Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Computer Clusters for Scalable Parallel Computing
Clustering for Massive Parallelism
CLUSTERING FOR MASSIVE PARALLELISM
A computer cluster is a collection of interconnected stand-alone
computers which can work together collectively and cooperatively as a single
integrated computing resource pool. Clustering explores massive parallelism at
the job level and achieves high
availability (HA) through stand-alone opera-tions. The benefits of computer
clusters and massively
parallel processors (MPPs) include scalable performance, HA, fault tolerance, modular
growth, and use of commodity components. These fea-tures can sustain the
generation changes experienced in hardware, software, and network components.
Cluster computing became popular in the mid-1990s as traditional mainframes and
vector supercomputers were proven to be less cost-effective in many high-performance computing (HPC) applications.
Of the
Top 500 supercomputers reported in 2010, 85 percent were computer clusters or
MPPs built with homogeneous nodes. Computer clusters have laid the foundation
for today’s supercomputers,
computational grids, and Internet clouds built over data centers. We have come
a long way toward becoming addicted to computers. According to a recent IDC
prediction, the HPC market will increase from $8.5 billion in 2010 to $10.5
billion by 2013. A majority of the Top 500 super-computers are used for HPC
applications in science and engineering. Meanwhile, the use of high-throughput computing (HTC) clusters of servers is
growing rapidly in business and web services applications.
1. Cluster Development Trends
Support for clustering of
computers has moved from interconnecting high-end mainframe computers to
building clusters with massive numbers of x86 engines. Computer clustering
started with the linking of large mainframe computers such as the IBM Sysplex
and the SGI Origin 3000. Originally, this was motivated by a demand for
cooperative group computing and to provide higher availability in critical
enterprise applications. Subsequently, the clustering trend moved toward the
networking of many minicomputers, such as DEC’s VMS cluster, in which multiple VAXes were
interconnected to share the same set of disk/tape controllers. Tandem’s Himalaya was designed as a business cluster
for fault-tolerant online
transaction processing (OLTP) applications.
In the early 1990s, the next
move was to build UNIX-based workstation clusters represented by the Berkeley
NOW (Network of Workstations) and IBM SP2 AIX-based server cluster. Beyond
2000, we see the trend moving to the clustering of RISC or x86 PC engines.
Clustered products now appear as integrated systems, software tools,
availability infrastructure, and operating system extensions. This clustering
trend matches the downsizing trend in the computer industry. Supporting
clusters of smaller nodes will increase sales by allowing modular incremental
growth in cluster con-figurations. From IBM, DEC, Sun, and SGI to Compaq and
Dell, the computer industry has lever-aged clustering of low-cost servers or
x86 desktops for their cost-effectiveness, scalability, and HA features.
1.1
Milestone Cluster Systems
Clustering has been a hot
research challenge in computer architecture. Fast communication, job
scheduling, SSI, and HA are active areas in cluster research. Table 2.1 lists
some milestone cluster research projects and commercial cluster products.
Details of these old clusters can be found in [14]. These milestone projects
have pioneered clustering hardware and middleware development over the past two
decades. Each cluster project listed has developed some unique features. Modern
clusters are headed toward HPC clusters as studied in Section 2.5.
The NOW project addresses a whole spectrum of
cluster computing issues, including architecture, software support for web
servers, single system image, I/O and file system, efficient communication, and
enhanced availability. The Rice University TreadMarks is a good example of
software-implemented shared-memory cluster of workstations. The memory sharing
is implemented with a user-space runtime library. This was a research cluster
built over Sun Solaris workstations. Some cluster OS functions were developed,
but were never marketed successfully.

A Unix
cluster of SMP servers running VMS/OS with extensions, mainly used in
high-availability applications. An AIX server cluster built with Power2 nodes
and Omega network and supported by IBM Loadleveler and MPI extensions. A
scalable and fault-tolerant cluster for OLTP and database processing built with
non-stop operating system support. The Google search engine was built at Google
using commodity components. MOSIX is a distributed operating systems for use in
Linux clusters, multi-clusters, grids, and the clouds, originally developed by
Hebrew Univer-sity in 1999.
