Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Identifying Opportunities for Parallelism
Using a Pipeline of Tasks to Work on a Single Item
Using
a Pipeline of Tasks to Work on a Single Item
A
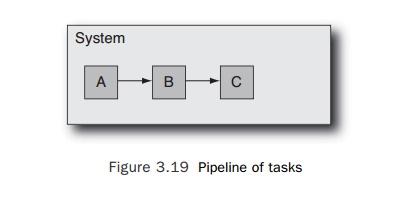
pipeline of tasks is perhaps a less obvious strategy for parallelization. Here,
a single unit of work is split into multiple stages and is passed from one
stage to the next rather like an assembly line.
Figure
3.19 represents this situation. A system has three separate threads; when a
unit of work comes in, the first thread completes task A and passes the work on
to task B, which is performed by the second thread. The work is completed by
the third thread performing task C. As each thread completes its task, it is
ready to accept new work.
There are
various motivations for using a pipeline approach. A pipeline has some amount
of flexibility, in that the flow of work can be dynamically changed at runtime.
It also has some implicit scalability because an implementation could use
multiple copies of a particular time-consuming stage in the pipeline (combining
the pipeline pattern with the multiple copies of a single task pattern),
although the basic pipeline model would have a single copy of each stage.
This
pattern is most critical in situations where it represents the most effective
way the problem can be scaled to multiple threads. Consider a situation where
packets come in for processing, are processed, and then are retransmitted. A
single thread can cope only with a certain limit of packets per second. More threads
are needed in order to improve perform-ance. One way of doing this would be to
increase the number of threads doing the receiv-ing, processing, and
forwarding. However, that might introduce additional complexity in keeping the
packets in the same order and synchronizing the multiple processing threads.
In this
situation, a pipeline looks attractive because each stage can be working on a
separate packet, which means that the performance gain is proportional to the
number of active threads. The way to view this is to assume that the original
processing of a packet took three seconds. So, every three seconds a new packet
could be dealt with. When the processing is split into three equal pipeline
stages, each stage will take a sec-ond. More specifically, task A will take one
second before it passes the packet of work on to task B, and this will leave
the first thread able to take on a new packet of work. So, every second there
will be a packet starting processing. A three-stage pipeline has improved
performance by a factor of three. The issues of ordering and synchronization
can be dealt with by placing the items in a queue between the stages so that
order is maintained.
Notice
that the pipeline does not reduce the time taken to process each unit of work.
In fact, the queuing steps may slightly increase it. So, once again, it is a
throughput improvement rather than a reduction in unit processing time.
One
disadvantage to pipelines is that the rate that new work can go through the
pipeline is limited by the time that it takes for the work of the slowest stage
in the pipeline to complete. As an example, consider the case where task B
takes two seconds. The second thread can accept work only every other second,
so regardless of how much faster tasks A and C are to complete, task B limits
the throughput of the pipeline to one task every two seconds. Of course, it
might be possible to rectify this bottleneck by having two threads performing
task B. Here the combination would complete one task every second, which would
match the throughput of tasks A and C. It is also worth consider-ing that the
best throughput occurs when all the stages in the pipeline take the same amount
of time. Otherwise, some stages will be idle waiting for more work.
Related Topics