Chapter: Compilers : Principles, Techniques, & Tools : Lexical Analysis
Finite Automata
Finite Automata
1 Nondeterministic Finite Automata
2 Transition Tables
3 Acceptance of Input Strings by Automata
4 Deterministic Finite Automata
5 Exercises for Section 3.6
We shall now discover how Lex turns its input program into a lexical
analyzer. At the heart of the transition is the formalism known as finite automata. These are essentially
graphs, like transition diagrams, with a few differences:
Finite automata are recognizers; they simply say
"yes" or "no" about each possible input string.
Finite automata come in two
flavors:
Nondeterministic finite automata (NFA)
have no restrictions on the labels of
their edges. A symbol can label several edges out of the same state, and e, the
empty string, is a possible label.
(b) Deterministic finite automata (DFA) have, for each state, and for
each symbol of its input alphabet exactly one edge with that symbol leaving
that state.
1.Nondeterministic Finite Automata
Both deterministic and nondeterministic finite automata are capable of
rec-ognizing the same languages. In fact these languages are exactly the same
languages, called the regular languages, that regular expressions can describe.4
Nondeterministic Finite Automata
A nondeterministic finite automaton (NFA) consists of:
A finite set of states 5.
A set of input symbols E, the
input alphabet. We assume that e, which stands for the empty string, is never a
member of E.
A transition function that gives,
for each state, and for each symbol in
E U {e} a set of next states.
A state so from S that is
distinguished as the start state (or initial state).
A set of states F, a subset of S,
that is distinguished as the accepting states (or final states).
We can represent either an NFA or DFA by a transition graph, where the
nodes are states and the labeled edges represent the transition function. There
is an edge labeled a from state s to state t if and only if t is one of the
next states for state s and input a. This graph is very much like a transition
diagram, except:
There is a small lacuna: as we
defined them, regular expressions cannot describe the empty language, since we
would never want to use this pattern in practice. However, finite automata can
define the empty language. In the theory, 0 is treated as an additional regular
expression for the sole purpose of defining the empty language.
The same symbol can label edges
from one state to several different states, and
An edge may be labeled by e, the
empty string, instead of, or in addition to, symbols from the input alphabet.
E x a m p l e 3 . 1 4 : The transition graph for an NFA recognizing the
language of regular expression (a|b)*abb is shown in Fig. 3.24. This abstract
example, describing all strings of a's and &'s ending in the particular
string abb, will be used throughout
this section. It is similar to regular expressions that describe languages of
real interest, however. For instance, an expression describing all files whose
name ends in .o is a n y * . o , where a n y stands for any printable
character.
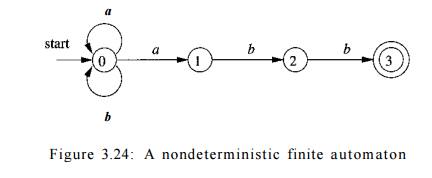
Following our convention for transition diagrams, the double circle
around state 3 indicates that this state is accepting. Notice that the only
ways to get from the start state 0 to the accepting state is to follow some
path that stays in state 0 for a while, then goes to states 1, 2, and 3 by
reading abb from the input. Thus, the
only strings getting to the accepting state are those that end in abb. •
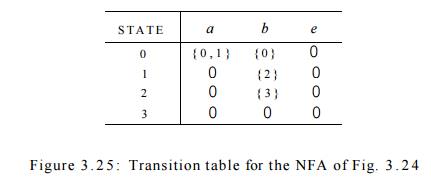
2. Transition Tables
We can also represent an NFA by a transition
table, whose rows correspond to states, and whose columns correspond to the
input symbols and e. The entry for a given state and input is the value of the
transition function applied to those arguments. If the transition function has
no information about that state-input pair, we put 0 in the table for the pair.
Example 3 . 1 5 : The transition table for the NFA of Fig.
3.24 is shown in
Fig. 3.25. •
The transition table has the advantage that we can easily find the
transitions on a given state and input. Its disadvantage is that it takes a lot
of space, when the input alphabet is large, yet most states do not have any
moves on most of the input symbols.
3. Acceptance of Input Strings by
Automata
An NFA accepts input string x if and only if there is some path in
the transition graph from the start state to one of the accepting states, such
that the symbols along the path spell out x.
Note that e labels along the path are effectively ignored, since the empty
string does not contribute to the string constructed along the path.

