Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hardware, Processes, and Threads
Supporting Multiple Threads on a Single Chip
Supporting
Multiple Threads on a Single Chip
The core
of a processor is the part of the chip responsible for executing instructions.
The core has many parts, and we will discuss some of those parts in detail
later in this chapter. A simplified schematic of a processor might look like Figure
1.3.
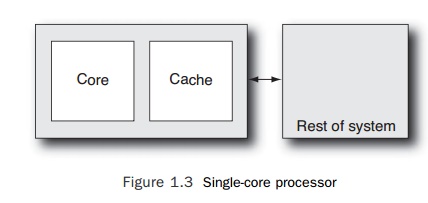
Cache is
an area of memory on the chip that holds recently used data and instructions.
When you look at the piece of silicon inside a processor, such as that shown in
Figure 1.7, the core and the cache are the two components that are identifiable
to the eye. We will discuss cache in the “Caches” section later in this
chapter.
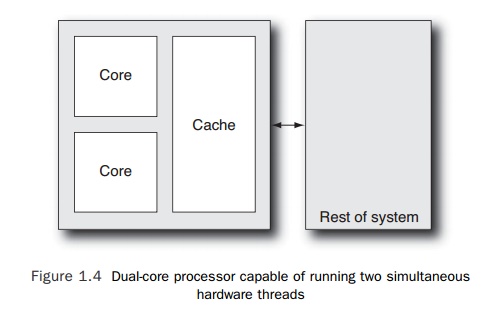
The
simplest way of enabling a chip to run multiple threads is to duplicate the
core multiple times, as shown in Figure 1.4. The earliest processors capable of
supporting mul-tiple threads relied on this approach. This is the fundamental
idea of multicore proces-sors. It is an easy approach because it takes an
existing processor design and replicates it. There are some complications
involved in making the two cores communicate with each other and with the
system, but the changes to the core (which is the most complex part of the
processor) are minimal. The two cores share an interface to the rest of the
system, which means that system access must be shared between the two cores.
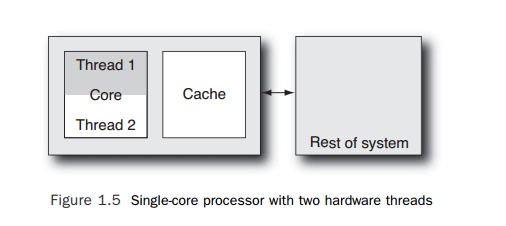
However,
this is not the only approach. An alternative is to make a single core execute
multiple threads of instructions, as shown in Figure 1.5. There are various
refinements on this design:
The core
could execute instructions from one software thread for 100 cycles and then
switch to another thread for the next 100.
The core
could alternate every cycle between fetching an instruction from one thread and
fetching an instruction from the other thread.
The core
could simultaneously fetch an instruction from each of multiple threads every
cycle.
The core
could switch software threads every time the stream that is currently executing
hits a long latency event (such as a cache miss, where the data has to be fetched
from memory).
With two
threads sharing a core, each thread will get a share of the resources. The size
of the share will depend on the activity of the other thread and the number of
resources available. For example, if one thread is stalled waiting on memory,
then the other thread may have exclusive access to all the resources of the
core. However, if both threads want to simultaneously issue the same type of
instruction, then for some processors only one thread will be successful, and
the other thread will have to retry on the next opportunity.
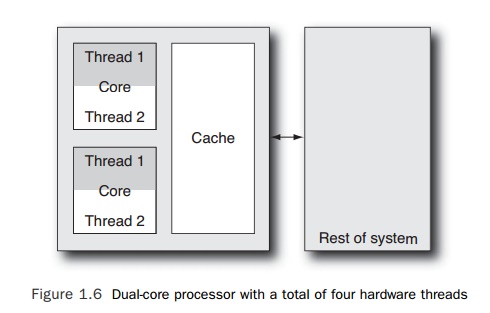
Most
multicore processors use a combination of multiple cores and multiple threads
per core. The simplest example of this would be a processor with two cores with
each core being capable of supporting two threads, making a total of four
threads for the entire processor. Figure 1.6 shows this configuration.