2. Design Objectives of Computer
Clusters
Clusters have been classified
in various ways in the literature. We classify clusters using six orthogonal
attributes: scalability, packaging, control, homogeneity, programmability, and security.
2.1
Scalability
Clustering of computers is
based on the concept of modular growth. To scale a cluster from hundreds of
uniprocessor nodes to a supercluster with 10,000 multicore nodes is a
nontrivial task. The scalabil-ity could be limited by a number of factors, such
as the multicore chip technology, cluster topology, packaging method, power
consumption, and cooling scheme applied. The purpose is to achieve scal-able
performance constrained by the aforementioned factors. We have to also consider
other limiting factors such as the memory wall, disk I/O bottlenecks, and
latency tolerance, among others.
2.2
Packaging
Cluster nodes can be packaged
in a compact or a slack fashion. In a compact cluster, the nodes are closely packaged in one
or more racks sitting in a room, and the nodes are not attached to peripherals
(monitors, keyboards, mice, etc.). In a slack cluster, the nodes are attached to their usual
peripherals (i.e., they are complete SMPs, workstations, and PCs), and they may
be located in different rooms, different buildings, or even remote regions.
Packaging directly affects communication wire length, and thus the selection of
interconnection technology used. While a compact cluster can uti-lize a
high-bandwidth, low-latency communication network that is often proprietary,
nodes of a slack cluster are normally connected through standard LANs or WANs.
2.3
Control
A cluster can be either
controlled or managed in a centralized or decentralized fashion. A compact cluster normally has
centralized control, while a slack cluster can be controlled either way. In a
centralized cluster, all the nodes are owned, controlled, managed, and
administered by a central opera-tor. In a decentralized cluster, the nodes have
individual owners. For instance, consider a cluster comprising an
interconnected set of desktop workstations in a department, where each
workstation is individually owned by an employee. The owner can reconfigure,
upgrade, or even shut down the workstation at any time. This lack of a single
point of control makes system administration of such a cluster very difficult.
It also calls for special techniques for process scheduling, workload
migra-tion, checkpointing, accounting, and other similar tasks.
2.4 Homogeneity
A homogeneous cluster uses nodes from the same platform,
that is, the same processor architecture and the same operating system; often,
the nodes are from the same vendors. A heterogeneous cluster uses nodes of different platforms.
Interoperability is an important issue in heterogeneous clusters. For instance,
process migration is often needed for load balancing or availability. In a
homogeneous cluster, a binary process image can migrate to another node and
continue execution. This is not feasible in a heterogeneous cluster, as the
binary code will not be executable when the process migrates to a node of a
different platform.
2.5
Security
Intracluster communication
can be either exposed or enclosed. In an exposed cluster, the communication
paths among the nodes are exposed to the outside world. An outside machine can
access the communication paths, and thus individual nodes, using standard
protocols (e.g., TCP/IP). Such exposed clusters are easy to implement, but have
several disadvantages:
• Being exposed, intracluster
communication is not secure, unless the communication subsystem performs additional
work to ensure privacy and security.
• Outside communications may
disrupt intracluster communications in an unpredictable fashion. For instance,
heavy BBS traffic may disrupt production jobs.
• Standard communication
protocols tend to have high overhead.
In an
enclosed cluster, intracluster communication is shielded from the outside
world, which alleviates the aforementioned problems. A disadvantage is that
there is currently no standard for efficient, enclosed intracluster
communication. Consequently, most commercial or academic clusters realize fast
communications through one-of-a-kind protocols.
