Chapter: Data Warehousing and Data Mining
DBMS Schemas for Decision Support
DBMS
Schemas for Decision Support
1.Data layout for business access
All industries have developed considerable expertise in implementing
efficient operational systems such as payroll, inventory tracking, and
purchasing. the original objectives in developing an abstract model known as
the relational model
The relational model is based on mathematical principals. The existing
relational database management ( RDBMSs) offer power full solution for a wide
variety of commercial and scientific applications
The data warehouse RDBMS typically needs to process queries that are
large complex, ad hoc, and data intensive. so data warehouse RDBMS are very
different ,it use a database schema for maximizing concurrency and optimizing
insert, update, and delete performance
For solving modern business problems such as market analysis and
financial forecasting requires query-centric database schemas that are array
oriented and multidimensional in nature.
2. Multidimensional
data model
Note –need write
about Multidimensional data model
3. Star
schema
Note –need
write about star schema
3.1 DBA view point
A star schema is a relational schema organized around a central table
joined to few smaller tables (dimension tables)using foreign key references
The fact table contains raw numeric items that represent relevant
business facts (price,dicont values, number of units sold,dollar sold,dollar
vaue,etc
The fact are accessed via dimensions since fact tables are pre
summarized and aggregated along business dimensions
The dimension table defines business dimension in terms already familiar
to user.the dimension table contain a non compound primary key and are heavily
indexed and these table are grouped and joined with fact table using foreign
key references.
A star schema created for every industry
3.2 Potential performance problem with star schemas
Indexing
It improve the performance in the star schema design
The table in star schema design contain the entire hierarchy of
attributes(PERIOD dimension this hierarchy could be
day->week->month->quarter->year),one approach is to create multi
part key of day, week, month ,quarter ,year .it presents some problems in the
star schema model because it should be in normalized
Problems
it require multiple metadata definitions
Since the fact table must carry all key components as part of its
primary key, addition or deletion of levels in the physical modification of the
affected table.
Carrying all the segments of the compound dimensional key in the fact
table increases the size of the index, thus impacting both performance and
scalability.
Solutions
One
alternative to the compound key is to concatenate the key into a single key for
the attributes (day, week, month, quarter, year) this is used to solve the
first above two problems.
The index
is remains problem the best approach is to drop the use of meaningful keys in
favor of using an artificial, generated key which is the smallest possible key
that will ensure the uniqueness of each record
Level
indicator
Problems
Another potential problem with the star schema
design is that in order to navigate the dimensions successfully.
The dimensional table design includes a level of hierarchy indicator for
every record.
Every query that is retrieving detail records from
a table that stores details & aggregates must use this indicator as an
additional constraint to obtain a correct result.
Solutions
The best alternative to using the level indicator is the snowflake
schema
The snowflake schema contains separate fact tables for each level of
aggregation. So it is Impossible to make a mistake of selecting product detail.
The snowflake schema is even more complicated than a star schema.
Other
problems with the star schema design:
The next
set of problems is related to the relational DBMS engine & optimization
technology.
Pairwise problem:
The traditional OLAP RDBMS engines are not designed for the set of
complex queries that can be issued against a star schema.
We need to retrieve related information from several query in a single
query has several limitation
Many OLTP RDBMS can join only two tables, so the complex query must be
in the RDBMS needs to break the query into series of pairwise joins. And also
provide the intermediate result. this process will be do up to end of the
result
Thus intermediate results can be large & very costly to create. It
affects the query performance. The number of ways to pairwise join a set of N
tables is N!( N factorial) for example.
The query has five table 5!=(6x5x4x3x2x1)=120 combinations.
Star schema join problem:
Because the number of pairwise join combinations is often too large to
fully evaluate many RDBMS optimizers limit the selection on the basis of a
particular criterion. In data warehousing environment this strategy is very
inefficient for star schemas.
In a star schema the only table directly related to most other tables in
the fact table this means that the fact table is natural candidate for the
first pairwise join.
Unfortunately the fact table is typically the very largest table in the
query. A pairwise join order generates very large intermediate result set. So
it affects query performance.
3.3 Solution to performance problems:
A common optimization provides some relief for the star schema join
problem.
The basic idea of this optimization is to get around the pairwise join
strategy of selecting only related tables.
When two tables are joined and no columns ―link‖ the tables every
combination of two tables’ rows are produced. In terms of relational algebra
this is called a Cartesian product.
Normally the RDBMS optimizer logic would never consider Cartesian
product but star schema considering these Cartesian products. Can sometimes
improve query.
Alternatively it is a Cartesian product of all dimension tables is first
generated.
The key cost is the need to generate the Cartesian product of the
dimension tables as long as the cost of generating the Cartesian product is
less than the cost of generating intermediate results with
the fact
table.
4.STARjoin and STARindex
A STARjoin
is a high-speed,
single-pass, parallelizable multitable
joins, and Brick’s
RDBMS can
join more than two tables in a single operation.
Red Brick’s RDBMS supports the creation of specialized indexes called
STARindexes. it created on one or more foreign key columns of a fact table.
5. Bitmapped indexing
The new
approach to increasing performance of a relational DBMS is to use innovative
indexing techniques to provide direct access to data. SYBASE IQ uses a bit
mapped index structure. The data stored in the SYBASE DBMS.
