Chapter: Pharmaceutical Biotechnology: Fundamentals and Applications : Molecular Biotechnology
Production by Recombinant DNA Technology
Production by Recombinant DNA Technology
Only two of the many examples available of the production of biopharmaceuticals by the recombinant DNA technology will be treated here: the production of human insulin and the production of the human growth hormone (hGH). The pharmaceutical aspects of both proteins are discussed.
The large scale production of human insulin nicely illustrates the synthetic DNA approach. Moreover, this example shows clearly that, besides knowledge of the coding gene, detailed knowledge of the protein to be produced is required.
The structural gene for human insulin is 1430 nucleotides long, while the gene is intervened by intron sequences of 179 and 786 nucleotides. The protein encoded by the gene is 110 amino acids in length. However, the mature protein encompasses a total of 51 amino acids. It consists of two separate chains: an A chain of 21 amino acids and a B chain of 30 amino acids. Chains A and B are held together by S bonds between the amino acids cysteine on the adjacent chains. The human insulin protein is appar-ently extensively processed after translation. Processing proceeds in two steps. The primary product, called preproinsulin, is 110 amino acids long in accordance with the prediction from the DNA sequence. During the membrane translocation of the protein the “pre” part of the protein, a stretch of 24 amino acids serving as the leader sequence for membrane translocation, is cleaved off. The remaining protein, 86 amino acids long, is called proinsulin. This protein is further processed in pancreatic cells, while an internal fragment (called the C or connecting chain) of 33 amino acids together with a few assorted amino acids is enzymatically removed. The A and B chains that are left are associated through S bonds and form the mature and biologically active insulin.
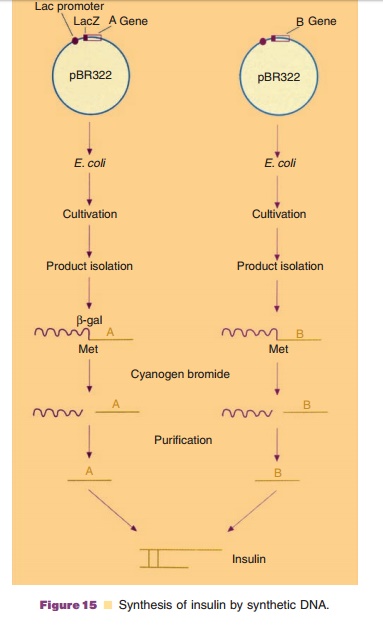
The strategy for the gene cloning according to the detailed knowledge of the mature protein, was toclone and produce the chains A and B separately. The information for the fragment A was assembled by linking a set of appropriate oligonucleotides. This DNA was then by ligation fused to the end of the gene lacZ, controlled by the lac-promoter, in the plasmidpBR322, a very well-known E. colicloning vector. At the fusion point between lacZ and the information for chain A a codon for the amino acid methionine was built in, for reasons that will be explained later on. The information for fragment B was (for strategic reasons) synthesized in two steps. Firstly, the N-terminal coding part was synthesized by linking oligonucleotides. This fragment was fused to the plasmid pBR322 and propagated in E. coli as such. Secondly, the C-terminal coding part was synthesized and also propagated after ligating it to pBR322. The two DNA fragments were then isolated from the respective recombinant DNA molecules. Both parts were linked together and fused at the end of the lacZ gene in the plasmid pBR322. Again the codon for the amino acid methionine was built in at the fusion point.
The linking of the information for A and B to the lacZ gene, part of the well-known lactose-operon, hastwo advantages. First of all, both fragments depend for their expression on the regimen of the lac-promoter and the lacZ gene, which allows an effective and controlled expression. Secondly, the peptides A and B are synthesized as products fused to β-galactosidase. Since especially small foreign peptidesin a bacterial cell are very vulnerable to proteolytic breakdown, the fusion strategy is an effective mean to prevent breakdown. Treatment of the isolated fusion proteins with the agent cyanogen bromide allows the isolation of the fragments A and B. This agent has the ability to cleave peptides whenever the amino acid methionine is present and cleaves immediately after this amino acid. Since neither fragment A nor B of insulin contain methionine and the cloning strategy guaranteed the presence of methionine at the fusion point, the isolation of peptides A and B as such is relatively simple. The final step consists of mixing A and B and allowing the S bonds to form sponta-neously. Figure 15 presents the procedure of insulin production with the help of synthetic DNA.
The strategy to clone and produce hGH shows some other interesting features. First of all, the production was initiated by making cDNA out of an mRNA pool derived from the human pituitary, the tissue where this peptide hormone is synthesized. The cDNA molecule coding for the hGH was isolated and, since it contained information of 24 amino acids that should guarantee transport in the human cell, it was reduced with an appropriate restriction enzyme. However, in this procedure the coding information for some of the amino acids essential for the activity of
the mature hormone was lost. This missing part of information lost from the original cDNA molecule was chemically synthesized and fused to the frag-mented cDNA molecule in order to get the full information for the mature hGH. Next, the construct was linked to a bacterial vector in such a way that it was fused to a strong promoter. In some constructs information coding for a bacterial leader sequence was linked to the hGH gene. Then, sequences coding for a bacterial leader peptide (a N-terminal sequence of about 20 amino acids) were added to induce translocation of the protein over the cytoplasmic membrane. This additional translocation sequence has rather specific physicochemical properties. The leader peptide signal enables a protein to cross the cytoplasmic membrane barrier during which the leader peptide is cleaved off. The reason for attaching an additional signal in this case is that in certainproduction strategies one wishes to obtain products that are released from the cytoplasm to be able to select a convenient purification strategy afterwards. If the hGH gene is linked to an appropriate leader peptide and expressed in the host E. coli, hGH molecules will show up in the space between the IM and the OM, the so-called periplasmic space. It is possible to damage the OM in such a way that the contents of the periplasm are set free. Then, purifica-tion of hGH is rather easy and cheaper than purification of hGH as a product in the cytoplasm of E. coli. Cloning strategies that guarantee membranetranslocation are frequently selected in order to release a protein from the cytoplasm.
Related Topics