Chapter: Data Warehousing and Data Mining
Mapping the data warehouse architecture to Multiprocessor architecture
Mapping
the data warehouse architecture to Multiprocessor architecture
1.Relational data base technology for data
warehouse
Linear Speed up: refers the ability to increase
the number of processor to reduce response time Linear Scale up: refers the ability to provide same performance on
the same requests as the database
size increases
1.1. Types of
parallelism
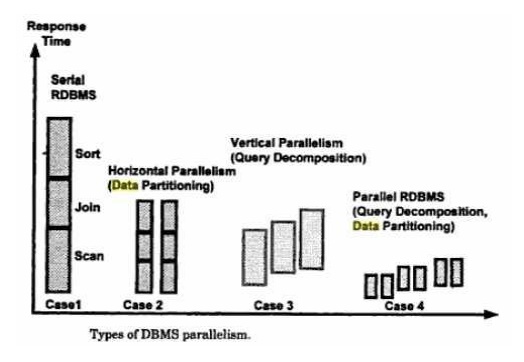
Inter query Parallelism: In which
different server threads or processes handle multiple requests at the same time.
Intra query Parallelism: This form
of parallelism decomposes the serial SQL query into
lower
level operations such as scan, join, sort etc. Then these lower level
operations are executed concurrently in parallel.
Intra
query parallelism can be done in either of two ways:
Horizontal parallelism: which
means that the data base is partitioned across multiple disks and parallel processing occurs within a
specific task that is performed concurrently on different processors against
different set of data
Vertical parallelism: This
occurs among different tasks. All query components such as scan, join, sort etc are executed in parallel
in a pipelined fashion. In other words, an output from one task becomes an
input into another task.
1.2 Data
partitioning:
Data
partitioning is the key component for effective parallel execution of data base
operations. Partition can be done randomly or intelligently.
Random portioning:
Includes
random data striping across multiple disks on a single server.
Another
option for random portioning is round robin fashion partitioning in which each
record is placed on the next disk assigned to the data base.
Intelligent partitioning:
Assumes
that DBMS knows where a specific record is located and does not waste time
searching for it across all disks. The various intelligent partitioning
include:
Hash partitioning: A hash
algorithm is used to calculate the partition number based on the value of the partitioning key for each
row
Key range partitioning: Rows are
placed and located in the partitions according to the value of the partitioning key. That is all the rows with the key value
from A to K are in partition 1, L to T are in partition 2 and so on.
Schema portioning: an entire
table is placed on one disk; another table is placed on different disk etc. This is useful for small
reference tables.
User defined portioning: It allows
a table to be partitioned on the basis of a user defined expression.
2. Data base architectures of parallel processing
There are
three DBMS software architecture styles for parallel processing:
Shared
memory or shared everything Architecture
Shared
disk architecture
Shred
nothing architecture
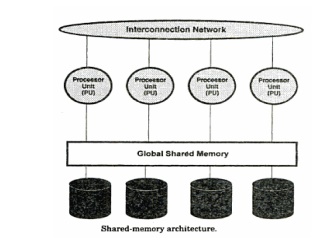
2.1 Shared
Memory Architecture:
Tightly
coupled shared memory systems, illustrated in following figure have the
following characteristics:
Multiple
PUs share memory.
Each PU
has full access to all shared memory through a common bus.
Communication
between nodes occurs via shared memory.
Performance
is limited by the bandwidth of the memory bus.
It is
simple to implement and provide a single system image, implementing an RDBMS on
SMP(symmetric
multiprocessor)
A
disadvantage of shared memory systems for parallel processing is as follows:
Scalability
is limited by bus bandwidth and latency, and by available memory.
2.2 Shared
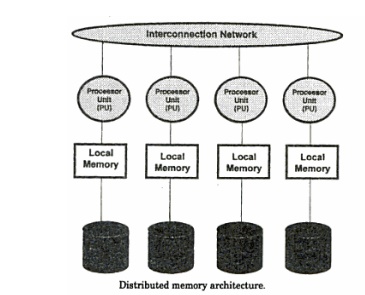
Disk Architecture
Shared
disk systems are typically loosely coupled. Such systems, illustrated in
following figure, have the following characteristics:
Each node
consists of one or more PUs and associated memory.