2.6
Dedicated versus Enterprise Clusters
A dedicated cluster is typically installed in a deskside rack in a
central computer room. It is homo-geneously configured with the same type of
computer nodes and managed by a single administrator group like a frontend
host. Dedicated clusters are used as substitutes for traditional mainframes or
supercomputers. A dedicated cluster is installed, used, and administered as a
single machine. Many users can log in to the cluster to execute both
interactive and batch jobs. The cluster offers much enhanced throughput, as
well as reduced response time.
An enterprise
cluster is mainly used to utilize idle resources in
the nodes. Each node is usually a full-fledged SMP, workstation, or PC, with
all the necessary peripherals attached. The nodes are typically geographically
distributed, and are not necessarily in the same room or even in the same building.
The nodes are individually owned by multiple owners. The cluster administrator
has only limited control over the nodes, as a node can be turned off at any
time by its owner. The owner’s “local” jobs have higher priority than enterprise
jobs. The cluster is often configured with heterogeneous computer nodes. The
nodes are often connected through a low-cost Ethernet network. Most data
centers are structured with clusters of low-cost servers. Virtual clusters play
a crucial role in upgrading data centers.
3. Fundamental
Cluster Design Issues
In this section, we will
classify various cluster and MPP families. Then we will identify the major
design issues of clustered and MPP systems. Both physical and virtual clusters
are covered. These systems are often found in computational grids, national
laboratories, business data centers, supercomputer sites, and virtualized cloud
platforms. A good understanding of how clusters and MPPs work collectively will
pave the way toward understanding the ins and outs of large-scale grids and
Internet clouds in subsequent chapters. Several issues must be considered in
developing and using a cluster. Although much work has been done in this
regard, this is still an active research and development area.
3.1
Scalable Performance
This refers to the fact that
scaling of resources (cluster nodes, memory capacity, I/O bandwidth, etc.)
leads to a proportional increase in performance. Of course, both scale-up and
scale-down cap-abilities are needed, depending on application demand or
cost-effectiveness considerations. Cluster-ing is driven by scalability. One
should not ignore this factor in all applications of cluster or MPP computing
systems.
3.2
Single-System Image (SSI)
A set of workstations
connected by an Ethernet network is not necessarily a cluster. A cluster is a
single system. For example, suppose a workstation has a 300 Mflops/second
processor, 512 MB of memory, and a 4 GB disk and can support 50 active users
and 1,000 processes. By clustering 100 such workstations, can we get a single
system that is equivalent to one huge workstation, or a megastation, that has a 30 Gflops/second processor, 50 GB
of memory, and a 400 GB disk and can support 5,000 active users and 100,000
processes? This is an appealing goal, but it is very difficult to achieve. SSI
techniques are aimed at achieving this goal.
3.3
Availability Support
Clusters can provide
cost-effective HA capability with lots of redundancy in processors, memory,
disks, I/O devices, networks, and operating system images. However, to realize
this potential, avail-ability techniques are required. We will illustrate these
techniques later in the book, when we dis-cuss how DEC clusters (Section 10.4)
and the IBM SP2 (Section 10.3) attempt to achieve HA.
3.4
Cluster Job Management
Clusters try to achieve high
system utilization from traditional workstations or PC nodes that are normally
not highly utilized. Job management software is required to provide batching,
load balancing, parallel processing, and other functionality. We will study
cluster job management systems in Section 3.4. Special software tools are
needed to manage multiple jobs simultaneously.
3.5
Internode Communication
Because of their higher node
complexity, cluster nodes cannot be packaged as compactly as MPP nodes. The
internode physical wire lengths are longer in a cluster than in an MPP. This is
true even for centralized clusters. A long wire implies greater interconnect
network latency. But more impor-tantly, longer wires have more problems in
terms of reliability, clock skew, and cross talking. These problems call for
reliable and secure communication protocols, which increase overhead. Clusters
often use commodity networks (e.g., Ethernet) with standard protocols such as
TCP/IP.
