Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hardware, Processes, and Threads
Using Caches to Hold Recently Used Data
Using
Caches to Hold Recently Used Data
When a
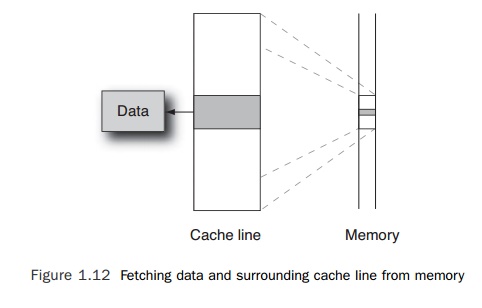
processor requests a set of bytes from memory, it does not get only those bytes
that it needs. When the data is fetched from memory, it is fetched together
with the sur-rounding bytes as a cache
line, as shown in Figure 1.12. Depending on the processor in a system, a
cache line might be as small as 16 bytes, or it could be as large as 128 (or
more) bytes. A typical value for cache line size is 64 bytes. Cache lines are
always aligned, so a 64-byte cache line will start at an address that is a multiple
of 64. This design decision simplifies the system because it enables the system
to be optimized to pass around aligned data of this size; the alternative is a
more complex memory interface that would have to handle chunks of memory of
different sizes and differently aligned start addresses.
When a
line of data is fetched from memory, it is stored in a cache. Caches improve performance because the processor is very
likely to either reuse the data or access data stored on the same cache line.
There are usually caches for instructions and caches for data. There may also
be multiple levels of cache.
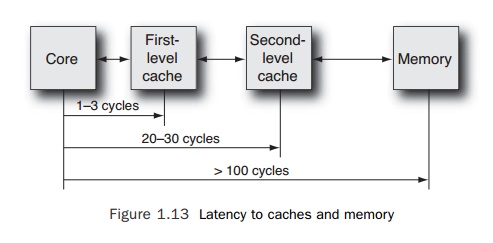
The
reason for having multiple levels of cache is that the larger the size of the
cache, the longer it takes to determine whether an item of data is held in that
cache. A proces-sor might have a small first-level cache that it can access
within a few clock cycles and then a second-level cache that is much larger but
takes tens of cycles to access. Both of these are significantly faster than memory,
which might take hundreds of cycles to access. The time it takes to fetch an
item of data from memory or from a level of cache is referred to as its latency. Figure 1.13 shows a typical
memory hierarchy.
The
greater the latency of accesses to main memory, the more benefit there is from
multiple layers of cache. Some systems even benefit from having a third-level
cache.
Caches
have two very obvious characteristics: the size of the cache lines and the size
of the cache. The number of lines in a cache can be calculated by dividing one
by the other. For example, a 4KB cache that has a cache line size of 64 bytes
will hold 64 lines.
Caches
have other characteristics, which are less obviously visible and have less of a
directly measurable impact on application performance. The one characteristic
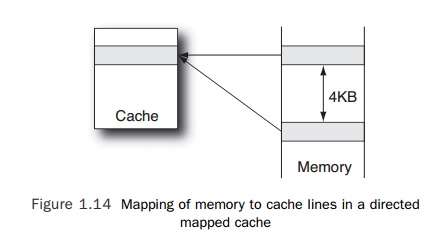
that it is worth mentioning is the associativity. In a simple cache, each cache
line in memory would map to exactly one position in the cache; this is called a
direct mapped cache. If we take the
simple 4KB cache outlined earlier, then the cache line located at every 4KB
interval in memory would map to the same line in the cache, as shown in Figure
1.14.
Obviously,
a program that accessed memory in 4KB strides would end up just using a single
entry in the cache and could suffer from poor performance if it needed to
simul-taneously use multiple cache lines.
The way
around this problem is to increase the associativity
of the cache—that is, make it possible for a single cache line to map into more
positions in the cache and therefore reduce the possibility of there being a
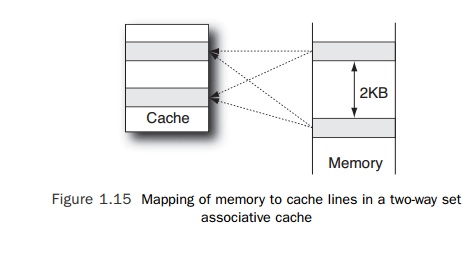
conflict in the cache. In a two-way associative
cache, each
cache line can map into one of two locations. The location is chosen accord-ing
to some replacement policy that could be random replacement, or it could depend
on which of the two locations contains the oldest data (least recently used
replacement). Doubling the number of potential locations for each cache line
means that the interval between lines in memory that map onto the same cache
line is halved, but overall this change will result in more effective
utilization of the cache and a reduction in the num-ber of cache misses. Figure
1.15 shows the change.
A fully associative cache is one where any
address in memory can map to any line in the cache. Although this represents
the approach that is likely to result in the lowest cache miss rate, it is also
the most complex approach to implement; hence, it is infrequently implemented.
On
systems where multiple threads share a level of cache, it becomes more
important for the cache to have higher associativity. To see why this is the
case, imagine that two copies of the same application share a common
direct-mapped cache. If each of them accesses the same virtual memory address,
then they will both be attempting to use the same line in the cache, and only
one will succeed. Unfortunately, this success will be short-lived because the
other copy will immediately replace this line of data with the line of data
that they need.
Related Topics