Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Computer Clusters for Scalable Parallel Computing
Checkpointing and Recovery Techniques
Checkpointing and Recovery Techniques
Checkpointing and recovery are two techniques that must be developed hand in hand to enhance the availability of a cluster system. We will start with the basic concept of checkpointing. This is the process of periodically saving the state of an executing program to stable storage, from which the system can recover after a failure. Each program state saved is called a checkpoint. The disk file that contains the saved state is called the checkpoint file. Although all current checkpointing software saves program states in a disk, research is underway to use node memories in place of stable storage in order to improve performance.
Checkpointing techniques are useful not only for availability, but also for program debugging, process migration, and load balancing. Many job management systems and some operating systems support checkpointing to a certain degree. The Web Resource contains pointers to numerous check-point-related web sites, including some public domain software such as Condor and Libckpt. Here we will present the important issues for the designer and the user of checkpoint software. We will first consider the issues that are common to both sequential and parallel programs, and then we will discuss the issues pertaining to parallel programs.
1. Kernel, Library, and Application Levels
Checkpointing can be realized by the operating system at the kernel level, where the OS transpar-ently checkpoints and restarts processes. This is ideal for users. However, checkpointing is not sup-ported in most operating systems, especially for parallel programs. A less transparent approach links the user code with a checkpointing library in the user space. Checkpointing and restarting are handled by this runtime support. This approach is used widely because it has the advantage that user applications do not have to be modified.
A main problem is that most current checkpointing libraries are static, meaning the application source code (or at least the object code) must be available. It does not work if the application is in the form of executable code. A third approach requires the user (or the compiler) to insert check-pointing functions in the application; thus, the application has to be modified, and the transparency is lost. However, it has the advantage that the user can specify where to checkpoint. This is helpful to reduce checkpointing overhead. Checkpointing incurs both time and storage overheads.
2. Checkpoint Overheads
During a program’s execution, its states may be saved many times. This is denoted by the time consumed to save one checkpoint. The storage overhead is the extra memory and disk space required for checkpointing. Both time and storage overheads depend on the size of the checkpoint file. The overheads can be substantial, especially for applications that require a large memory space. A number of techniques have been suggested to reduce these overheads.
3. Choosing an Optimal Checkpoint Interval
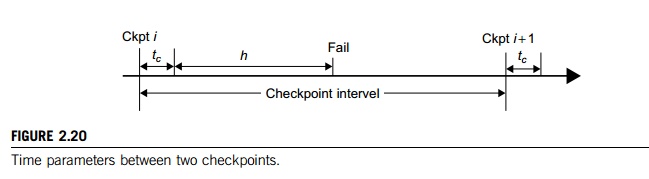
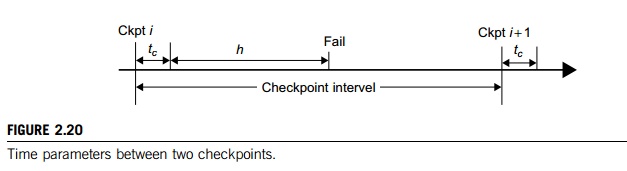
The time period between two checkpoints is called the checkpoint interval. Making the interval larger can reduce checkpoint time overhead. However, this implies a longer computation time after a failure. Wong and Franklin [28] derived an expression for optimal checkpoint interval as illu-strated in Figure 2.20.

Here, MTTF is the system’s mean time to failure. This MTTF accounts the time consumed to save one checkpoint, and h is the average percentage of normal computation performed in a check-point interval before the system fails. The parameter h is always in the range. After a system is restored, it needs to spend h × (checkpoint interval) time to recompute.
4. Incremental Checkpoint
Instead of saving the full state at each checkpoint, an incremental checkpoint scheme saves only the portion of the state that is changed from the previous checkpoint. However, care must be taken regarding old checkpoint files. In full-state checkpointing, only one checkpoint file needs to be kept on disk. Subsequent checkpoints simply overwrite this file. With incremental checkpointing, old files needed to be kept, because a state may span many files. Thus, the total storage requirement is larger.
5. Forked Checkpointing
Most checkpoint schemes are blocking in that the normal computation is stopped while checkpoint-ing is in progress. With enough memory, checkpoint overhead can be reduced by making a copy of the program state in memory and invoking another asynchronous thread to perform the checkpointing concurrently. A simple way to overlap checkpointing with computation is to use the UNIX fork( ) system call. The forked child process duplicates the parent process’s address space and checkpoints it. Meanwhile, the parent process continues execution. Overlapping is achieved since checkpointing is disk-I/O intensive. A further optimization is to use the copy-on-write mechanism.
6. User-Directed Checkpointing
The checkpoint overheads can sometimes be substantially reduced if the user inserts code (e.g., library or system calls) to tell the system when to save, what to save, and what not to save. What should be the exact contents of a checkpoint? It should contain just enough information to allow a system to recover. The state of a process includes its data state and control state. For a UNIX process, these states are stored in its address space, including the text (code), the data, the stack segments, and the process descriptor. Saving and restoring the full state is expensive and sometimes impossible.
For instance, the process ID and the parent process ID are not restorable, nor do they need to be saved in many applications. Most checkpointing systems save a partial state. For instance, the code segment is usually not saved, as it does not change in most applications. What kinds of applications can be checkpointed? Current checkpoint schemes require programs to be well behaved, the exact meaning of which differs in different schemes. At a minimum, a well-behaved program should not need the exact contents of state information that is not restorable, such as the numeric value of a process ID.
7. Checkpointing Parallel Programs
We now turn to checkpointing parallel programs. The state of a parallel program is usually much larger than that of a sequential program, as it consists of the set of the states of individual processes, plus the state of the communication network. Parallelism also introduces various timing and consistency problems.
Example 2.11 Checkpointing a Parallel Program
Figure 2.21 illustrates checkpointing of a three-process parallel program. The arrows labeled x, y, and z represent point-to-point communication among the processes. The three thick lines labeled a, b, and c represent three global snapshots (or simply snapshots), where a global snapshot is a set of checkpoints
(represented by dots), one from every process. In addition, some communication states may need to be saved. The intersection of a snapshot line with a process’s time line indicates where the process should take a (local) checkpoint. Thus, the program’s snapshot c consists of three local checkpoints: s, t, u for processes P, Q, and R, respectively, plus saving the communication y.
8. Consistent Snapshot
A global snapshot is called consistent if there is no message that is received by the checkpoint of one process, but not yet sent by another process. Graphically, this corresponds to the case that no arrow crosses a snapshot line from right to left. Thus, snapshot a is consistent, because arrow x is from left to right. But snapshot c is inconsistent, as y goes from right to left. To be consistent, there should not be any zigzag path between two checkpoints [20]. For instance, checkpoints u and s can-not belong to a consistent global snapshot. A stronger consistency requires that no arrows cross the snapshot. Thus, only snapshot b is consistent in Figure 2.23.
9. Coordinated versus Independent Checkpointing
Checkpointing schemes for parallel programs can be classified into two types. In coordinated check-pointing (also called consistent checkpointing), the parallel program is frozen, and all processes are checkpointed at the same time. In independent checkpointing, the processes are checkpointed inde-pendent of one another. These two types can be combined in various ways. Coordinated check-pointing is difficult to implement and tends to incur a large overhead. Independent checkpointing has a small overhead and can utilize existing checkpointing schemes for sequential programs.
Related Topics