Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Computer Clusters for Scalable Parallel Computing
Cluster Job and Resource Management
CLUSTER JOB AND RESOURCE MANAGEMENT
This section covers various
scheduling methods for executing multiple jobs on a clustered system. The LSF
is described as middleware for cluster computing. MOSIX is introduced as a
distributed OS for managing resources in large-scale clusters or in clouds.
1. Cluster Job Scheduling Methods
Cluster jobs may be scheduled
to run at a specific time (calendar
scheduling) or when a particular event happens (event scheduling). Table 2.6 summarizes various schemes to
resolve job scheduling issues on a cluster. Jobs are scheduled according to
priorities based on submission time, resource nodes, execution time, memory,
disk, job type, and user identity. With static priority, jobs are assigned priorities according to a
predetermined, fixed scheme. A simple scheme is to schedule jobs in a
first-come, first-serve fashion. Another scheme is to assign different
priorities to users. With dynamic
priority, the priority of a job may change over time.
Three schemes are used to share cluster nodes. In the dedicated mode, only one job runs in the clus-ter at a time, and at most, one
process of the job is assigned to a node at a time. The single job runs until
completion before it releases the cluster to run other jobs. Note that even in
the dedicated mode, some nodes may be reserved for system use and not be open
to the user job. Other than that, all cluster resources are devoted to run a
single job. This may lead to poor system utilization. The job resource
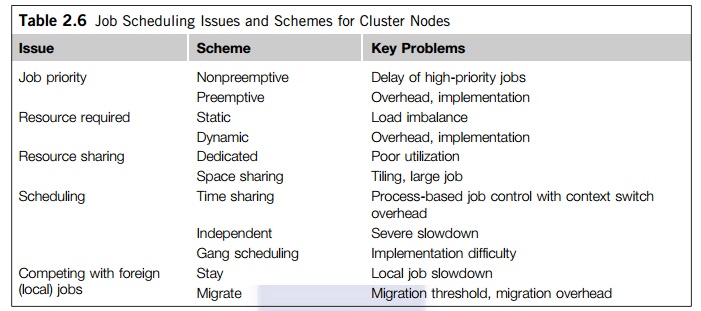
requirement can be static or dynamic. Static scheme fixes the number of nodes for a
single job for its entire period. Static scheme may underutilize the cluster
resource. It cannot handle the situation when the needed nodes become
unavailable, such as when the workstation owner shuts down the machine.
Dynamic resource allows a job to acquire or
release nodes during execution. However, it is much more difficult to
implement, requiring cooperation between a running job and the Java Mes-sage
Service (JMS). The jobs make asynchronous requests to the JMS to add/delete resources.
The JMS needs to notify the job when resources become available. The synchrony
means that a job should not be delayed (blocked) by the request/notification.
Cooperation between jobs and the JMS requires modification of the programming
languages/libraries. A primitive mechanism for such cooperation exists in PVM
and MPI.
1.1
Space Sharing
A common scheme is to assign higher priorities
to short, interactive jobs in daytime and during evening hours using tiling. In this space-sharing mode, multiple jobs can run on disjointed
partitions (groups) of nodes simultaneously. At most, one process is assigned
to a node at a time. Although a partition of nodes is dedicated to a job, the
interconnect and the I/O subsystem may be shared by all jobs. Space sharing
must solve the tiling problem and the large-job problem.
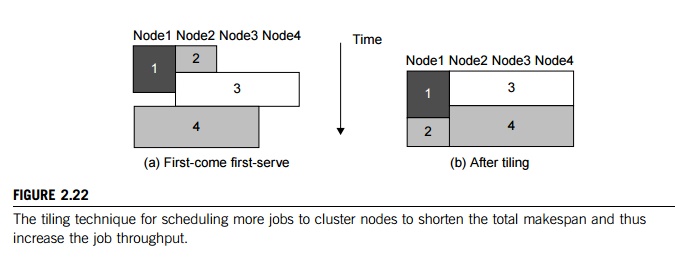
Example 2.12 Job Scheduling by Tiling over
Cluster Nodes
Figure 2.22 illustrates the tiling technique.
