Chapter: Psychology: Memory
Acquisition: Working Memory, Long-Term Memory
Working Memory,
Long-Term Memory
How does memory acquisition
proceed? The answer has to begin with the fact that we have several types of
memory, each with different properties, and each type plays its own role in the
acquisition process. Historically, these different types have been described in
terms of the stage theory of memory,
which proposed (among other points) that memory acquisition could be understood
as dependent on three types of memory: When information first arrived, it was
stored briefly in sensory memory,
which held onto the input in “raw” sensory form—an iconic memory for visual inputs and an echoic mem-ory for auditory inputs. A process of selection and
interpretation then moved the infor-mation into short-term memory—the place you hold information while you’re
working on it. Some of the information was then transferred into long-term memory, a much larger and more
permanent storage place (Atkinson & Shiffrin, 1968; Broadbent, 1958; Waugh
& Norman, 1965).
This early conception of memory
captured some important truths—but needs to be updated in several ways. As one
concern, the idea of “sensory memory” plays a much smaller role in modern
theorizing and so, for example, many discussions of visual infor-mation
processing make no mention of iconic
memory. In addition, modern proposals use the term working memory rather than short-term memory to emphasize the
function of this memory: Ideas or thoughts in this memory are currently
activated, currently being thought about—and so they’re the ideas you are
currently working on. Long-term memory, in contrast, is the
vast depository that contains all of your knowledge and all of your beliefs
that you happen not to be thinking about at the moment, and this includes your
beliefs about relatively recent events. Thus, if just a few minutes ago you
were thinking about your weekend plans but now you’re thinking about something
else, these plans are gone from working memory (because you’re no longer
working on them); and so, if you can recall your plans, you must be drawing
them from long-term memory.
Let’s note, though, that what’s
at stake here is more than a shift in terminology, because the modern view also
differs from the stage theory in how it conceptualizes memory. In the older
view, working memory was understood broadly as a storage place, and it was often described as the “loading dock”
just outside the long-term memory “warehouse.” In the modern conception,
working memory is not a “place” at all; instead, it’s just the name we give to
a status. When we say that ideas are
“in working memory,” this simply means—as we’ve already noted—that these ideas
are currently activated. This focus on status is also the key to understanding
the difference between working memory and long-term memory—the modern conception
emphasizes whether the mental content is currently active (working memory) or
not (long-term memory), in contrast to older theory’s empha-sis on time frame
(“short term” or “long”).
PRIMACY AND RECENCY
Why should we take this broad
proposal seriously? Why should we make any distinc-tion between working memory
and long-term memory, and why should we think about working memory in the way
we’ve just described? As a first step toward answering these questions,
consider the results of studies in which participants hear a series of
unrelated words—perhaps 15 words in total, or 20, presented one word at a time.
At the end of the list, the participants are asked to recall the items in any
order they choose (this is why the participants’ task is called free recall—they’re free to recall the items in any sequence).
In this task, there’s a reliable
pattern for which words the participants recall and which ones they don’t.
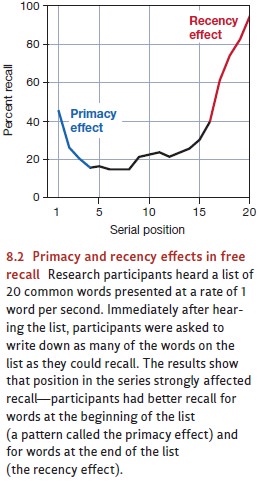
Words presented at the beginning of the list are very likely to be recalled;
this memory advantage for early-presented words is called the primacy effect. Likewise, the last few
words presented are also likely to be recalled; this is the recency effect. The likelihood of
recall is appreciably poorer for words in the middle of the list (Figure 8.2)
What creates this pattern? As the
to-be-remembered words are presented, the participants pay attention to them,
and this ensures the activated status that we call “working memory.” There’s a
limit, however, on how many things someone can think about at once, and so
there’s a limit on how many items can be maintained in working memory.
According to many authors, this limit is seven items, give or take one or two;
the capacity of working memory is therefore said to be seven plus or minus two items (G. Miller, 1956). As a result, it’s
just not possible for the participants to maintain all of the list words in
their current thoughts. Instead, they’ll just do their best to “keep up” with
the list as they hear it. Thus, at each moment during the list presentation,
their working memories will contain only the half-dozen or so words that
arrived most recently.
Notice that, in this situation,
new words entering working memory will “bump out” the words that were there a
moment ago. The only words that don’t get bumped out are the last few words on
the list, because obviously no further input arrives to displace them. Hence,
when the list presentation ends, these few words are still in working memory—
still in the participants’ thoughts—so are easy to recall. This is why the
participants reli-ably remember the end of the list; they are producing the
result we call the recency effect.
The primacy effect comes from a
different source. We know that these early words are not being recalled from
working memory, because they were—as we’ve already noted— bumped from working
memory by later-arriving words. It seems, therefore, that the pri-macy effect
must involve long-term memory—and so, to explain why these early words are so
well recalled, we need to ask how these words became well established in
long-term storage in the first place.
