Chapter: Compilers : Principles, Techniques, & Tools : Lexical Analysis
The Role of the Lexical Analyzer
The Role of the Lexical Analyzer
1 Lexical Analysis Versus Parsing
2 Tokens, Patterns, and Lexemes
3 Attributes for Tokens
4 Lexical Errors
5 Exercises for Section 3.1
As the first phase of a compiler, the main task of the lexical analyzer
is to read the input characters of the source program, group them into lexemes,
and produce as output a sequence of tokens for each lexeme in the source program.
The stream of tokens is sent to the parser for syntax analysis. It is common
for the lexical analyzer to interact with the symbol table as well. When the
lexical analyzer discovers a lexeme constituting an identifier, it needs to
enter that lexeme into the symbol table. In some cases, information regarding
the kind of identifier may be read from the symbol table by the lexical
analyzer to assist it in determining the proper token it must pass to the
parser.
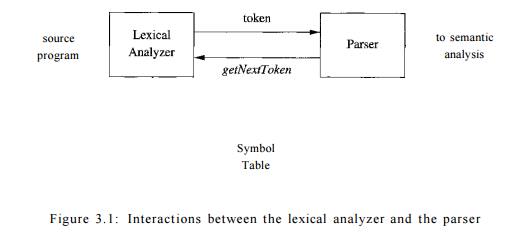
These interactions are suggested in Fig. 3.1. Commonly, the interaction
is implemented by having the parser call the lexical analyzer. The call,
suggested by the getNextToken
command, causes the lexical analyzer to read characters from its input until it
can identify the next lexeme and produce for it the next token, which it
returns to the parser.
Since the lexical analyzer is the part of the compiler that reads the
source text, it may perform certain other tasks besides identification of
lexemes. One such task is stripping out comments and whitespace (blank, newline, tab, and perhaps other characters that
are used to separate tokens in the input). Another task is correlating error
messages generated by the compiler with the source program. For instance, the
lexical analyzer may keep track of the number of newline characters seen, so it
can associate a line number with each error message. In some compilers, the
lexical analyzer makes a copy of the source program with the error messages
inserted at the appropriate positions. If the source program uses a
macro-preprocessor, the expansion of macros may also be performed by the
lexical analyzer.
Sometimes, lexical analyzers are divided into a cascade of two
processes:
Scanning consists of the simple processes
that do not require tokenization of
the input, such as deletion of comments and compaction of consecutive
whitespace characters into one.
Lexical analysis proper is the more complex
portion, where the scanner produces
the sequence of tokens as output.
1. Lexical Analysis Versus
Parsing
There are a number of reasons why the analysis portion of a compiler is
normally separated into lexical analysis and parsing (syntax analysis) phases.
1. Simplicity of design is the most important consideration. The
separation of lexical and syntactic analysis often allows us to simplify at
least one of these tasks. For example, a parser that had to deal with comments
and whitespace as syntactic units would be considerably more complex than one
that can assume comments and whitespace have already been removed by the
lexical analyzer. If we are designing a new language, separating lexical and
syntactic concerns can lead to a cleaner overall language design.
2. Compiler efficiency is improved. A separate lexical analyzer allows
us to apply specialized techniques that serve only the lexical task, not the
job of parsing. In addition, specialized buffering techniques for reading input
characters can speed up the compiler significantly.
Compiler portability is enhanced.
Input-device-specific peculiarities can be restricted to the lexical analyzer.
2. Tokens, Patterns, and Lexemes
When discussing lexical analysis, we use three related but distinct
terms:
A token is a pair consisting of a token name and an optional
attribute value. The token name is an abstract symbol representing a kind of
lexical unit, e.g., a particular keyword, or a sequence of input characters
denoting an identifier. The token names are the input symbols that the parser
processes. In what follows, we shall generally write the name of a
token in boldface. We will often
refer to a token by its token name.
• A pattern is a description
of the form that the lexemes of a token may take. In the case of a keyword as a
token, the pattern is just the sequence of characters that form the keyword.
For identifiers and some other tokens, the pattern is a more complex structure that
is matched by many strings.
A lexeme is a sequence of characters in the source program that
matches the pattern for a token and is identified by the lexical analyzer as an
instance of that token.
E x a m p l e 3 . 1 : Figure 3.2 gives some typical tokens, their
informally described patterns, and some sample lexemes. To see how these
concepts are used in practice, in the C statement
printf ( " Total = %d\n", score ) ;
both printf and score are
lexemes matching the pattern for token
id, and
" Total = °/,d\n" is
a lexeme matching literal . •
In many programming languages, the following classes cover most or all
of the tokens:

One token for each keyword. The
pattern for a keyword is the same as the keyword itself.
Tokens for the1
operators, either individually or in classes such as the token comparison
rfientioned in Fig. 3.2.
One token representing all
identifiers.
One or more tokens representing
constants, such as numbers and literal strings.
