Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Computer Clusters for Scalable Parallel Computing
Case Studies of Top Supercomputer Systems
CASE STUDIES OF TOP SUPERCOMPUTER SYSTEMS
This section reviews three top supercomputers
that have been singled out as winners in the Top 500 List for the years 2008–2010. The IBM Roadrunner was the world’s first petaflops computer, ranked No. 1 in 2008. Subsequently, the
Cray XT5 Jaguar became the top system in 2009. In November 2010, Chi-na’s Tianhe-1A became the fastest system in the world. All three systems
are Linux cluster-structured with massive parallelism in term of large number
of compute nodes that can execute concurrently.
1. Tianhe-1A: The World Fastest
Supercomputer in 2010
In November 2010, the Tianhe-1A was unveiled as
a hybrid supercomputer at the 2010 ACM Supercom-puting Conference. This system
demonstrated a sustained speed of 2.507 Pflops in Linpack Benchmark testing
runs and thus became the No. 1 supercomputer in the 2010 Top 500 list. The
system was built by the National University of Defense Technology (NUDT) and
was installed in August 2010 at the National Supercomputer Center (NSC),
Tianjin, in northern China (www.nscc.tj.gov.cn). The system is intended as an
open platform for research and education. Figure 2.24 shows the Tianh-1A system
installed at NSC.
1.1
Architecture of Tianhe-1A
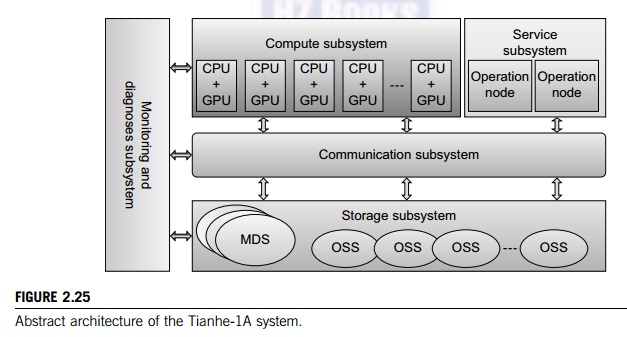
Figure 2.25 shows the
abstract architecture of the Tianhe-1A system. The system consists of five
major components. The compute subsystem houses all the CPUs and GPUs on 7,168
compute nodes. The service subsystem comprises eight operation nodes. The
storage subsystem has a large number of shared disks. The monitoring and
diagnosis subsystem is used for control and I/O operations. The communication
subsystem is composed of switches for connecting to all functional subsystems.
1.2 Hardware Implementation
This system is equipped with 14,336 six-core
Xeon E5540/E5450 processors running 2.93 GHz with 7,168 NVIDIA Tesla M2050s. It
has 7,168 compute
nodes, each
composed of two Intel Xeon X5670 (Westmere) processors at 2.93 GHz, six cores
per socket, and one NVIDIA M2050 GPU

connected via PCI-E. A blade has two nodes and
is 2U in height (Figure 2.25). The complete sys-tem has 14,336 Intel sockets
(Westmere) plus 7,168 NVIDIA Fermi boards plus 2,048 Galaxy sock-ets (the
Galaxy processor-based nodes are used as frontend processing for the system). A
compute node has two Intel sockets plus a Fermi board plus 32 GB of memory.

The
total system has a theoretical peak of 4.7 Pflops/second as calculated in
Figure 2.26. Note that there are 448 CUDA cores in each GPU node. The peak
speed is achieved through 14,236 Xeon CPUs (with 380,064 cores) and 7,168 Tesla
GPUs (with 448 CUDA cores per node and 3,496,884 CUDA cores in total). There
are 3,876,948 processing cores in both the CPU and GPU chips. An operational
node has two eight-core Galaxy chips (1 GHz, SPARC architecture) plus 32 GB of
memory. The Tianhe-1A system is packaged in 112 compute cabinets, 12 storage
cabinets, six communications cabinets, and eight I/O cabinets.
