected, the spy determines that the service program has such a file.
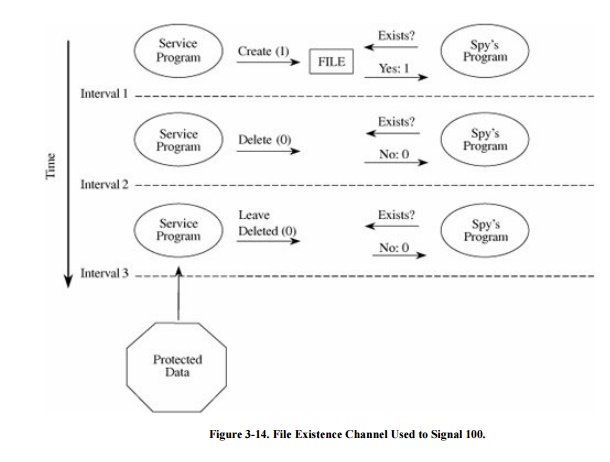
To signal more than one bit, the service
program and the spy program signal one bit in each time interval. Figure 3-14 shows a service program signaling the
string 100 by toggling the existence of a file.
In our final example, a
storage channel uses a server of unique identifiers. Recall that some bakeries,
banks, and other commercial establishments have a machine to distribute numbered
tickets so that customers can be served in the order in which they arrived.
Some computing systems provide a similar server of unique identifiers, usually
numbers, used to name temporary files, to tag and track messages, or to record
auditable events. Different processes can request the next unique identifier
from the server. But two cooperating processes can use the server to send a
signal: The spy process observes whether the numbers it receives are sequential
or whether a number is missing. A missing number implies that the service
program also requested a number, thereby signaling 1.
In all of these examples, the
service program and the spy need access to a shared resource (such as a file,
or even knowledge of the existence of a file) and a shared sense of time. As
shown, shared resources are common in multiuser environments, where the
resource may be as seemingly innocuous as whether a file exists, a device is
free, or space remains on disk. A source of shared time is also typically
available, since many programs need access to the current system time to set
timers, to record the time at which events occur, or to synchronize activities.
Karger and Wray [KAR91b] give a
real-life example of a covert channel in the movement of a disk's arm and then
describe ways to limit the potential information leakage from this channel.
Transferring data one bit at
a time must seem awfully slow. But computers operate at such speeds that even
the minuscule rate of 1 bit per millisecond (1/1000 second) would never be noticed
but could easily be handled by two processes. At that rate of 1000 bits per
second (which is unrealistically conservative), this entire book could be
leaked in about two days. Increasing the rate by an order of magnitude or two,
which is still quite conservative, reduces the transfer time to minutes.
Timing Channels
Other covert channels, called
timing channels, pass information by
using the speed at which things happen. Actually, timing channels are shared
resource channels in which the shared resource is time.
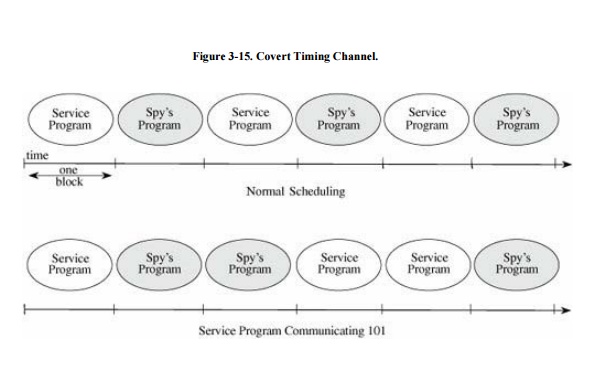
A service program uses a timing channel to
communicate by using or not using an assigned amount of computing time. In the
simple case, a multiprogrammed system with two user processes divides time into
blocks and allocates blocks of processing alternately to one process and the
other. A process is offered processing time, but if the process is waiting for
another event to occur and has no processing to do, it rejects the offer. The
service process either uses its block (to signal a 1) or rejects its block (to
signal a 0). Such a situation is shown in Figure
3-15, first with the service process and
the spy's process alternating, and then with the service process communicating
the string 101 to
the spy's process. In the second part of the example, the service program wants
to signal 0 in the third time block. It will do this by using just enough time
to determine that it wants to send a 0 and then pause. The spy process then
receives control for the remainder of the time block.
So far, all examples have
involved just the service process and the spy's process. But in fact, multiuser
computing systems typically have more than just two active processes. The only
complications added by more processes are that the two cooperating processes
must adjust their timings and deal with the possible interference from others.
For example, with the unique identifier channel, other processes will also
request identifiers. If on average n other processes will request m identifiers
each, then the service program will request more than n*m identifiers for a 1
and no identifiers for a 0. The gap dominates the effect of all other
processes. Also, the service process and the spy's process can use
sophisticated coding techniques to compress their communication and detect and
correct transmission errors caused by the effects of other unrelated processes.
Identifying Potential Covert Channels
In this description of covert
channels, ordinary things, such as the existence of a file or time used for a
computation, have been the medium through which a covert channel communicates.
Covert channels are not easy to find because these media are so numerous and
frequently used. Two relatively old techniques remain the standards for
locating potential covert channels. One works by analyzing the resources of a
system, and the other works at the source code level.
Shared Resource Matrix
Since the basis of a covert
channel is a shared resource, the search for potential covert channels involves
finding all shared resources and determining which processes can write to and
read from the resources. The technique was introduced by Kemmerer [KEM83]. Although laborious, the technique can be
automated.