In Part (a), the JMS schedules four jobs in a first-come first-serve fashion on
four nodes. Jobs 1 and 2 are small and thus assigned to nodes 1 and 2. Jobs 3
and 4 are parallel; each needs three nodes. When job 3 comes, it cannot run
immediately. It must wait until job 2 finishes to free up the needed nodes.
Tiling will increase the utilization of the nodes as shown in Figure 2.22(b).
The overall execution time of the four jobs is reduced after repacking the jobs
over the available nodes. This pro-blem cannot be solved in dedicated or
space-sharing modes. However, it can be alleviated by timesharing.
1.2
Time Sharing
In the dedicated or space-sharing model, only
one user process is allocated to a node. However, the sys-tem processes or
daemons are still running on the same node. In the time-sharing mode, multiple user pro-cesses are assigned to the same node. Time
sharing introduces the following parallel scheduling policies:
1. Independent scheduling The
most straightforward implementation of time sharing is to use the operating
system of each cluster node to schedule different processes as in a traditional
workstation. This is called local
scheduling or independent
scheduling. However, the performance of parallel jobs could be significantly
degraded. Processes of a parallel job need to interact. For instance, when one process
wants to barrier-synchronize with another, the latter may be scheduled out. So
the first process has to wait. As the second process is rescheduled, the first
process may be swapped out.
2. Gang scheduling The gang scheduling scheme schedules all processes of a parallel
job together. When one process is active, all processes are active. The cluster
nodes are not perfectly clock-synchronized. In fact, most clusters are
asynchronous systems, and are not driven by the same clock. Although we say, “All processes are scheduled to run at the same
time,” they do not start exactly at
the same time. Gang-scheduling
skew is the
maximum difference between the time the first process starts and the time the
last process starts. The execution time of a parallel job increases as the
gang-scheduling skew becomes larger, leading to longer execution time. We
should use a homogeneous cluster, where gang scheduling is more effective.
However, gang scheduling is not yet realized in most clusters, because of
implementation difficulties.
3. Competition with foreign
(local) jobs Scheduling becomes more complicated when both cluster jobs and
local jobs are running. Local jobs should have priority over cluster jobs. With
one keystroke, the owner wants command of all workstation resources. There are
basically two ways to deal with this situation: The cluster job can either stay
in the workstation node or migrate to another idle node. A stay scheme has the advantage of avoiding migration cost.
The cluster process can be run at the lowest priority. The workstation’s cycles can be divided into three portions,
for kernel processes, local processes, and cluster processes. However, to stay
slows down both the local and the cluster jobs, especially when the cluster job
is a load-balanced parallel job that needs frequent synchronization and
communication. This leads to the migration approach to flow the jobs around
available nodes, mainly for balancing the workload.
2. Cluster Job Management Systems
Job management is also known
as workload management, load sharing, or load management. We will first discuss the basic issues facing
a job management system and summarize the available soft-ware packages. A Job Management System (JMS) should have three parts:
• A user server lets the user submit jobs to one or more
queues, specify resource requirements for each job, delete a job from a queue,
and inquire about the status of a job or a queue.
• A job scheduler performs job scheduling and queuing according
to job types, resource requirements, resource availability, and scheduling
policies.
• A resource manager allocates and monitors resources, enforces
scheduling policies, and collects accounting information.
2.1
JMS Administration
The functionality of a JMS is
often distributed. For instance, a user server may reside in each host node,
and the resource manager may span all cluster nodes. However, the
administration of a JMS should be centralized. All configuration and log files should be
maintained in one location. There should be a single user interface to use the
JMS. It is undesirable to force the user to run PVM jobs through one software
package, MPI jobs through another, and HPF jobs through yet another.
The JMS should be able to dynamically
reconfigure the cluster with minimal impact on the running jobs. The
administrator’s prologue and epilogue scripts should be able to run before and
after each job for security checking, accounting, and cleanup. Users should be
able to cleanly kill their own jobs. The administrator or the JMS should be able
to cleanly suspend or kill any job. Clean means that when a job is suspended or killed,
all its processes must be included. Otherwise, some “orphan” processes are left in the system, which wastes
cluster resources and may eventually render the system unusable.