The
operation nodes are composed of two eight-core Galaxy FT-1000 chips. These
processors were designed by NUDT and run at 1 GHz. The theoretical peak for the
eight-core chip is 8 Gflops/second. The complete system has 1,024 of these
operational nodes with each having 32 GB of memory. These operational nodes are
intended to function as service nodes for job crea-tion and submission. They
are not intended as general-purpose computational nodes. Their speed is
excluded from the calculation of the peak or sustained speed. The peak speed of
the Tianhe-1A is calculated as 3.692 Pflops [11]. It uses 7,168 compute nodes
(with 448 CUDA cores/GPU/compute node) in parallel with 14,236 CPUs with six
cores in four subsystems.
The
system has total disk storage of 2 petabytes implemented with a Lustre
clustered file sys-tem. There are 262 terabytes of main memory distributed in
the cluster system. The Tianhe-1A epi-tomizes modern heterogeneous CPU/GPU
computing, enabling significant achievements in performance, size, and power.
The system would require more than 50,000 CPUs and twice as much floor space to
deliver the same performance using CPUs alone. A 2.507-petaflop system built
entirely with CPUs would consume at least 12 megawatts, which is three times
more power than what the Tianhe-1A consumes.
1.3
ARCH Fat-Tree Interconnect
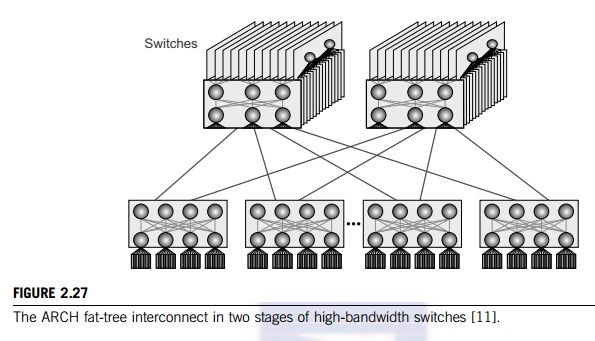
The high performance of the Tianhe-1A is
attributed to a customed-designed ARCH interconnect by the NUDT builder. This
ARCH is built with the InfiniBand DDR 4X and 98 TB of memory. It assumes a
fat-tree architecture as shown in Figure 2.27. The bidirectional bandwidth is
160 Gbps, about twice the bandwidth of the QDR InfiniBand network over the same
number of nodes. The ARCH has a latency for a node hop of 1.57 microseconds,
and an aggregated bandwidth of 61 Tb/ second. At the first stage of the ARCH
fat tree, 16 nodes are connected by a 16-port switching board. At the second
stage, all parts are connects to eleven 384-port switches. The router and
net-work interface chips are designed by the NUDT team.
1.4
Software Stack
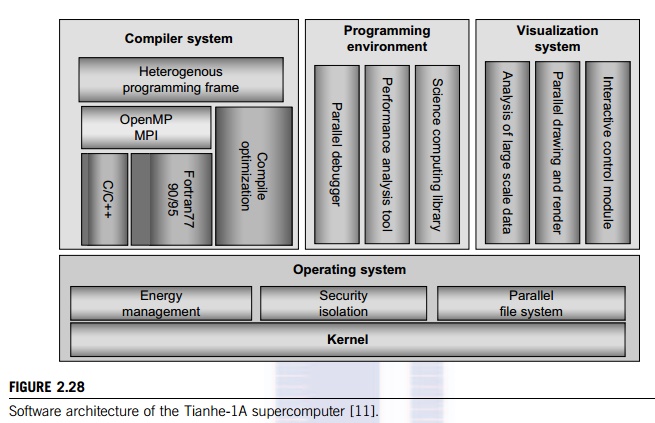
The software stack on the Tianhe-1A is typical
of any high-performance system. It uses Kylin Linux, an operating system
developed by NUDT and successfully approved by China’s 863 Hi-tech Research and Development Program office in 2006.
Kylin is based on Mach and FreeBSD, is compatible with other mainstream
operating systems, and supports multiple microprocessors and computers of
different struc-tures. Kylin packages include standard open source and public
packages, which have been brought onto one system for easy installation. Figure
2.28 depicts the Tianhe-1A software architecture.