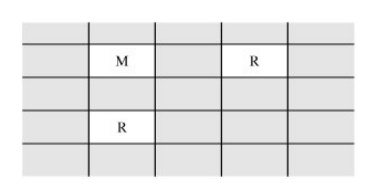
To use this technique, you construct a matrix
of resources (rows) and processes that can access them (columns). The matrix
entries are R for "can read (or observe) the resource" and M for
"can set (or modify, create, delete) the resource." For example, the
file lock channel has the matrix shown in Table 3-3.

This pattern identifies two resources and two
processes such that the second process is not allowed to read from the second
resource. However, the first process can pass the information to the second by
reading from the second resource and signaling the data through the first
resource. Thus, this pattern implies the potential information flow as shown
here.
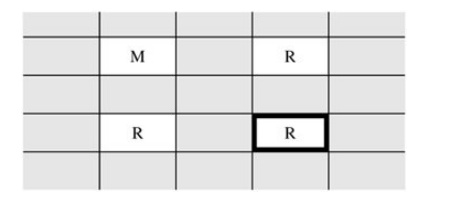
Next, you complete the shared resource matrix
by adding these implied information flows, and analyzing the matrix for
undesirable flows. Thus, you can tell that the spy's process can read the
confidential data by using a covert channel through the file lock, as shown in Table 3-4.

Information Flow Method
Denning [DEN76a] derived a technique for flow analysis from
a program's syntax. Conveniently, this analysis can be automated within a
compiler so that information flow potentials can be detected while a program is
under development.
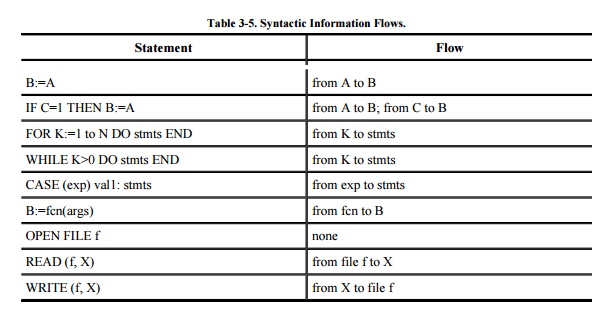
Using this method, we can
recognize nonobvious flows of information between statements in a program. For
example, we know that the statement B:=A, which assigns the value of A to the
variable B, obviously supports an information flow from A to B. This type of
flow is called an "explicit flow." Similarly, the pair of statements
B:=A; C:=B indicates an information flow from A to C (by way of B). The
conditional statement IF D=1 THEN B:=A has two flows: from A to B because of
the assignment, but also from D to B, because the value of B can change if and
only if the value of D is 1. This second flow is called an "implicit
flow."
The statement B:=fcn(args) supports an
information flow from the function fcn to B. At a superficial level, we can say
that there is a potential flow from the arguments args to B. However, we could
more closely analyze the function to determine whether the function's value
depended on all of its arguments and whether any global values, not part of the
argument list, affected the function's value. These information flows can be
traced from the bottom up: At the bottom there must be functions that call no
other functions, and we can analyze them and then use those results to analyze
the functions that call them. By looking at the elementary functions first, we
could say definitively whether there is a potential information flow from each
argument to the function's result and whether there are any flows from global
variables. Table 3-5 lists several
examples of syntactic information flows.
Finally, we put all the
pieces together to show which outputs are affected by which inputs. Although
this analysis sounds frightfully complicated, it can be automated during the
syntax analysis portion of compilation. This analysis can also be performed on
the higher-level design specification.
Covert Channel Conclusions
Covert channels represent a
real threat to secrecy in information systems. A covert channel attack is
fairly sophisticated, but the basic concept is not beyond the capabilities of
even an average programmer. Since the subverted program can be practically any
user service, such as a printer utility, planting the compromise can be as easy
as planting a virus or any other kind of Trojan horse. And recent experience
has shown how readily viruses can be planted.
Capacity and speed are not
problems; our estimate of 1000 bits per second is unrealistically low, but even
at that rate much information leaks swiftly. With modern hardware
architectures, certain covert channels inherent in the hardware design have
capacities of millions of bits per second. And the attack does not require
significant finance. Thus, the attack could be very effective in certain
situations involving highly sensitive data.
For these reasons, security
researchers have worked diligently to develop techniques for closing covert
channels. The closure results have been bothersome; in ordinarily open
environments, there is essentially no control over the subversion of a service
program, nor is there an effective way of screening such programs for covert
channels. And other than in a few very high security systems, operating systems
cannot control the flow of information from a covert channel. The
hardware-based channels cannot be closed, given the underlying hardware
architecture.
For variety (or sobriety),
Kurak and McHugh present a very
interesting analysis of covert signaling through graphic images. In their work
they demonstrate that two different images can be combined by some rather
simple arithmetic on the bit patterns of digitized pictures. The second image
in a printed copy is undetectable to the human eye, but it can easily be
separated and reconstructed by the spy receiving the digital version of the
image. Byers explores the topic
in the context of covert data passing through pictures on the Internet.
Although covert channel demonstrations are
highly speculativereports of actual covert channel attacks just do not existthe
analysis is sound. The mere possibility of their existence calls for more
rigorous attention to other aspects of security, such as program development
analysis, system architecture analysis, and review of output.
Related Topics