2.2
Cluster Job Types
Several types of jobs execute
on a cluster. Serial
jobs run on
a single node. Parallel
jobs use
multi-ple nodes. Interactive
jobs are
those that require fast turnaround time, and their input/output is directed to
a terminal. These jobs do not need large resources, and users expect them to
execute immediately, not to wait in a queue. Batch jobs normally need more resources, such as large
mem-ory space and long CPU time. But they do not need immediate responses. They
are submitted to a job queue to be scheduled to run when the resource becomes
available (e.g., during off hours).
While
both interactive and batch jobs are managed by the JMS, foreign jobs are created outside the JMS. For instance,
when a network of workstations is used as a cluster, users can submit
inter-active or batch jobs to the JMS. Meanwhile, the owner of a workstation
can start a foreign job at any time, which is not submitted through the JMS.
Such a job is also called a local
job, as
opposed to cluster
jobs
(interactive or batch, parallel or serial) that are submitted through the JMS
of the cluster. The characteristic of a local job is fast response time. The
owner wants all resources to exe-cute his job, as though the cluster jobs did
not exist.
2.3 Characteristics of a Cluster Workload
To realistically address job
management issues, we must understand the workload behavior of clusters. It may
seem ideal to characterize workload based on long-time operation data on real
clusters. The parallel workload traces include both development and production
jobs. These traces are then fed to a simulator to generate various statistical
and performance results, based on different sequen-tial and parallel workload
combinations, resource allocations, and scheduling policies. The following
workload characteristics are based on a NAS benchmark experiment. Of course,
different workloads may have variable statistics.
• Roughly half of parallel jobs
are submitted during regular working hours. Almost 80 percent of parallel jobs
run for three minutes or less. Parallel jobs running longer than 90 minutes
account for 50 percent of the total time.
• The sequential workload shows
that 60 percent to 70 percent of workstations are available to execute parallel
jobs at any time, even during peak daytime hours.
• On a workstation, 53 percent
of all idle periods are three minutes or less, but 95 percent of idle time is
spent in periods of time that are 10 minutes or longer.
• A 2:1 rule applies, which
says that a network of 64 workstations, with proper JMS software, can sustain a
32-node parallel workload in addition to the original sequential workload. In
other words, clustering gives a supercomputer half of the cluster size for
free!
2.4
Migration Schemes
A migration scheme must consider the following three issues:
• Node availability This refers
to node availability for job migration. The Berkeley NOW project has reported
such opportunity does exist in university campus environment. Even during peak
hours, 60 percent of workstations in a cluster are available at Berkeley
campus.
• Migration overhead What is
the effect of the migration overhead? The migration time can significantly slow
down a parallel job. It is important to reduce the migration overhead (e.g., by
improving the communication subsystem) or to migrate only rarely. The slowdown
is significantly reduced if a parallel job is run on a cluster of twice the
size. For instance, for a 32-node parallel job run on a 60-node cluster, the
slowdown caused by migration is no more than 20 percent, even when the
migration time is as long as three minutes. This is because more nodes are
available, and thus the migration demand is less frequent.
• Recruitment threshold What
should be the recruitment threshold? In the worst scenario, right after a
process migrates to a node, the node is immediately claimed by its owner. Thus,
the process has to migrate again, and the cycle continues. The recruitment
threshold is the amount of time a workstation stays unused before the cluster
considers it an idle node.
2.5
Desired Features in A JMS
Here are some features that
have been built in some commercial JMSes in cluster computing applications:
• Most support heterogeneous
Linux clusters. All support parallel and batch jobs. However, Connect:Queue
does not support interactive jobs.
• Enterprise cluster jobs are
managed by the JMS. They will impact the owner of a workstation in running
local jobs. However, NQE and PBS allow the impact to be adjusted. In DQS, the
impact can be configured to be minimal.
• All packages offer some kind
of load-balancing mechanism to efficiently utilize cluster resources. Some
packages support checkpointing.
• Most packages cannot support
dynamic process migration. They support static migration: A process can be
dispatched to execute on a remote node when the process is first created.
However,
once it starts execution, it stays in that node. A package that does support
dynamic process migration is Condor.
• All packages allow dynamic
suspension and resumption of a user job by the user or by the administrator.
All packages allow resources (e.g., nodes) to be dynamically added to or
deleted.
• Most packages provide both a
command-line interface and a graphical user interface. Besides UNIX security
mechanisms, most packages use the Kerberos authentication system.