3.6 Fault Tolerance and Recovery
Clusters of machines can be
designed to eliminate all single points of failure. Through redundancy, a
cluster can tolerate faulty conditions up to a certain extent. Heartbeat
mechanisms can be installed to monitor the running condition of all nodes. In
case of a node failure, critical jobs running on the failing nodes can be saved
by failing over to the surviving node machines. Rollback recovery schemes
restore the computing results through periodic checkpointing.
3.7
Cluster Family Classification
Based on application demand,
computer clusters are divided into three classes:
• Compute clusters These are
clusters designed mainly for collective computation over a single large job. A
good example is a cluster dedicated to numerical simulation of weather
conditions. The compute clusters do not handle many I/O operations, such as
database services. When a single compute job requires frequent communication
among the cluster nodes, the cluster must share a dedicated network, and thus
the nodes are mostly homogeneous and tightly coupled. This type of clusters is
also known as a Beowulf cluster.
When the
nodes require internode communication over a small number of heavy-duty nodes,
they are essentially known as a computational grid. Tightly coupled compute
clusters are designed for supercomputing applications. Compute clusters apply
middleware such as a message-passing interface (MPI) or Parallel Virtual
Machine (PVM) to port programs to a wide variety of clusters.
• High-Availability clusters HA
(high-availability) clusters are designed to be fault-tolerant and achieve HA
of services. HA clusters operate with many redundant nodes to sustain faults or
failures. The simplest HA cluster has only two nodes that can fail over to each
other. Of course, high redundancy provides higher availability. HA clusters
should be designed to avoid all single points of failure. Many commercial HA
clusters are available for various operating systems.
• Load-balancing clusters These
clusters shoot for higher resource utilization through load balancing among all
participating nodes in the cluster. All nodes share the workload or function as
a single virtual
machine (VM). Requests initiated from the user are distributed to all node
computers to form a cluster. This results in a balanced workload among
different machines, and thus higher resource utilization or higher performance.
Middleware is needed to achieve dynamic load balancing by job or process
migration among all the cluster nodes.
4. Analysis of the Top 500
Supercomputers
Every six months, the world’s Top 500 supercomputers are evaluated by
running the Linpack Benchmark program over very large data sets. The ranking
varies from year to year, similar to a competition. In this section, we will
analyze the historical share in architecture, speed, operating systems,
countries, and applications over time. In addition, we will compare the top
five fastest systems in 2010.
4.1
Architectural Evolution
It is interesting to observe in Figure 2.1 the
architectural evolution of the Top 500 supercomputers over the years. In 1993,
250 systems assumed the SMP architecture and these SMP systems all disappeared
in June of 2002. Most SMPs are built with shared memory and shared I/O devices.
There were 120 MPP systems built in 1993, MPPs reached the peak mof 350 systems
in mod-200, and dropped to less than 100 systems in 2010. The single
instruction, multiple data (SIMD) machines dis-appeared in 1997. The cluster
architecture appeared in a few systems in 1999. The cluster systems are now
populated in the Top-500 list with more than 400 systems as the dominating
architecture class.
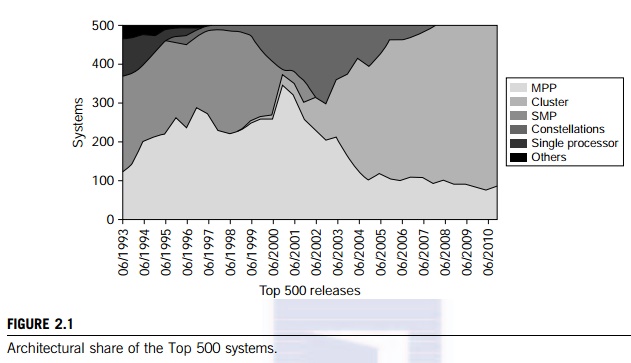
In 2010,
the Top 500 architecture is dominated by clusters (420 systems) and MPPs (80
systems). The basic distinction between these two classes lies in the
components they use to build the systems. Clusters are often built with
commodity hardware, software, and network components that are commercially available.