is another path from state 0 labeled by the string aabb. This path leads to state 0, which is not accepting. However,
remember that an NFA accepts a string as long as some path labeled by that string leads from the start state to an
accepting state. The existence of other paths leading to a nonaccepting state
is irrelevant. •
The language defined (or accepted) by an NFA is the set of strings
labeling some path from the start to an accepting state. As was mentioned, the
NFA of Fig. 3 . 2 4 defines the same language as does the regular expression
(a|b)*abb, that is, all strings from the alphabet {a, b} that end in abb. We
may use L(A) to stand for the language accepted by automaton A.

4. Deterministic Finite Automata
A deterministic finite automaton (DFA) is a special case of an NFA where:
There are no moves on
input e, and
For each state s and
input symbol a, there is exactly one edge out of s labeled a.
If we are using a transition table to represent a DFA, then each entry
is a single state, we may therefore represent this state without the curly
braces that we use to form sets.
While the NFA is an abstract representation of an algorithm to recognize
the strings of a certain language, the DFA is a simple, concrete algorithm for
recognizing strings. It is fortunate indeed that every regular expression and
every NFA can be converted to a DFA accepting the same language, because it is
the DFA that we really implement or simulate when building lexical analyzers.
The following algorithm shows how to apply a DFA to a string.
Algorithm 3.18 : Simulating a
DFA.
INPUT : An input string x
terminated by an end-of-file character eof.
A DFA D with start state so,
accepting states F, and transition function move.
OUTPUT : Answer "yes" if D accepts x; "no"
otherwise.
METHOD : Apply the algorithm in Fig. 3.27 to the input string x. The
function move(s,c) gives the state to which there is an edge from state s on
input c. The function next Char returns the next character of the input string
x. •
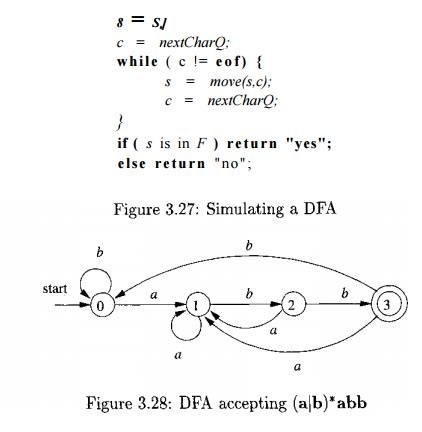
Example 3 . 1 9 : In Fig. 3.28 we see the transition graph of a DFA
accepting the language (a|b)*abb, the same as that accepted by the NFA of Fig.
3.24. Given the input string ababb, this DFA enters the sequence of states 0 ,
1 , 2 , 1 , 2 , 3 and returns "yes." •
5. Exercises for Section 3.6
Exercise 3 . 6 . 1 : Figure 3.19 in the exercises of Section 3.4 computes the failure function
for the KMP algorithm. Show how, given that failure function, we can construct,
from a keyword bib2 • • - bn an. n + 1-state DFA that recognizes *bib2 • • • bn, where the dot stands for "any character." Moreover, this DFA
can be constructed in 0(n) time.
Exercise 3 . 6 . 2 : Design finite automata (deterministic or nondeterministic) for each of the languages of Exercise 3.3.5.
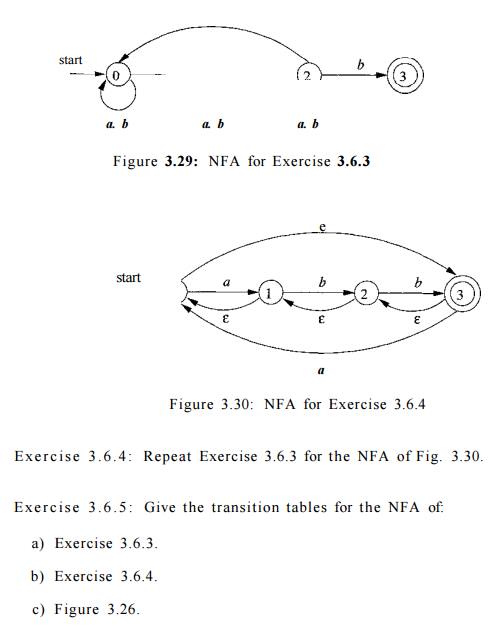
Exercise 3 . 6 . 3 : For the NFA of Fig. 3.29, indicate
all the paths labeled aabb. Does the NFA accept aabb?
Related Topics