The explanation lies in how
participants allocate their attention during the list presentation. To put this
in concrete terms, let’s say that the first word on the list is camera. When research participants hear
this word, they can focus their full attentionon it, silently rehearsing “camera, camera, camera, . . .” When the
second word arrives, they’ll rehearse that one too; but now they’ll have to
divide their attention between the first word and the second (“camera, boat, camera, boat, . . .”).
Attention will be divided still further after participants hear the third word
(“camera, boat, zebra,camera, boat,
zebra, . . .”), and so on through the list.
Notice that earlier words on the
list get more attention than later ones. At the list’s start, participants can
lavish attention on the few words they’ve heard so far. As they hear more and
more of the list, though, they must divide their attention more thinly, simply
because they have more words to keep track of. Let’s now make one more
assumption: that the extra attention given to the list’s first few words makes
it more likely that these words will be well established in long-term memory.
On this basis, par-ticipants will be more likely to recall these early words
than words in the middle of the list—exactly the pattern of the data.
Support for these interpretations
comes from various manipulations that affect the pri-macy and recency effects.
For example, what happens if we require research participants to do some other
task immediately after hearing the words but before recalling them? This other
task will briefly divert the participants’ attention from rehearsing or
thinking about the list words—and so the words will be bumped out of working
memory. Working mem-ory, in turn, was the hypothesized source of the recency
effect, and so, according to our hypothesis, this other task—even if it lasts
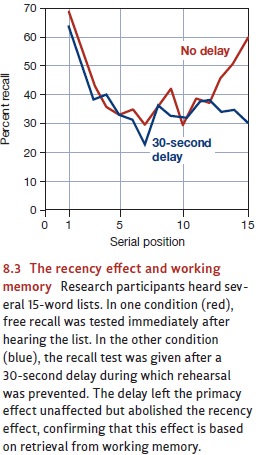
just a few seconds—should disrupt the recency effect. And indeed it does. If
participants are required to count backward for just 30 seconds between hearing
the words and recalling them, the recency effect is eliminated (Figure 8.3).
Other manipulations produce a
different pattern—they alter the primacy effect but have no effect on recency.
For example, if we present the list items more slowly, participants have time
to devote more attention to each word. But we’ve just proposed that attention
helps to establish words in long-term memory. We should therefore expect that a
slower

presentation will lead to a
stronger primacy effect (since primacy depends on retrieval from long-term
memory) but no change in the recency effect (because the recency items aren’t
being retrieved from long-term memory). This is exactly what happens (Figure
8.4).
RECODING TO EXPANDTHECAPACITYOFWORKING MEMORY
As we’ve mentioned, working
memory has a limited capacity. There is, however, enormous flexibility in how
we use that capacity—and so, if we can pack the input more efficiently, we can increase
the amount of information maintained in this memory.
For example, consider an
individual who tries to recall a series of digits that she heard only once:
177620001066
If she treats this as a series of
16 unrelated digits, she’ll surely fail in her attempt to remember the series.
But if she thinks of the digits as years (i.e., the year the U.S. Declaration
of Independence was signed; the year of the new millennium; and the year the
Normans invaded England), the task becomes much easier because now she has just
three items to remember.
Cases like this one make it plain
that working memory’s capacity can’t be measured in digits, or words, or kilobytes. Instead, the capacity is
measured in chunks. This
unscientific-sounding word helps us remember that this is a flexible sort of
measure-ment, because what’s in a chunk depends on how the person thinks about,
and organ-izes, the information. Thus, if a person thinks of each digit as a
chunk, working memory
can hold (roughly) seven digits.
If pairs of digits are chunked
together, working mem-ory’s capacity will be more than a dozen digits.
To see how important chunking can
be, consider a remarkable individual studied by Chase and Ericsson (Chase &
Ericsson, 1978, 1979, 1982; Ericsson, 2003). This fellow happens to be a fan of
track events, and when he hears numbers, he thinks of them as finishing times
for races. The sequence “3, 4, 9, 2,” for example, becomes “3 minutes and 49
point 2 seconds, near world-record mile time.” In this way, four digits become
one chunk of information. The man can then retain seven finishing times (seven
chunks) in memory, and this can involve 20 or 30 digits. Better still, these
chunks can be grouped into larger chunks, and these into even larger ones. For
example, finishing times for individual racers can be chunked together into
heats within a track meet, so that, now, 4 or 5 finishing times (more than 12
digits) become one chunk. With strate-gies like this and with a lot of
practice, this man has increased his apparent memory capacity from the “normal”
7 digits to 79 digits!
Let’s be clear, though, that what
has changed through practice is merely the man’s chunking strategy, not the
holding capacity of working memory itself. This is evident in the fact that,
when tested with sequences of letters rather than numbers—so he can’t use his
chunking strategy—his memory capacity drops to a perfectly normal six
conso-nants. Thus, the seven-chunk limit is still in place for this fellow,
even though (with numbers) he’s able to make extraordinary use of these seven
slots.
Related Topics