MPPs are built with custom-designed compute nodes, boards, modules, and
cabi-nets that are interconnected by special packaging. MPPs demand high
bandwidth, low latency, better power efficiency, and high reliability.
Cost-wise, clusters are affordable by allowing modular growth with scaling
capability. The fact that MPPs appear in a much smaller quantity is due to
their high cost. Typically, only a few MPP-based supercomputers are installed
in each country.
4.2
Speed Improvement over Time
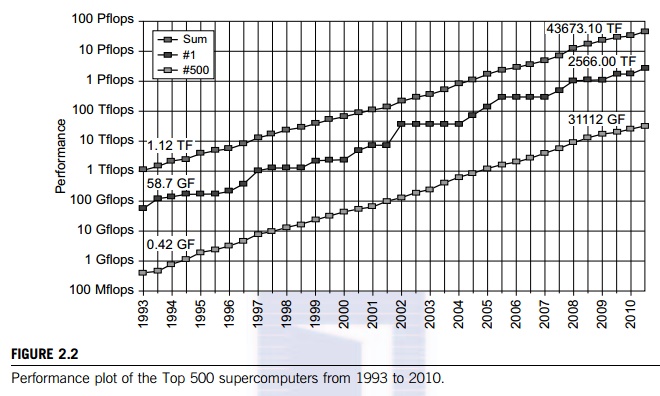
Figure 2.2 plots the measured
performance of the Top 500 fastest computers from 1993 to 2010. The y-axis is
scaled by the sustained speed performance in terms of Gflops, Tflops, and
Pflops. The middle curve plots the performance of the fastest computers recorded
over 17 years; peak per-formance increases from 58.7 Gflops to 2.566 Pflops.
The bottom curve corresponds to the speed of the 500th computer, which
increased from 0.42 Gflops in 1993 to 31.1 Tflops in 2010. The top curve plots
the speed sum of all 500 computers over the same period. In 2010, the total
speed sum of 43.7 Pflops was achieved by all 500 computers, collectively. It is
interesting to observe that the total speed sum increases almost linearly with
time.
4.3
Operating System Trends in the Top 500
The five most popular operating systems have
more than a 10 percent share among the Top 500 computers, according to data
released by TOP500.org (www.top500.org/stats/list/36/os) in November 2010.
According to the data, 410 supercomputers are using Linux with a total
processor count exceeding 4.5 million. This constitutes 82 percent of the
systems adopting Linux. The IBM AIX/ OS is in second place with 17 systems (a
3.4 percent share) and more than 94,288 processors.
Third place is represented by
the combined use of the SLEs10 with the SGI ProPack5, with 15 sys-tems (3
percent) over 135,200 processors. Fourth place goes to the CNK/SLES9 used by 14
systems (2.8 percent) over 1.13 million processors. Finally, the CNL/OS was
used in 10 systems (2 percent) over 178,577 processors. The remaining 34
systems applied 13 other operating systems with a total share of only 6.8
percent. In conclusion, the Linux OS dominates the systems in the Top 500 list.
4.4
The Top Five Systems in 2010
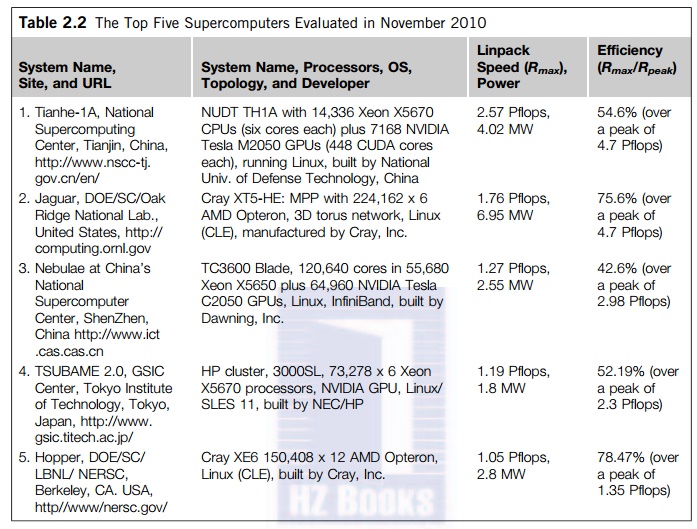
In Table 2.2, we summarize
the key architecture features and sustained Linpack Benchmark performance of
the top five supercomputers reported in November 2010. The Tianhe-1A was ranked
as the fastest MPP in late 2010. This system was built with 86,386 Intel Xeon
CPUs and NVIDIA GPUs by the National University of Defense Technology in China.