When this
ability to handle multiple threads is exposed to the operating system, it
usually appears that the system has many virtual CPUs. Therefore, from the
perspective of the user, the system is capable of running multiple threads. One
term used to describe this is chip
multithreading (CMT)—one chip, many threads. This term places the emphasis
on the fact that there are many threads, without stressing about the
implementation details of how threads are assigned to cores.
The
UltraSPARC T2 is a good example of a CMT processor. It has eight replicated
cores, and each core is capable of running eight threads, making the processor
capable of running 64 software threads simultaneously. Figure 1.7 shows the
physical layout of the processor.

The
UltraSPARC T2 floor plan has a number of different areas that offer support
functionality to the cores of the processor; these are mainly located around
the outside edge of the chip. The eight processor cores are readily
identifiable because of their struc-tural similarity. For example, SPARC Core 2
is the vertical reflection of SPARC Core 0, which is the horizontal reflection
of SPARC Core 4. The other obvious structure is the crosshatch pattern that is
caused by the regular structure elements that form the second-level cache area;
this is an area of on-chip memory that is shared between all the cores. This
memory holds recently used data and makes it less likely that data will have to
be fetched from memory; it also enables data to be quickly shared between
cores.
It is
important to realize that the implementation details of CMT processors do have
detectable effects, particularly when multiple threads are distributed over the
system. But the hardware threads can usually be considered as all being equal.
In current processor designs, there are not fast hardware threads and slow
hardware threads; the performance of a thread depends on what else is currently
executing on the system, not on some invariant property of the design.
For
example, suppose the CPU in a system has two cores, and each core can support
two threads. When two threads are running on that system, either they can be on
the same core or they can be on different cores. It is probable that when the
threads share a core, they run slower than if they were scheduled on different
cores. This is an obvious result of having to share resources in one instance
and not having to share resources in the other.
Fortunately,
operating systems are evolving to include concepts of locality of memory and
sharing of processor resources so that they can automatically assign work in
the best possible way. An example of this is the locality group information used by the Solaris oper-ating system to
schedule work to processors. This information tells the operating system which
virtual processors share resources. Best performance will probably be attained
by scheduling work to virtual processors that do not share resources.
The other
situation where it is useful for the operating system to understand the
topology of the system is when a thread wakes up and is unable to be scheduled
to exactly the same virtual CPU that was running it earlier. Then the thread
can be sched-uled to a virtual CPU that shares the same locality group. This is
less of a disturbance than running it on a virtual processor that shares
nothing with the original virtual processor. For example, Linux has the concept
of affinity, which keeps threads
local to where they were previously executing.
This kind
of topological information becomes even more important in systems where there
are multiple processors, with each processor capable of supporting multiple
threads. The difference in performance between scheduling a thread on any of
the cores of a sin-gle processor may be slight, but the difference in
performance when a thread is migrated to a different processor can be
significant, particularly if the data it is using is held in memory that is
local to the original processor. Memory affinity will be discussed further in
the section “The Characteristics of Multiprocessor Systems.”
In the
following sections, we will discuss the components of the processor core. A
rough schematic of the critical parts of a processor core might look like
Figure 1.8. This
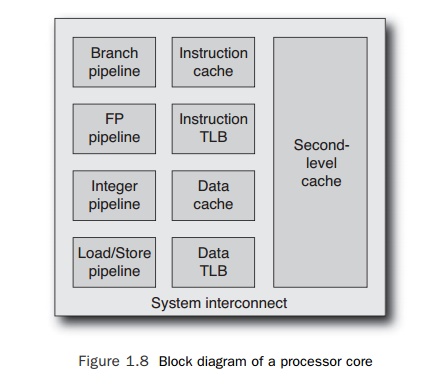
shows the
specialized pipelines for each instruction type, the on-chip memory (called cache), the translation look-aside
buffers (TLBs) that are used for converting virtual mem-ory addresses to
physical, and the system interconnect (which is the layer that is responsi-ble
for communicating with the rest of the system).
The next
section, “Increasing Instruction Issue Rate with Pipelined Processor Cores,”
explains the motivation for the various “pipelines” that are found in the cores
of modern processors. Sections “Using Caches to Hold Recently Used Data,”
“Using Virtual Memory to Store Data,” and “Translating from Virtual Addresses
to Physical Addresses” in this chapter cover the purpose and functionality of
the caches and TLBs.
Related Topics