Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Computer Clusters for Scalable Parallel Computing
High Availability through Redundancy
High Availability through Redundancy
When designing robust, highly available systems three terms are often used together: reliability, availability, and serviceability (RAS). Availability is the most interesting measure since it combines the concepts of reliability and serviceability as defined here:
• Reliability measures how long a system can operate without a breakdown.
• Availability indicates the percentage of time that a system is available to the user, that is, the percentage of system uptime.
• Serviceability refers to how easy it is to service the system, including hardware and software maintenance, repair, upgrades, and so on.
The demand for RAS is driven by practical market needs. A recent Find/SVP survey found the following figures among Fortune 1000 companies: An average computer is down nine times per year with an average downtime of four hours. The average loss of revenue per hour of downtime is $82,500. With such a hefty penalty for downtime, many companies are striving for systems that offer 24/365 availability, meaning the system is available 24 hours per day, 365 days per year.
1. Availability and Failure Rate
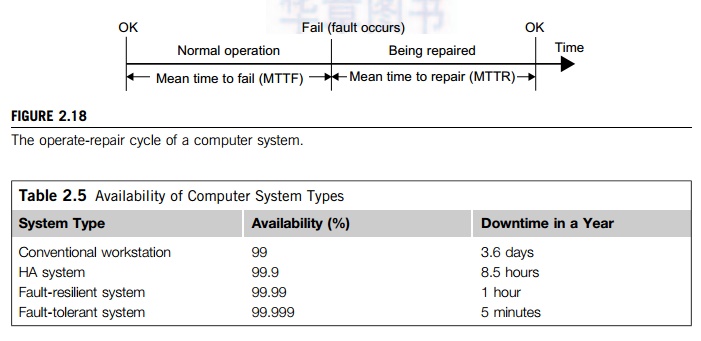
As Figure 2.18 shows, a computer system operates normally for a period of time before it fails. The failed system is then repaired, and the system returns to normal operation. This operate-repair cycle then repeats. A system’s reliability is measured by the mean time to failure (MTTF), which is the average time of normal operation before the system (or a component of the system) fails. The metric for serviceability is the mean time to repair (MTTR), which is the average time it takes to repair the system and restore it to working condition after it fails. The availability of a system is defined by:
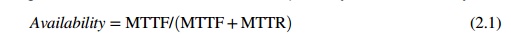
2. Planned versus Unplanned Failure
When studying RAS, we call any event that prevents the system from normal operation a failure. This includes:
• Unplanned failures The system breaks, due to an operating system crash, a hardware failure, a network disconnection, human operation errors, a power outage, and so on. All these are simply called failures. The system must be repaired to correct the failure.
• Planned shutdowns The system is not broken, but is periodically taken off normal operation for upgrades, reconfiguration, and maintenance. A system may also be shut down for weekends or holidays. The MTTR in Figure 2.18 for this type of failure is the planned downtime.
Table 2.5 shows the availability values of several representative systems. For instance, a conven-tional workstation has an availability of 99 percent, meaning it is up and running 99 percent of the time or it has a downtime of 3.6 days per year. An optimistic definition of availability does not consider planned downtime, which may be significant. For instance, many supercomputer installations have a planned downtime of several hours per week, while a telephone system cannot tolerate a downtime of a few minutes per year.
3. Transient versus Permanent Failures
A lot of failures are transient in that they occur temporarily and then disappear. They can be dealt with without replacing any components. A standard approach is to roll back the system to a known
state and start over. For instance, we all have rebooted our PC to take care of transient failures such as a frozen keyboard or window. Permanent failures cannot be corrected by rebooting. Some hard-ware or software component must be repaired or replaced. For instance, rebooting will not work if the system hard disk is broken.
4. Partial versus Total Failures
A failure that renders the entire system unusable is called a total failure. A failure that only affects part of the system is called a partial failure if the system is still usable, even at a reduced capacity. A key approach to enhancing availability is to make as many failures as possible partial failures, by systematically removing single points of failure, which are hardware or software components whose failure will bring down the entire system.