We will present in Section 2.5 some of the top winners: namely the Tianhe-1A,
Cray Jaguar, Nebulae, and IBM Roadrunner that were ranked among the top systems
from 2008 to 2010. All the top five machines in Table 2.3 have achieved a speed
higher than 1 Pflops. The sustained
speed, Rmax, in Pflops is measured from
the execution of the Linpack Benchmark program corresponding to a maximum
matrix size.
The system efficiency reflects the ratio of the sustained
speed to the peak speed, Rpeak, when all computing elements are fully
utilized in the system. Among the top five systems, the two U.S.-built systems, the Jaguar and the
Hopper, have the highest efficiency, more than 75 percent. The two sys-tems
built in China, the Tianhe-1A and the Nebulae, and Japan’s TSUBAME 2.0, are all low in efficiency. In
other words, these systems should still have room for improvement in the
future. The average power consumption in these 5 systems is 3.22 MW. This
implies that excessive power con-sumption may post the limit to build even
faster supercomputers in the future. These top systems all emphasize massive
parallelism using up to 250,000 processor cores per system.

4.5
Country Share and Application Share
In the 2010 Top-500 list, there were 274
supercomputing systems installed in the US, 41 systems in China, and 103
systems in Japan, France, UK, and Germany. The remaining countries have 82
systems. This country share roughly reflects the countries’ economic growth over the years. Countries
compete in the Top 500 race every six months. Major increases of supercomputer
applications are in the areas of database, research, finance, and information
services.
4.6
Power versus Performance in the Top Five in 2010
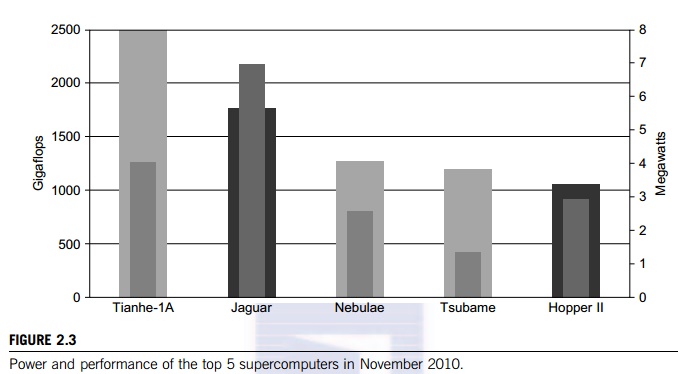
In Figure 2.3, the top five supercomputers are
ranked by their speed (Gflops) on the left side and by their power consumption
(MW per system) on the right side. The Tiahhe-1A scored the highest with a 2.57
Pflops speed and 4.01 MW power consumption. In second place, the Jaguar
consumes the highest power of 6.9 MW. In fourth place, the TSUBAME system
consumes the least power, 1.5 MW, and has a speed performance that almost
matches that of the Nebulae sys-tem. One can define a performance/power ratio
to see the trade-off between these two metrics. There is also a Top 500 Green
contest that ranks the supercomputers by their power efficiency. This chart
shows that all systems using the hybrid CPU/GPU architecture consume much less
power.
Related Topics