Chapter: Data Warehousing and Data Mining
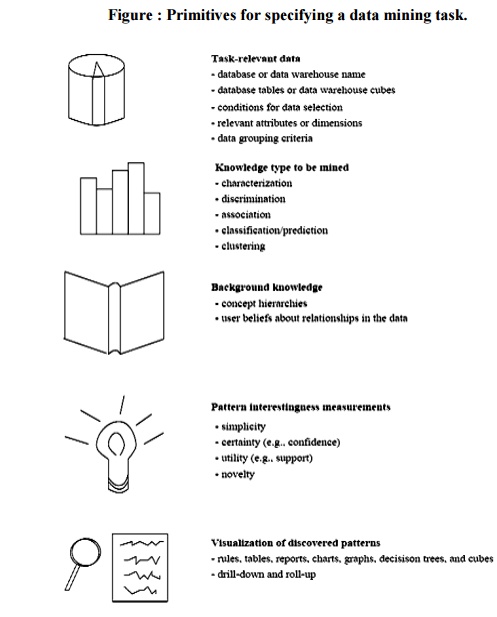
Data mining primitives
Data
mining primitives.
A data
mining query is defined in terms of the following primitives
Task-relevant
data: This is the database portion to be investigated. For example, suppose
that you are a manager of All
Electronics in charge of sales in the United States and Canada. In particular,
you would like to study the buying trends of customers in Canada. Rather than
mining on the entire database. These are referred to as relevant attributes
The kinds
of knowledge to be mined: This specifies the data mining functions to be
performed, such as characterization,
discrimination, association, classification, clustering, or evolution analysis.
For instance, if studying the buying habits of customers in Canada, you may
choose to mine associations between customer profiles and the items that these
customers like to buy
Background knowledge: Users can
specify background knowledge, or knowledge about the domain to be mined. This knowledge is useful for guiding the
knowledge discovery process, and for evaluating the patterns found. There are
several kinds of background knowledge.
Interestingness
measures: These functions are used to separate uninteresting patterns from knowledge. They may be used to guide
the mining process, or after discovery, to evaluate the discovered patterns.
Different kinds of knowledge may have different interestingness measures.
Presentation and visualization of
discovered patterns: This refers to the form in which discovered patterns are to be
displayed. Users can choose from different forms for knowledge presentation,
such as rules, tables, charts, graphs, decision trees, and cubes.
Related Topics