Tokens for each punctuation
symbol, such as left and right parentheses, comma, and semicolon.
3. Attributes for Tokens
When more than one lexeme can match a pattern, the lexical analyzer must
provide the subsequent compiler phases additional information about the
par-ticular lexeme that matched. For example, the pattern for token number matches both 0 and 1, but it is
extremely important for the code generator to know which lexeme was found in
the source program. Thus, in many cases the lexical analyzer returns to the
parser not only a token name, but an attribute value that describes the lexeme
represented by the token; the token name in-fluences parsing decisions, while
the attribute value influences translation of tokens after the parse.
We shall assume that tokens have at most one associated attribute,
although this attribute may have a structure that combines several pieces of
information. The most important example is the token id, where we need to
associate with the token a great deal of information. Normally, information
about an identi-fier — e.g., its lexeme, its type, and the location at which it
is first found (in case an error message about that identifier must be issued)
— is kept in the symbol table. Thus, the appropriate attribute value for an
identifier is a pointer to the symbol-table entry for that identifier.
Tricky Problems When Recognizing
Tokens
Usually, given the pattern describing the lexemes of a token, it is
relatively simple to recognize matching lexemes when they occur on the input.
How-ever, in some languages it is not immediately apparent when we have seen an
instance of a lexeme corresponding to a token. The following example is taken
from Fortran, in the fixed-format still allowed in Fortran 90. In the statement
DO 5 I
= 1.25
it is not apparent that the first lexeme is D05I, an instance of the
identifier token, until we see the dot following the 1. Note that blanks in
fixed-format Fortran are ignored (an archaic convention). Had we seen a comma
instead of the dot, we would have had a do-statement
DO 5 I
= 1,25
in which the first lexeme is the keyword DO.
E x a m p l e 3 . 2 : The token names and associated attribute values for the For-tran
statement
E = M * C ** 2
are written below as a sequence of pairs.
<id, pointer to symbol-table entry for E>
<assign _ op>
<id, pointer to symbol-table entry for M>
<mult _ op>
<id, pointer to symbol-table entry for C>
<exp _ op>
<number, integer value 2>
Note that in certain pairs, especially operators, punctuation, and
keywords, there is no need for an attribute value. In this example, the token number has been given an integer-valued
attribute. In practice, a typical compiler would instead store a character
string representing the constant and use as an attribute value for number a pointer to that string. •
4. Lexical Errors
It is hard for a lexical analyzer to tell, without the aid of other
components, that there is a source-code error. For instance, if the string f i
is encountered for the first time in a C program in the context:
fi ( a == f ( x ) ) . . .
a lexical analyzer cannot tell whether f i is a misspelling of the
keyword if or an undeclared function identifier. Since f i is a valid lexeme
for the token id, the lexical analyzer must return the token id to the parser
and let some other phase of the compiler — probably the parser in this case —
handle an error due to transposition of the letters.
However, suppose a situation arises in which the lexical analyzer is
unable to proceed because none of the patterns for tokens matches any prefix of
the remaining input. The simplest recovery strategy is "panic mode"
recovery. We delete successive characters from the remaining input, until the
lexical analyzer can find a well-formed token at the beginning of what input is
left. This recovery technique may confuse the parser, but in an interactive
computing environment it may be quite adequate.
Other possible error-recovery actions are:
Delete one character from the
remaining input.
Insert a missing character into
the remaining input.
Replace a character by another
character.
Transpose two adjacent
characters.
Transformations like these may be tried in an attempt to repair the
input. The simplest such strategy is to see whether a prefix of the remaining
input can be transformed into a valid lexeme by a single transformation. This
strategy makes sense, since in practice most lexical errors involve a single
character. A more general correction strategy is to find the smallest number of
transforma-tions needed to convert the source program into one that consists
only of valid lexemes, but this approach is considered too expensive in
practice to be worth the effort.
5. Exercises for Section 3.1
Exercise 3 . 1 . 1 : Divide the following C + + program:
float limited Square ( x ) float x {
/* return s x - s q u a r e d , but never more t h a n 100 */
return ( x < = - 1 0 . 0 | | x > = 1 0 . 0 ) ? 1 0 0 : x * x ;
}
into appropriate lexemes, using the discussion of Section 3.1.2 as a
guide. Which lexemes should get associated lexical values? What should those
values be?
! Exercise 3 . 1 . 2 : Tagged
languages like HTML or XML are different from con-ventional programming
languages in that the punctuation (tags) are either very numerous (as in HTML)
or a user-definable set (as in XML). Further, tags can often have parameters.
Suggest how to divide the following HTML document:
Here is a photo of <B>my house</B>:
<PXIMG SRC = "house.gif"><BR>
See <A HREF = "morePix.html">More
Pictures</A> if you liked that one.<P>
into appropriate lexemes. Which lexemes should get associated lexical
values, and what should those values be?
Related Topics