The system features FORTRAN, C, C++, and Java
compilers from Intel (icc 11.1), CUDA, OpenMP, and MPI based on MPICH2 with
custom GLEX (Galaxy Express) Channel support. The NUDT builder developed a
mathematics library, which is based on Intel’s MKL 10.3.1.048 and BLAS for the GPU based on
NVIDIA and optimized by NUDT. In addition, a High Productive Parallel Running
Environ-ment (HPPRE) was installed. This provides a parallel toolkit based on
Eclipse, which is intended to inte-grate all the tools for editing, debugging,
and performance analysis. In addition, the designers provide workflow support
for Quality of Service (QoS) negotiations and resource reservations.
1.5
Power Consumption, Space, and Cost
The power consumption of the
Tianhe-1A under load is 4.04 MWatt. The system has a footprint of 700 square
meters and is cooled by a closed-coupled chilled water-cooling system with
forced air. The hybrid architecture consumes less power—about one-third of the 12 MW that is needed to
run the system entirely with the multicore CPUs. The budget for the system is
600 million RMB (approximately $90 million); 200 million RMB comes from the
Ministry of Science and Technol-ogy (MOST) and 400 million RMB is from the
Tianjin local government. It takes about $20 million annually to run, maintain,
and keep the system cool in normal operations.
1.6 Linpack Benchmark Results and Planned
Applications
The performance of the Linpack Benchmark on
October 30, 2010 was 2.566 Pflops/second on a matrix of 3,600,000 and a N1/2 = 1,000,000. The total time
for the run was 3 hours and 22 minutes.
The
system has an efficiency of 54.58 percent, which is much lower than the 75
percent efficiency achieved by Jaguar and Roadrunner. Listed below are some
applications of Tianhe-1A. Most of them are specially tailored to satisfy China’s national needs.
• Parallel AMR (Adaptive Mesh
Refinement) method
• Parallel eigenvalue problems
• Parallel fast multipole
methods
• Parallel computing models
• Gridmol computational
chemistry
• ScGrid middleware, grid
portal
• PSEPS parallel symmetric eigenvalue
package solvers
• FMM-radar fast multipole
methods on radar cross sections
• Transplant many open source
software programs
• Sandstorm prediction, climate
modeling, EM scattering, or cosmology
• CAD/CAE for automotive
industry
2. Cray XT5 Jaguar: The Top Supercomputer
in 2009
The Cray XT5 Jaguar was ranked the world’s fastest supercomputer in the Top 500 list
released at the ACM Supercomputing Conference in June 2010. This system became
the second fastest super-computer in the Top 500 list released in November
2010, when China’s Tianhe-1A replaced the
Jaguar as the No. 1 machine. This is a scalable MPP system built by Cray, Inc.
The Jaguar belongs to Cray’s system model XT5-HE. The
system is installed at the Oak Ridge National Laboratory,
Department of Energy, in the
United States. The entire Jaguar system is built with 86 cabinets. The
following are some interesting architectural and operational features of the
Jaguar system:
• Built with AMD six-core
Opteron processors running Linux at a 2.6 GHz clock rate
• Has a total of 224,162 cores
on more than 37,360 processors in 88 cabinets in four rows (there are 1,536 or
2,304 processor cores per cabinet)
• Features 8,256 compute nodes
and 96 service nodes interconnected by a 3D torus network, built with Cray
SeaStar2+ chips
• Attained a sustained speed, Rmax, from the Linpack Benchmark
test of 1.759 Pflops
• Largest Linpack matrix size
tested recorded as Nmax = 5,474,272 unknowns
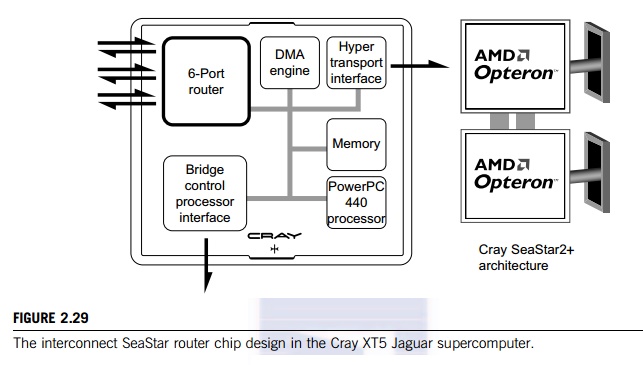
The
basic building blocks are the compute blades. The interconnect router in the
SeaStar+ chip (Figure 2.29) provides six high-speed links to six neighbors in
the 3D torus, as seen in Figure 2.30. The system is scalable by design from
small to large configurations. The entire system has 129 TB of compute memory.