3. Load Sharing Facility (LSF) for
Cluster Computing
LSF is a commercial workload
management system from Platform Computing [29]. LSF emphasizes job management
and load sharing on both parallel and sequential jobs. In addition, it supports
checkpointing, availability, load migration, and SSI. LSF is highly scalable
and can support a clus-ter of thousands of nodes. LSF has been implemented for
various UNIX and Windows/NT plat-forms. Currently, LSF is being used not only
in clusters but also in grids and clouds.
3.1
LSF Architecture
LSF supports most UNIX
platforms and uses the standard IP for JMS communication. Because of this, it
can convert a heterogeneous network of UNIX computers into a cluster. There is
no need to change the underlying OS kernel. The end user utilizes the LSF functionalities
through a set of utility commands. PVM and MPI are supported. Both a
command-line interface and a GUI are pro-vided. LSF also offers skilled users
an API that is a runtime library called LSLIB (load sharing library). Using LSLIB explicitly requires the user to
modify the application code, whereas using the utility commands does not. Two LSF daemons are
used on each server in the cluster. The load information managers (LIMs) periodically exchange load
information. The remote
execution server (RES) executes remote tasks.
3.2
LSF Utility Commands
A cluster node may be a
single-processor host or an SMP node with multiple processors, but always runs
with only a single copy of the operating system on the node. Here are
interesting features built into the LSF facilities:
• LSF supports all four
combinations of interactive, batch, sequential, and parallel jobs. A job that
is not executed through LSF is called a foreign job. A server node is one which can execute LSF jobs. A client node is one that can initiate or submit LSF jobs
but cannot execute them. Only the resources on the server nodes can be shared.
Server nodes can also initiate or submit LSF jobs.
• LSF offers a set of tools (lstools) to get information from LSF and to run jobs
remotely. For instance, lshosts lists the static resources
(discussed shortly) of every server node in the cluster. The command lsrun executes a program on a remote node.
• When a user types the command
line %lsrun-R ‘swp>100’ myjob at a client node, the application myjob will be automatically executed on the most
lightly loaded server node that has an available swap space greater than 100
MB.
• The lsbatch utility allows users to submit, monitor, and
execute batch jobs through LSF. This utility is a load-sharing version of the
popular UNIX command interpreter tcsh. Once a user enters the lstcsh shell, every command issued will be
automatically executed on a suitable node. This is done transparently: The user
sees a shell exactly like a tcsh running on the local node.
• The lsmake utility is a parallel version of the UNIX make
utility, allowing a makefile to be processed in multiple nodes simultaneously.
Example 2.13 Application of the LSF on a Cluster
of Computers
Suppose
a cluster consists of eight expensive server nodes and 100 inexpensive client
nodes (workstations or PCs). The server nodes are expensive due to better
hardware and software, including application soft-ware. A license is available
to install a FORTRAN compiler and a CAD simulation package, both valid for up
to four users. Using a JMS such as LSF, all the hardware and software resources
of the server nodes are made available to the clients transparently.
A user sitting in front of a client’s terminal
feels as though the client node has all the software and speed of the servers
locally. By typing lsmake my.makefile, the user can compile his source code on
up to four servers. LSF selects the nodes with the least amount of load. Using LSF
also benefits resource utiliza-tion. For instance, a user wanting to run a CAD
simulation can submit a batch job. LSF will schedule the job as soon as the
software becomes available.
4. MOSIX: An OS for Linux Clusters and
Clouds
MOSIX is a distributed
operating system that was developed at Hebrew University in 1977. Initi-ally,
the system extended BSD/OS system calls for resource sharing in Pentium
clusters. In 1999, the system was redesigned to run on Linux clusters built
with x86 platforms. The MOSIX project is still active as of 2011, with 10
versions released over the years. The latest version, MOSIX2, is compatible
with Linux 2.6.
4.1
MOXIS2 for Linux Clusters
MOSIX2 runs as a
virtualization layer in the Linux environment. This layer provides SSI to users
and applications along with runtime Linux support. The system runs applications
in remote nodes as though they were run locally. It supports both sequential
and parallel applications, and can dis-cover resources and migrate software
processes transparently and automatically among Linux nodes. MOSIX2 can also
manage a Linux cluster or a grid of multiple clusters.