Memory is
not shared between nodes.
Communication
occurs over a common high-speed bus.
Each node
has access to the same disks and other resources.
A node
can be an SMP if the hardware supports it.
Bandwidth
of the high-speed bus limits the number of nodes (scalability) of the system.
. The
Distributed Lock Manager (DLM ) is required.
Parallel
processing advantages of shared disk systems are as follows:
Shared
disk systems permit high availability. All data is accessible even if one node
dies.
These
systems have the concept of one database, which is an advantage over shared
nothing systems.
Shared
disk systems provide for incremental growth.
Parallel
processing disadvantages of shared disk systems are these:
Inter-node
synchronization is required, involving DLM overhead and greater dependency on
high-speed interconnect.
If the
workload is not partitioned well, there may be high synchronization overhead.
![]()
2.3 Shared
Nothing Architecture
Shared
nothing systems are typically loosely coupled. In shared nothing systems only
one CPU is connected to a given disk. If a table or database is located on that
disk
Shared
nothing systems are concerned with access to disks, not access to memory.
Adding
more PUs and disks can improve scale up.
Shared
nothing systems have advantages and disadvantages for parallel processing:
Advantages
Shared
nothing systems provide for incremental growth.
System
growth is practically unlimited.
MPPs are
good for read-only databases and decision support applications.
Failure
is local: if one node fails, the others stay up.
Disadvantages
More
coordination is required.
More
overhead is required for a process working on a disk belonging to another node.
If there
is a heavy workload of updates or inserts, as in an online transaction
processing system, it may be worthwhile to consider data-dependent routing to
alleviate contention.
These
Requirements include
Support
for function shipping
Parallel
join strategies
Support
for data repartitioning
Query
compilation
Support
for database transactions
Support
for the single system image of the database environment
Combined architecture
Interserver parallelism: each
query is parallelized across multiple servers
Interaserver parallelism: the
query is parallelized with in a server
The
combined architecture supports inter server parallelism of distributed memory
MPPs and cluster and interserver parallelism of SMP nodes
3. Parallel DBMS features
Scope and
techniques of parallel DBMS operations
Optimizer implementation
Application
transparency
Parallel
environment: which allows the DBMS server to take full advantage of the
existing facilities on a very low level?
DBMS
management tools: help to configure, tune, admin and monitor a parallel RDBMS
as effectively as if it were a serial RDBMS
Price /
Performance: The parallel RDBMS can demonstrate a non linear speed up and scale
up at reasonable costs.
4. Alternative technologies
For improving performance in dw environment
includes
Advanced
database indexing products
Multidimensional
databases
Specialized
RDBMS
Advance
indexing techniques REFER --SYSBASE IQ
5. Parallel DBMS Vendors
Oracle: support parallel database
processing
Architecture: virtual shared disk capability
Data partitioning: oracle 7 supports random
stripping
Parallel operations: oracle
may execute all queries serially
Informix: it support full parallelism.
Architecture: it support shared memory, shared
disk and shared nothing architecture.
Data partitioning: Informix online 7 supports
round-robin, schema, hash, key range partitioning.
Parallel operations: online
7 execute queries INSERT and many utilities in parallel release add parallel UPDATE and DELETE.
IBM: it is a parallel client/server
database product-DB2-E (parallel edition).
Architecture: it is shared nothing
architecture.
Data partitioning: hash partitioning.
Parallel operations: INSERT,
INDEX, CREATION are full parallelized.
SYBASE: it implemented its parallel
DBMS functionality in a product called SYBASE MPP (SYBSE+NCR).
Architecture: SYBASE MPP –shared nothing architecture.
Data partitioning: SYBASE MPP-key range, schema
partitioning.
Parallel operations: SYBASE
MPP-horizontal parallelism, but vertical parallelism support in limited
Other RDBMS products
NCR
Teradata
Tandem
Nonstop SQL/MP
7. Specialized database products
Red Brick
Systems
White
Cross System ins
Related Topics