Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hardware, Processes, and Threads
Increasing Instruction Issue Rate with Pipelined Processor Cores
Increasing
Instruction Issue Rate with Pipelined Processor Cores
As we
previously discussed, the core of a
processor is the part of the processor responsible for executing instructions.
Early processors would execute a single instruction every cycle, so a processor
that ran at 4MHz could execute 4 million instructions every second. The logic
to execute a single instruction could be quite complex, so the time it takes to
execute the longest instruction determined how long a cycle had to take and
therefore defined the maximum clock speed for the processor.
To
improve this situation, processor designs became “pipelined.” The operations
nec-essary to complete a single instruction were broken down into multiple
smaller steps. This was the simplest pipeline:
n Fetch. Fetch the next instruction from
memory.
n Decode. Determine what type of
instruction it is.
n Execute. Do the appropriate work.
n Retire. Make the state changes from the
instruction visible to the rest of the system.
Assuming
that the overall time it takes for an instruction to complete remains the same,
each of the four steps takes one-quarter of the original time. However, once an
instruction has completed the Fetch step, the next instruction can enter that
stage. This means that four instructions can be in execution at the same time.
The clock rate, which determines when an instruction completes a pipeline
stage, can now be four times faster than it was. It now takes four clock cycles
for an instruction to complete execution. This means that each instruction
takes the same wall time to complete its execution. But there are now four
instructions progressing through the processor pipeline, so the pipelined
processor can execute instructions at four times the rate of the nonpipelined
processor.
For
example, Figure 1.9 shows the integer and floating-point pipelines from the
UltraSPARC T2 processor. The integer pipeline has eight stages, and the
floating-point pipeline has twelve stages.
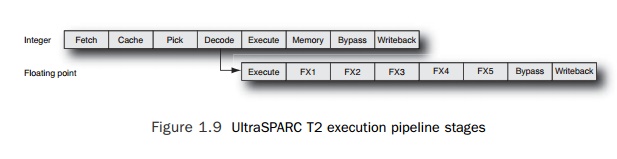
The names
given to the various stages are not of great importance, but several aspects of
the pipeline are worthy of discussion. Four pipeline stages are performed
regardless of whether the instruction is floating point or integer. Only at the
Execute stage of the pipeline does the path diverge for the two instruction
types.
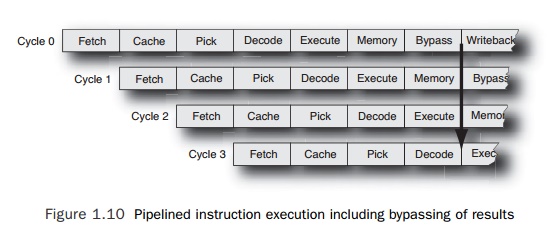
For all
instructions, the result of the operation can be made available to any
subse-quent instructions at the Bypass stage. The subsequent instruction needs
the data at the Execute stage, so if the first instruction starts executing at
cycle zero, a dependent instruction can start in cycle 3 and expect the data to
be available by the time it is needed. This is shown in Figure 1.10 for integer
instructions. An instruction that is fetched in cycle 0 will produce a result
that can be bypassed to a following instruction seven cycles later when it
reaches the Bypass stage. The dependent instruction would need this result as
input when it reaches the Execute stage. If an instruction is fetched every
cycle, then the fourth instruction will have reached the Execute stage by the
time the first instruction has reached the Bypass stage.
The
downside of long pipelines is correcting execution in the event of an error;
the most common example of this is mispredicted branches.
To keep
fetching instructions, the processor needs to guess the next instruction that
will be executed. Most of the time this will be the instruction at the
following address in memory. However, a branch instruction might change the
address where the instruction is to be fetched from—but the processor will know
this only once all the conditions that the branch depends on have been resolved
and once the actual branch instruction has been executed.
The usual
approach to dealing with this is to predict whether branches are taken and then
to start fetching instructions from the predicted address. If the processor
predicts correctly, then there is no interruption to the instruction steam—and
no cost to the branch. If the processor predicts incorrectly, all the
instructions executed after the branch need to be flushed, and the correct
instruction stream needs to be fetched from memory. These are called branch mispredictions, and their cost is
proportional to the length of the pipeline. The longer the pipeline, the longer
it takes to get the correct instructions through the pipeline in the event of a
mispredicted branch.
Pipelining
enabled higher clock speeds for processors, but they were still executing only
a single instruction every cycle. The next improvement was “super-scalar
execution,” which means the ability to execute multiple instructions per cycle.
The Intel Pentium was the first x86 processor that could execute multiple
instructions on the same cycle; it had two pipelines, each of which could
execute an instruction every cycle. Having two pipelines potentially doubled
performance over the previous generation.
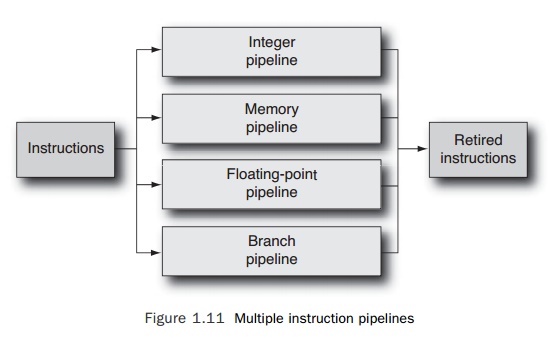
More
recent processors have four or more pipelines. Each pipeline is specialized to handle
a particular type of instruction. It is typical to have a memory pipeline that
han-dles loads and stores, an integer pipeline that handles integer
computations (integer addi-tion, shifts, comparison, and so on), a
floating-point pipeline (to handle floating-point computation), and a branch
pipeline (for branch or call instructions). Schematically, this would look
something like Figure 1.11.
The
UltraSPARC T2 discussed earlier has four pipelines for each core: two for
inte-ger operations, one for memory operations, and one for floating-point
operations. These four pipelines are shared between two groups of four threads,
and every cycle one thread from both of the groups can issue an instruction.
Related Topics