In theory, the system was designed with a peak speed of Rpeak = 2.331 Pflops. In other
words, only 75 percent (=1.759/2.331) efficiency was achieved in Linpack
experiments. The external I/O interface uses 10 Gbps Ethernet and InfiniBand
links. MPI 2.1 was applied in mes-sage-passing programming. The system consumes
32–43 KW per cabinet. With 160
cabinets, the entire system consumes up to 6.950 MW. The system is cooled with
forced cool air, which con-sumes a lot of electricity.
2.1
3D Torus Interconnect
Figure 2.30 shows the system’s interconnect architecture. The Cray XT5
system incorporates a high-bandwidth, low-latency interconnect using the Cray
SeaStar2+ router chips. The system is con-figured with XT5 compute blades with
eight sockets supporting dual or quad-core Opterons. The XT5 applies a 3D torus
network topology. This SeaStar2+ chip provides six high-speed network
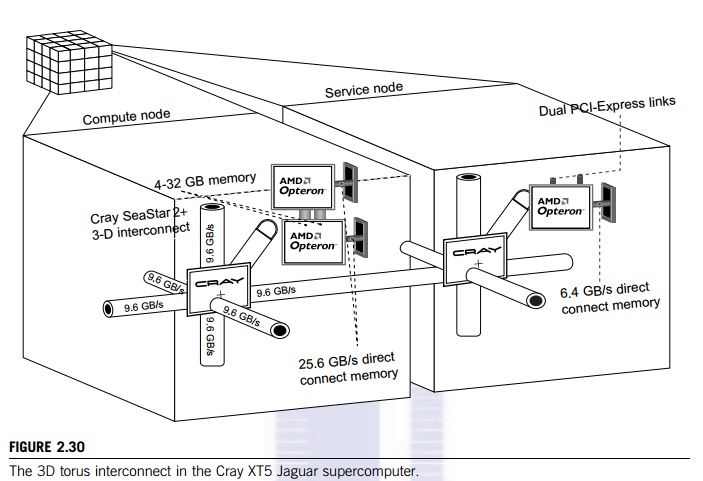
links which connect to six
neighbors in the 3D torus. The peak bidirectional bandwidth of each link is 9.6
GB/second with sustained bandwidth in excess of 6 GB/second. Each port is
configured with an independent router table, ensuring contention-free access
for packets.
The
router is designed with a reliable link-level protocol with error correction
and retransmission, ensuring that message-passing traffic reliably reaches its
destination without the costly timeout and retry mechanism used in typical
clusters. The torus interconnect directly connects all the nodes in the Cray
XT5 system, eliminating the cost and complexity of external switches and
allowing for easy expandability. This allows systems to economically scale to
tens of thousands of nodes— well beyond the capacity of
fat-tree switches. The interconnect carries all message-passing and I/O traffic
to the global file system.
2.2
Hardware Packaging
The Cray XT5 family employs an energy-efficient
packaging technology, which reduces power use and thus lowers maintenance
costs. The system’s compute blades are packaged
with only the necessary components for building an MPP with processors,
memory, and interconnect. In a Cray XT5 cabinet, vertical cooling takes cold
air straight from its source—the floor—and efficiently cools the processors on the
blades, which are uniquely positioned for optimal airflow. Each processor also
has a custom-designed heat sink depending on its position within the cabinet.
Each Cray XT5 sys-tem cabinet is cooled with a single, high-efficiency ducted
turbine fan. It takes 400/480VAC directly from the power grid without
transformer and PDU loss.
The Cray
XT5 3D torus architecture is designed for superior MPI performance in HPC
applica-tions. This is accomplished by incorporating dedicated compute nodes
and service nodes. Compute nodes are designed to run MPI tasks efficiently and
reliably to completion. Each compute node is composed of one or two AMD Opteron
microprocessors (dual or quad core) and direct attached memory, coupled with a
dedicated communications resource. Service nodes are designed to provide system
and I/O connectivity and also serve as login nodes from which jobs are compiled
and launched. The I/O bandwidth of each compute node is designed for 25.6
GB/second performance.