5.1
SYBASE IQ- it is based on indexing
technology; it is a stand alone database.
Overview:
It is a
separate SQL database. Data is loaded into a SYBASE IQ very much as into any relational
DBMS once loaded SYBASE IQ converts all data into a series of bitmaps which are
than highly compressed to store on disk.
Data
cardinality:
Data cardinality bitmap indexes are used to optimize queries against a
low cardinality data.
That is in which-The total no. of potential values in relatively low.
Example: state code data cardinality is 50 potential values and general
cardinality is only 2 ( male to female) for low cardinality data.
The each distinct value has its own bitmap index consisting of a bit for
every row in a table, if the bit for a given index is ―on‖ the value exists in
the record bitmap index representation is a 10000 bit long vector which has its
bits turned on(value of 1) for every record that satisfies ―gender‖=‖M‖
condition‖
Bit map indexes unsuitable for high cardinality data
Another solution is to use traditional B_tree index structure. B_tree
indexes can often grow to large sizes because as the data volumes & the
number of indexes grow.
B_tree indexes can significantly improve the performance,
SYBASE IQ was a technique is called bitwise (Sybase trademark)
technology to build bit map index for high cardinality data, which are limited
to about 250 distinct values for high cardinality data.
Index
types:
The first
of SYBASE IQ provide five index techniques, Most users apply two indexes to
every column.
the
default index called projection index and other is either a low or high –
cardinality index. For low cardinality data SYBASE IQ provides.
Low fast
index: it is optimized for queries involving scalar functions like SUM,AVERAGE,and COUNTS.
Low disk
index which is optimized for disk space utilization at the cost of being more
CPU-intensive.
Performance.
SYBAEE IQ
technology achieves the very good performance on adhoc quires for several
reasons
Bitwise
technology: this allows various types of data type in query.
And support fast data aggregation and
grouping.
Compression: SYBAEE
IQ uses sophisticated algorithms to compress data in to bit maps.
Optimized
m/y based programming: SYBASE IQ caches data columns in m/y according to the nature of user’s queries, it speed
up the processor.
Columnwise
processing: SYBASE IQ scans columns not rows, it reduce the
amount of data. the engine has to
search.
Low
overhead: An engine optimized for decision support SYBASE IQ does not carry on
overhead
associated with that. Finally OLTP designed RDBMS performance.
Large block I/P: Block
size of SYBASE IQ can turned from 512 bytes to 64 Kbytes so system can read much more information as necessary in single I/O.
Operating
system-level parallelism: SYBASE IQ breaks low level like the sorts, bitmap manipulation, load, and I/O, into
nonblocking operations.
Projection
and ad hoc join capabilities: SYBASE IQ allows users to take
advantage of known join relation
relationships between tables by defining them in advance and building indexes
between tables.
Shortcomings
of indexing:-
The user should be aware of when choosing to use
SYBASE IQ include
No updates-SYNBASE
IQ does not support updates .the users would have to update the source database and then load the
update data in SYNBASE IQ on a periodic basis.
Lack of
core RDBMS feature:-Not support all the robust features of SYBASE SQL
server, such as backup and recovery
Less
advantage for planned queries: SYBASE IQ, run on preplanned
queries.
High
memory usage: Memory access for the expensive i\o operation
5.6 Conclusion:-
SYBASE IQ
promise increased performance without deploying expensive parallel hardware
system.
6. Column
local storage:-
It is an another approach to improve query performance in the data
warehousing environment
For
example thinking machine operation has developed an innovative data layout
solution that improves RDBMS query performance many times. Implemented in its
CM_SQL RDBMS product, this approach is based on storing data columnwise as
opposed to traditional row wise approach.
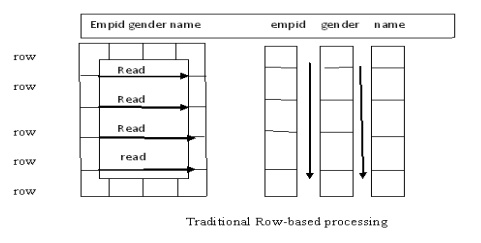
In figure-.(Row wise approach) This approach works well for OLTP
environment in which a typical transaction accesses a record at a time. However
in data warehousing the goal is to retrieve multiple values of several columns.
For
example if a problem is to calculate average minimum, maximum salary the
columnwise storage of the salary field requires a DBMS to read only one
record.(use Column –wise approach)
7. Complex
data types:-
The best DBMS architecture for data warehousing has been limited to
traditional alphanumeric data types. But data management is the need to support
complex data types , Include text, image, full-motion video &sound.
Large data objects called binary large objects what’s required by
business is much more than just storage:
The ability to retrieve the complex data type like an image by its
content. The ability to compare the content of one image to another in order to
make rapid business decision and ability to express all of this in a single SQL
statement.
The modern data warehouse DBMS has to be able to efficiently store,
access and manipulate complex data. The DBMS has to be able to define not only
new data structure but also new function that manipulates them and often new
access methods, to provide fast and often new access to the data.
An example of advantage of handling complex data types is a insurance
company that wants to predict its financial exposure during a catastrophe such
as flood that wants to support complex data.
Related Topics