Flexible
management of a grid allows owners of clusters to share their computational
resources among multiple cluster owners. Each cluster can still preserve its
autonomy over its own clusters and its ability to disconnect its nodes from the
grid at any time. This can be done without disrupt-ing the running programs. A
MOSIX-enabled grid can extend indefinitely as long as trust exists among the
cluster owners. The condition is to guarantee that guest applications cannot be
modified while running in remote clusters. Hostile computers are not allowed to
connect to the local network.
4.2 SSI Features in MOSIX2
The system can run in native mode or as a VM. In native mode, the performance is
better, but it requires that you modify the base Linux kernel, whereas a VM can
run on top of any unmodified OS that supports virtualization, including
Microsoft Windows, Linux, and Mac OS X. The system is most suitable for running
compute-intensive applications with low to moderate amounts of I/O. Tests of
MOSIX2 show that the performance of several such applications over a 1
GB/second campus grid is nearly identical to that of a single cluster. Here are
some interesting features of MOSIX2:
• Users can log in on any node
and do not need to know where their programs run.
• There is no need to modify or
link applications with special libraries.
• There is no need to copy
files to remote nodes, thanks to automatic resource discovery and workload
distribution by process migration.
• Users can load-balance and
migrate processes from slower to faster nodes and from nodes that run out of
free memory.
• Sockets are migratable for
direct communication among migrated processes.
• The system features a secure
runtime environment (sandbox) for guest processes.
• The system can run batch jobs
with checkpoint recovery along with tools for automatic installation and
configuration scripts.
4.3
Applications of MOSIX for HPC
The MOSIX is a research OS
for HPC cluster, grid, and cloud computing. The system’s designers claim that MOSIX offers efficient
utilization of wide-area grid resources through automatic resource discovery
and load balancing. The system can run applications with unpredictable resource
requirements or runtimes by running long processes, which are automatically
sent to grid nodes. The sys-tem can also combine nodes of different capacities
by migrating processes among nodes based on their load index and available
memory.
MOSIX became proprietary software in 2001.
Application examples include scientific computations for genomic sequence
analysis, molecular dynamics, quantum dynamics, nanotechnology and other
parallel HPC applications; engineering applications including CFD, weather
forecasting, crash simulations, oil industry simulations, ASIC design, and
pharmaceutical design; and cloud applictions such as for financial modeling,
rendering farms, and compilation farms.
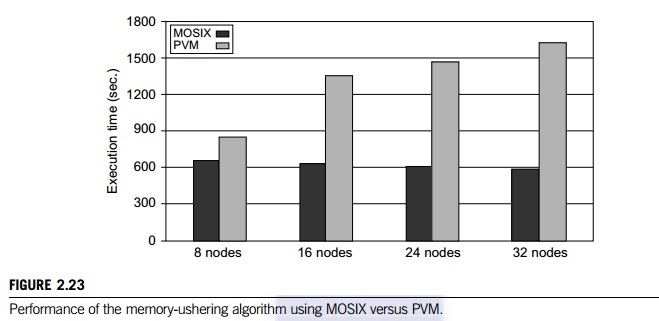
Example 2.14 Memory-Ushering Algorithm Using
MOSIX versus PVM
Memory
ushering is practiced to borrow the main memory of a remote cluster node, when
the main mem-ory on a local node is exhausted. The remote memory access is done
by process migration instead of paging or swapping to local disks. The ushering
process can be implemented with PVM commands or it can use MOSIX process
migration. In each execution, an average memory chunk can be assigned to the
nodes using PVM. Figure 2.23 shows the execution time of the memory algorithm using
PVM compared with the use of the MOSIX routine.
For a small cluster of eight nodes, the
execution times are closer. When the cluster scales to 32 nodes, the MOSIX
routine shows a 60 percent reduction in ushering time. Furthermore, MOSIX
performs almost the same when the cluster size increases. The PVM ushering time
increases monotonically by an average of 3.8 percent per node increase, while
MOSIX consistently decreases by 0.4 percent per node increase. The reduction in
time results from the fact that the memory and load-balancing algorithms of
MOSIX are more scalable than PVM.
Related Topics