3. IBM Roadrunner: The Top
Supercomputer in 2008
In 2008, the IBM Roadrunner
was the first general-purpose computer system in the world to reach petaflops
performance. The system has a Linpack performance of 1.456 Pflops and is
installed at the Los Alamos National Laboratory (LANL) in New Mexico.
Subsequently, Cray’s Jaguar topped the
Roadrunner in late 2009. The system was used mainly to assess the decay of the
U.S. nuclear arsenal. The system has a hybrid design with 12,960 IBM 3.2 GHz
PowerXcell 8i CPUs (Figure 2.31) and 6,480 AMD 1.8 GHz Opteron 2210 dual-core
processors. In total, the system has 122,400 cores. Roadrunner is an Opteron
cluster accelerated by IBM Cell processors with eight floating-point cores.
3.1
Processor Chip and Compute Blade Design
The Cell/B.E. processors provide extraordinary
compute power that can be harnessed from a single multicore chip. As shown in
Figure 2.31, the Cell/B.E. architecture supports a very broad range of
applications. The first implementation is a single-chip multiprocessor with
nine processor elements
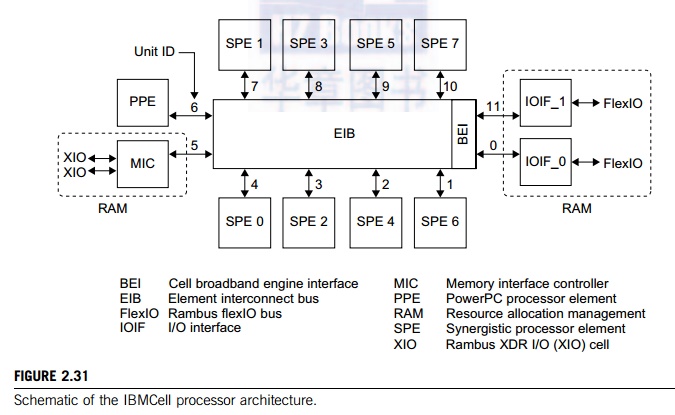
operating on a shared memory
model. The rack is built with TriBlade servers, which are connected by an
InfiniBand network. In order to sustain this compute power, the connectivity
within each node con-sists of four PCI Express x8 links, each capable of 2 GB/s
transfer rates, with a 2 μs latency. The expansion slot
also contains the InfiniBand interconnect, which allows communications to the
rest of the cluster. The capability of the InfiniBand interconnect is rated at
2 GB/s with a 2 μs latency.
3.2
InfiniBand Interconnect
The Roadrunner cluster was
constructed hierarchically. The InfiniBand switches cluster together 18
connected units in 270 racks. In total, the cluster connects 12,960 IBM Power
XCell 8i processors and 6,480 Opteron 2210 processors together with a total of
103.6 TB of RAM. This cluster com-plex delivers approximately 1.3 Pflops. In
addition, the system’s 18 Com/Service nodes
deliver 4.5 Tflops using 18 InfiniBand switches. The second storage units are
connected with eight InfiniBand switches. In total, 296 racks are installed in
the system. The tiered architecture is constructed in two levels. The system
consumes 2.35 MW power, and was the fourth most energy-efficient supercom-puter
built in 2009.
3.3
Message-Passing Performance
The Roadrunner uses MPI APIs to communicate
with the other Opteron processors the application is running on in a typical
single-program, multiple-data (SPMD) fashion. The number of compute nodes used
to run the application is determined at program launch. The MPI implementation
of Roadrunner is based on the open source Open MPI Project, and therefore is
standard MPI. In this regard, Roadrunner applications are similar to other
typical MPI applications such as those that run on the IBM Blue Gene solution.
Where Roadrunner differs in the sphere of application architecture is how its
Cell/B.E. accel-erators are employed. At any point in the application flow, the
MPI application running on each Opteron can offload computationally complex
logic to its subordinate Cell/B.E. processor.
Related Topics