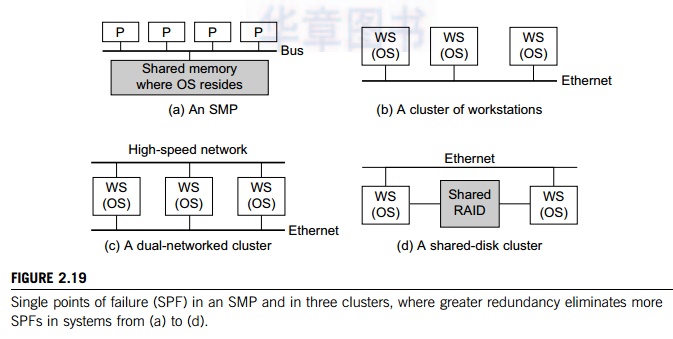
Example 2.7 Single Points of Failure in an SMP and in Clusters of Computers
In an SMP (Figure 2.19(a)), the shared memory, the OS image, and the memory bus are all single points of failure. On the other hand, the processors are not forming a single point of failure. In a cluster of work-stations (Figure 2.19(b)), interconnected by Ethernet, there are multiple OS images, each residing in a workstation. This avoids the single point of failure caused by the OS as in the SMP case. However, the Ethernet network now becomes a single point of failure, which is eliminated in Figure 2.17(c), where a high-speed network is added to provide two paths for communication.
When a node fails in the clusters in Figure 2.19(b) and Figure 2.19(c), not only will the node applications all fail, but also all node data cannot be used until the node is repaired. The shared disk cluster in Figure 2.19(d) provides a remedy. The system stores persistent data on the shared disk, and periodically checkpoints to save intermediate results. When one WS node fails, the data will not be lost in this shared-disk cluster.
5. Redundancy Techniques
Consider the cluster in Figure 2.19(d). Assume only the nodes can fail. The rest of the system (e.g., interconnect and the shared RAID disk) is 100 percent available. Also assume that when a node fails, its workload is switched over to the other node in zero time. We ask, what is the availability of the cluster if planned downtime is ignored? What is the availability if the cluster needs one hour/week for maintenance? What is the availability if it is shut down one hour/week, one node at a time?
According to Table 2.4, a workstation is available 99 percent of the time. The time both nodes are down is only 0.01 percent. Thus, the availability is 99.99 percent. It is now a fault-resilient sys-tem, with only one hour of downtime per year. The planned downtime is 52 hours per year, that is, 52 / (365 × 24) = 0.0059. The total downtime is now 0.59 percent + 0.01 percent = 0.6 percent. The availability of the cluster becomes 99.4 percent. Suppose we ignore the unlikely situation in which the other node fails while one node is maintained. Then the availability is 99.99 percent.
There are basically two ways to increase the availability of a system: increasing MTTF or redu-cing MTTR. Increasing MTTF amounts to increasing the reliability of the system. The computer industry has strived to make reliable systems, and today’s workstations have MTTFs in the range of hundreds to thousands of hours. However, to further improve MTTF is very difficult and costly. Clus-ters offer an HA solution based on reducing the MTTR of the system. A multinode cluster has a lower MTTF (thus lower reliability) than a workstation. However, the failures are taken care of quickly to deliver higher availability. We consider several redundancy techniques used in cluster design.
6. Isolated Redundancy
A key technique to improve availability in any system is to use redundant components. When a component (the primary component) fails, the service it provided is taken over by another compo-nent (the backup component). Furthermore, the primary and the backup components should be iso-lated from each other, meaning they should not be subject to the same cause of failure. Clusters provide HA with redundancy in power supplies, fans, processors, memories, disks, I/O devices, net-works, operating system images, and so on. In a carefully designed cluster, redundancy is also isolated. Isolated redundancy provides several benefits:
• First, a component designed with isolated redundancy is not a single point of failure, and the failure of that component will not cause a total system failure.
• Second, the failed component can be repaired while the rest of the system is still working.
• Third, the primary and the backup components can mutually test and debug each other.
The IBM SP2 communication subsystem is a good example of isolated-redundancy design. All nodes are connected by two networks: an Ethernet network and a high-performance switch. Each node uses two separate interface cards to connect to these networks. There are two communication protocols: a standard IP and a user-space (US) protocol; each can run on either network. If either network or protocol fails, the other network or protocol can take over.
7. N-Version Programming to Enhance Software Reliability
A common isolated-redundancy approach to constructing a mission-critical software system is called N-version programming. The software is implemented by N isolated teams who may not even know the others exist. Different teams are asked to implement the software using different algorithms, programming languages, environment tools, and even platforms. In a fault-tolerant system, the N versions all run simultaneously and their results are constantly compared. If the results differ, the system is notified that a fault has occurred. But because of isolated redundancy, it is extremely unli-kely that the fault will cause a majority of the N versions to fail at the same time. So the system continues working, with the correct result generated by majority voting. In a highly available but less mission-critical system, only one version needs to run at a time. Each version has a built-in self-test capability. When one version fails, another version can take over.
Related Topics