Chapter: Embedded and Real Time Systems : Introduction to Embedded Computing
CPU Performance
CPU
PERFORMANCE:
Now that
we have an understanding of the various types of instructions that CPUs can
execute, we can move on to a topic particularly important in embedded
computing: How fast can the CPU execute instructions? In this section, we
consider three factors that can substantially influence program performance:
pipelining and caching.
1.
Pipelining
Modern
CPUs are designed as pipelined machines in which several
instructions are executed in parallel. Pipelining greatly increases the
efficiency of the CPU. But like any pipeline, a CPU pipeline works best when
its contents flow smoothly.
Some
sequences of instructions can disrupt the flow of information in the pipeline
and, temporarily at least, slow down the operation of the CPU.
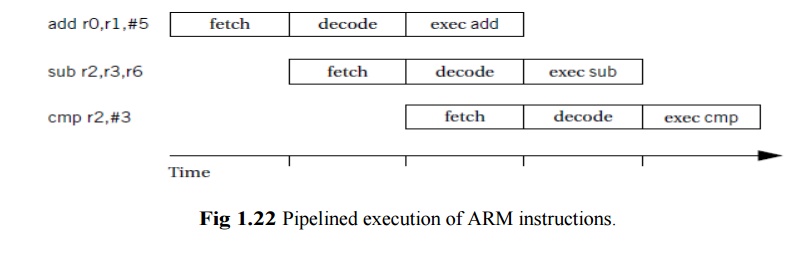
The ARM7
has a three-stage pipeline:
Fetch the
instruction is fetched from memory.
Decode the
instruction’s opcode and operands are decoded to determine what function to
perform.
Execute the
decoded instruction is executed.
Each of
these operations requires one clock cycle for typical instructions. Thus, a
normal instruction requires three clock cycles to completely execute, known as
the latency
of instruction execution. But since the pipeline has three stages, an
instruction is completed in every clock cycle. In other words, the pipeline has
a throughput
of one instruction per cycle.
Figure
1.22 illustrates the position of instructions in the pipeline during execution
using the notation introduced by Hennessy and Patterson [Hen06]. A vertical
slice through the timeline shows all instructions in the pipeline at that time.
By following an instruction horizontally, we can see the progress of its
execution.
The C55x
includes a seven-stage pipeline [Tex00B]:
Fetch.
Decode.
Address computes data and branch
addresses.
Access 1 reads data.
Access 2 finishes data read.
Read stage puts operands onto internal
busses.
Execute performs operations.
RISC
machines are designed to keep the pipeline busy. CISC machines may display a
wide variation in instruction timing. Pipelined RISC machines typically have
more regular timing characteristics most instructions that do not have pipeline
hazards display the same latency.
2.
Caching
We have
already discussed caches functionally. Although caches are invisible in the
programming model, they have a profound effect on performance. We introduce
caches because they substantially reduce memory access time when the requested
location is in the cache.
However,
the desired location is not always in the cache since it is considerably
smaller than main memory. As a result, caches cause the time required to access
memory to vary considerably. The extra time required to access a memory
location not in the cache is often called the cache miss penalty.
The
amount of variation depends on several factors in the system architecture, but
a cache miss is often several clock cycles slower than a cache hit. The time
required to access a memory location depends on whether the
requested
location is in the cache. However, as we have seen, a location may not be in
the cache for several reasons.
At a
compulsory miss, the location has not been referenced before.
At a
conflict miss, two particular memory locations are fighting for the same cache
line.
At a
capacity miss, the program’s working set is simply too large for the cache.
The
contents of the cache can change considerably over the course of execution of a
program. When we have several programs running concurrently on the CPU,
Related Topics